 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enabling CMF Estimation in Data-Constrained Scenarios: A Semantic-Encoding Knowledge Mining Model
Nov 15, 2023
Precise estimation of Crash Modification Factors (CMFs) is central to evaluating the effectiveness of various road safety treatments and prioritizing infrastructure investment accordingly. While customized study for each countermeasure scenario is desired, the conventional CMF estimation approaches rely heavily on the availability of crash data at given sites. This not only makes the estimation costly, but the results are also less transferable, since the intrinsic similarities between different safety countermeasure scenarios are not fully explored. Aiming to fill this gap, this study introduces a novel knowledge-mining framework for CMF prediction. This framework delves into the connections of existing countermeasures and reduces the reliance of CMF estimation on crash data availability and manual data collection. Specifically, it draws inspiration from human comprehension processes and introduces advanced Natural Language Processing (NLP) techniques to extract intricate variations and patterns from existing CMF knowledge. It effectively encodes unstructured countermeasure scenarios into machine-readable representations and models the complex relationships between scenarios and CMF values. This new data-driven framework provides a cost-effective and adaptable solution that complements the case-specific approaches for CMF estimation, which is particularly beneficial when availability of crash data or time imposes constraints. Experimental validation using real-world CMF Clearinghouse data demonstrates the effectiveness of this new approach, which shows significant accuracy improvements compared to baseline methods. This approach provides insights into new possibilities of harnessing accumulated transportation knowledge in various applications.
Learning Physics-Inspired Regularization for Medical Image Registration with Hypernetworks
Nov 14, 2023Medical image registration aims at identifying the spatial deformation between images of the same anatomical region and is fundamental to image-based diagnostics and therapy. To date, the majority of the deep learning-based registration methods employ regularizers that enforce global spatial smoothness, e.g., the diffusion regularizer. However, such regularizers are not tailored to the data and might not be capable of reflecting the complex underlying deformation. In contrast, physics-inspired regularizers promote physically plausible deformations. One such regularizer is the linear elastic regularizer which models the deformation of elastic material. These regularizers are driven by parameters that define the material's physical properties. For biological tissue, a wide range of estimations of such parameters can be found in the literature and it remains an open challenge to identify suitable parameter values for successful registration. To overcome this problem and to incorporate physical properties into learning-based registration, we propose to use a hypernetwork that learns the effect of the physical parameters of a physics-inspired regularizer on the resulting spatial deformation field. In particular, we adapt the HyperMorph framework to learn the effect of the two elasticity parameters of the linear elastic regularizer. Our approach enables the efficient discovery of suitable, data-specific physical parameters at test time.
MeLo: Low-rank Adaptation is Better than Fine-tuning for Medical Image Diagnosis
Nov 14, 2023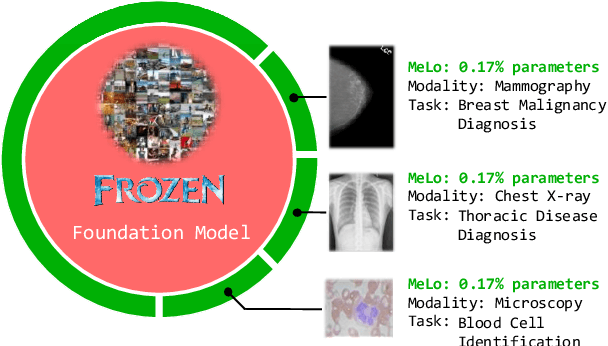

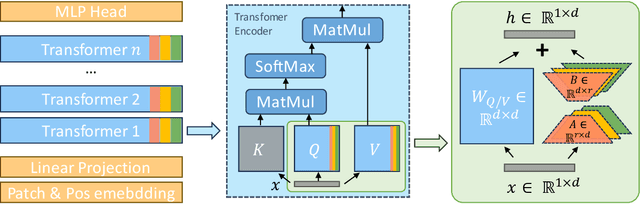

The common practice in developing computer-aided diagnosis (CAD) models based on transformer architectures usually involves fine-tuning from ImageNet pre-trained weights. However, with recent advances in large-scale pre-training and the practice of scaling laws, Vision Transformers (ViT) have become much larger and less accessible to medical imaging communities. Additionally, in real-world scenarios, the deployments of multiple CAD models can be troublesome due to problems such as limited storage space and time-consuming model switching. To address these challenges, we propose a new method MeLo (Medical image Low-rank adaptation), which enables the development of a single CAD model for multiple clinical tasks in a lightweight manner. It adopts low-rank adaptation instead of resource-demanding fine-tuning. By fixing the weight of ViT models and only adding small low-rank plug-ins, we achieve competitive results on various diagnosis tasks across different imaging modalities using only a few trainable parameters. Specifically, our proposed method achieves comparable performance to fully fine-tuned ViT models on four distinct medical imaging datasets using about 0.17% trainable parameters. Moreover, MeLo adds only about 0.5MB of storage space and allows for extremely fast model switching in deployment and inference. Our source code and pre-trained weights are available on our website (https://absterzhu.github.io/melo.github.io/).
