 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
Nov 14, 2023
Enhancing the instruction-following ability of Large Language Models (LLMs) primarily demands substantial instruction-tuning datasets. However, the sheer volume of these imposes a considerable computational burden and annotation cost. To investigate a label-efficient instruction tuning method that allows the model itself to actively sample subsets that are equally or even more effective, we introduce a self-evolving mechanism DiverseEvol. In this process, a model iteratively augments its training subset to refine its own performance, without requiring any intervention from humans or more advanced LLMs. The key to our data sampling technique lies in the enhancement of diversity in the chosen subsets, as the model selects new data points most distinct from any existing ones according to its current embedding space. Extensive experiments across three datasets and benchmarks demonstrate the effectiveness of DiverseEvol. Our models, trained on less than 8% of the original dataset, maintain or improve performance compared with finetuning on full data. We also provide empirical evidence to analyze the importance of diversity in instruction data and the iterative scheme as opposed to one-time sampling. Our code is publicly available at https://github.com/OFA-Sys/DiverseEvol.git.
Visual Servoing NMPC Applied to UAVs for Photovoltaic Array Inspection
Nov 14, 2023The photovoltaic (PV) industry is seeing a significant shift toward large-scale solar plants, where traditional inspection methods have proven to be time-consuming and costly. Currently, the predominant approach to PV inspection using unmanned aerial vehicles (UAVs) is based on photogrammetry. However, the photogrammetry approach presents limitations, such as an increased amount of useless data during flights, potential issues related to image resolution, and the detection process during high-altitude flights. In this work, we develop a visual servoing control system applied to a UAV with dynamic compensation using a nonlinear model predictive control (NMPC) capable of accurately tracking the middle of the underlying PV array at different frontal velocities and height constraints, ensuring the acquisition of detailed images during low-altitude flights. The visual servoing controller is based on the extraction of features using RGB-D images and the