A Deep Learning Based Resource Allocator for Communication Systems with Dynamic User Utility Demands
Nov 08, 2023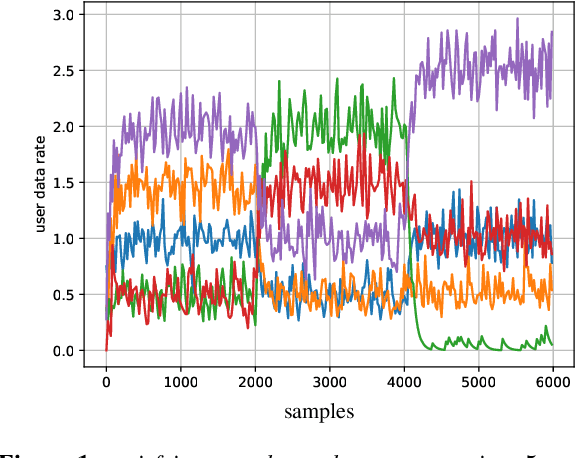
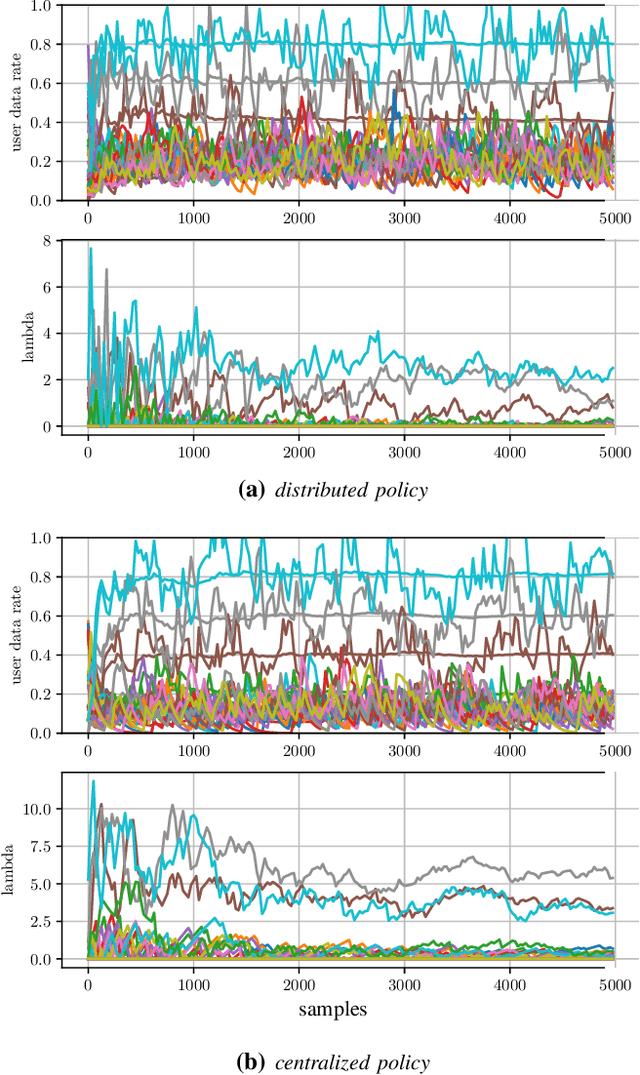
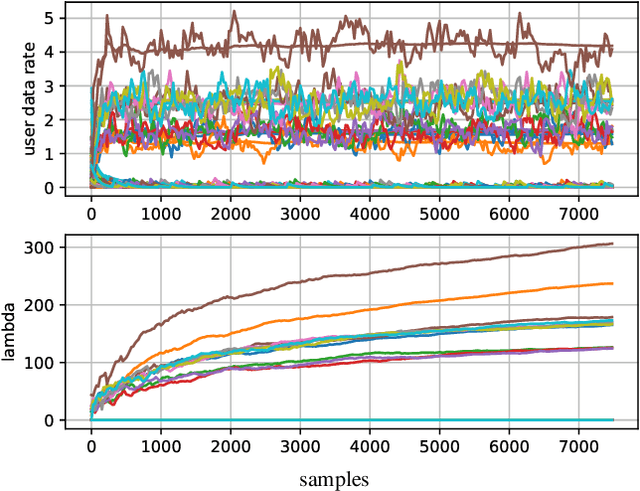
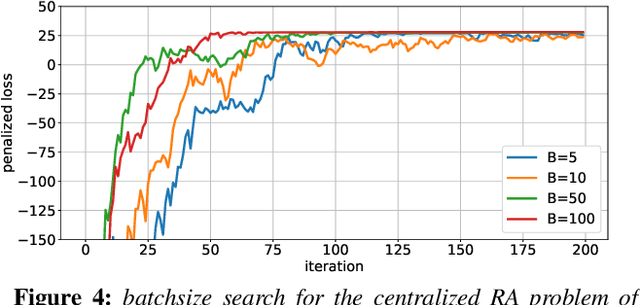
Deep learning (DL) based resource allocation (RA) has recently gained a lot of attention due to its performance efficiency. However, most of the related studies assume an ideal case where the number of users and their utility demands, e.g., data rate constraints, are fixed and the designed DL based RA scheme exploits a policy trained only for these fixed parameters. A computationally complex policy retraining is required whenever these parameters change. Therefore, in this paper, a DL based resource allocator (ALCOR) is introduced, which allows users to freely adjust their utility demands based on, e.g., their application layer. ALCOR employs deep neural networks (DNNs), as the policy, in an iterative optimization algorithm. The optimization algorithm aims to optimize the on-off status of users in a time-sharing problem to satisfy their utility demands in expectation. The policy performs unconstrained RA (URA) -- RA without taking into account user utility demands -- among active users to maximize the sum utility (SU) at each time instant. Based on the chosen URA scheme, ALCOR can perform RA in a model-based or model-free manner and in a centralized or distributed scenario. Derived convergence analyses provide guarantees for the convergence of ALCOR, and numerical experiments corroborate its effectiveness.
The voraus-AD Dataset for Anomaly Detection in Robot Applications
Nov 08, 2023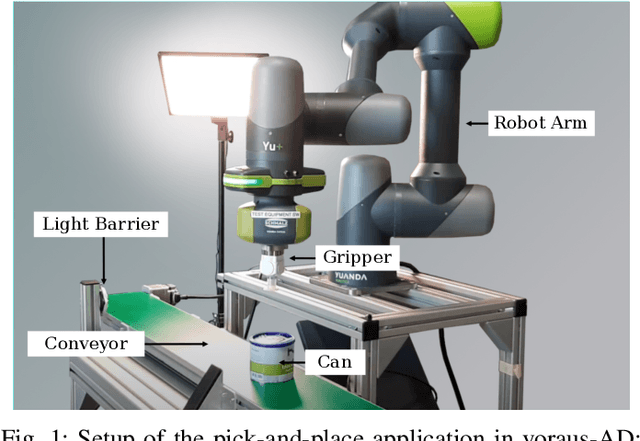
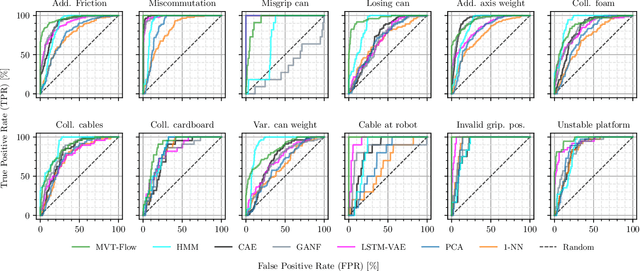
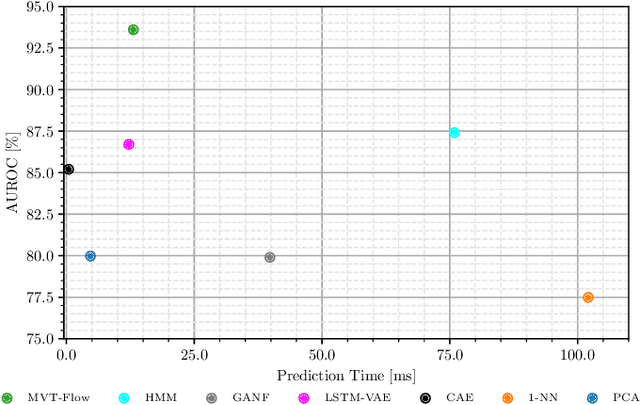
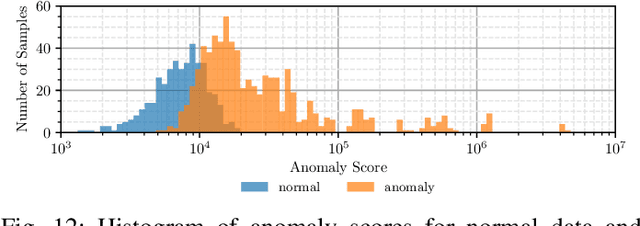
During the operation of industrial robots, unusual events may endanger the safety of humans and the quality of production. When collecting data to detect such cases, it is not ensured that data from all potentially occurring errors is included as unforeseeable events may happen over time. Therefore, anomaly detection (AD) delivers a practical solution, using only normal data to learn to detect unusual events. We introduce a dataset that allows training and benchmarking of anomaly detection methods for robotic applications based on machine data which will be made publicly available to the research community. As a typical robot task the dataset includes a pick-and-place application which involves movement, actions of the end effector and interactions with the objects of the environment. Since several of the contained anomalies are not task-specific but general, evaluations on our dataset are transferable to other robotics applications as well. Additionally, we present MVT-Flow (multivariate time-series flow) as a new baseline method for anomaly detection: It relies on deep-learning-based density estimation with normalizing flows, tailored to the data domain by taking its structure into account for the architecture. Our evaluation shows that MVT-Flow outperforms baselines from previous work by a large margin of 6.2% in area under ROC.
DeliverAI: Reinforcement Learning Based Distributed Path-Sharing Network for Food Deliveries
Nov 03, 2023Delivery of items from the producer to the consumer has experienced significant growth over the past decade and has been greatly fueled by the recent pandemic. Amazon Fresh, Shopify, UberEats, InstaCart, and DoorDash are rapidly growing and are sharing the same business model of consumer items or food delivery. Existing food delivery methods are sub-optimal because each delivery is individually optimized to go directly from the producer to the consumer via the shortest time path. We observe a significant scope for reducing the costs associated with completing deliveries under the current model. We model our food delivery problem as a multi-objective optimization, where consumer satisfaction and delivery costs, both, need to be optimized. Taking inspiration from the success of ride-sharing in the taxi industry, we propose DeliverAI - a reinforcement learning-based path-sharing algorithm. Unlike previous attempts for path-sharing, DeliverAI can provide real-time, time-efficient decision-making using a Reinforcement learning-enabled agent system. Our novel agent interaction scheme leverages path-sharing among deliveries to reduce the total distance traveled while keeping the delivery completion time under check. We generate and test our methodology vigorously on a simulation setup using real data from the city of Chicago. Our results show that DeliverAI can reduce the delivery fleet size by 12\%, the distance traveled by 13%, and achieve 50% higher fleet utilization compared to the baselines.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.
Understanding Practices around Computational News Discovery Tools in the Domain of Science Journalism
Nov 12, 2023Science and technology journalists today face challenges in finding newsworthy leads due to increased workloads, reduced resources, and expanding scientific publishing ecosystems. Given this context, we explore computational methods to aid these journalists' news discovery in terms of time-efficiency and agency. In particular, we prototyped three computational information subsidies into an interactive tool that we used as a probe to better understand how such a tool may offer utility or more broadly shape the practices of professional science journalists. Our findings highlight central considerations around science journalists' agency, context, and responsibilities that such tools can influence and could account for in design. Based on this, we suggest design opportunities for greater and longer-term user agency; incorporating contextual, personal and collaborative notions of newsworthiness; and leveraging flexible interfaces and generative models. Overall, our findings contribute a richer view of the sociotechnical system around computational news discovery tools, and suggest ways to improve such tools to better support the practices of science journalists.
WinNet:time series forecasting with a window-enhanced period extracting and interacting
Nov 01, 2023Recently, Transformer-based methods have significantly improved state-of-the-art time series forecasting results, but they suffer from high computational costs and the inability to capture the long and short periodicity of time series. We present a highly accurate and simply structured CNN-based model for long-term time series forecasting tasks, called WinNet, including (i) Inter-Intra Period Encoder (I2PE) to transform 1D sequence into 2D tensor with long and short periodicity according to the predefined periodic window, (ii) Two-Dimensional Period Decomposition (TDPD) to model period-trend and oscillation terms, and (iii) Decomposition Correlation Block (DCB) to leverage the correlations of the period-trend and oscillation terms to support the prediction tasks by CNNs. Results on nine benchmark datasets show that the WinNet can achieve SOTA performance and lower computational complexity over CNN-, MLP-, Transformer-based approaches. The WinNet provides potential for the CNN-based methods in the time series forecasting tasks, with perfect tradeoff between performance and efficiency.
Tackling Concept Shift in Text Classification using Entailment-style Modeling
Nov 06, 2023
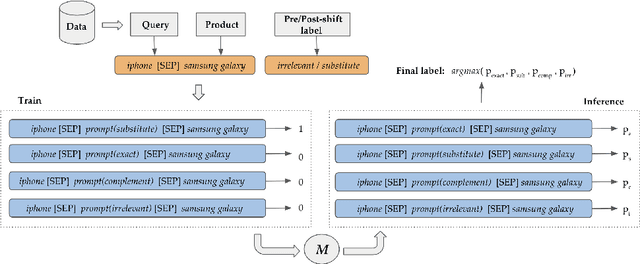
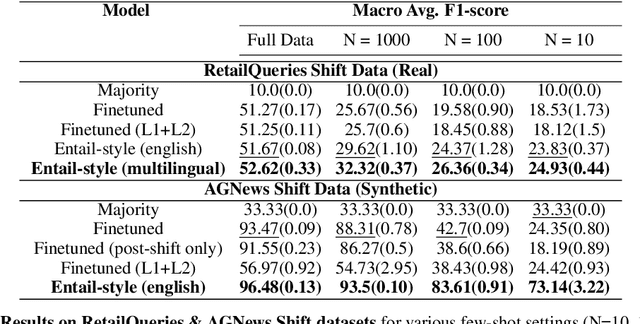
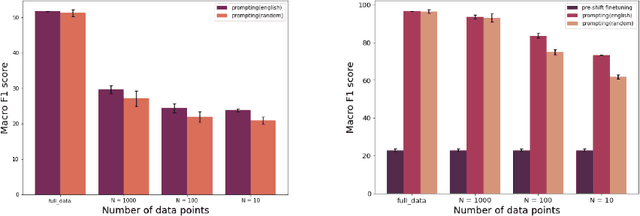
Pre-trained language models (PLMs) have seen tremendous success in text classification (TC) problems in the context of Natural Language Processing (NLP). In many real-world text classification tasks, the class definitions being learned do not remain constant but rather change with time - this is known as Concept Shift. Most techniques for handling concept shift rely on retraining the old classifiers with the newly labelled data. However, given the amount of training data required to fine-tune large DL models for the new concepts, the associated labelling costs can be prohibitively expensive and time consuming. In this work, we propose a reformulation, converting vanilla classification into an entailment-style problem that requires significantly less data to re-train the text classifier to adapt to new concepts. We demonstrate the effectiveness of our proposed method on both real world & synthetic datasets achieving absolute F1 gains upto 7% and 40% respectively in few-shot settings. Further, upon deployment, our solution also helped save 75% of labeling costs overall.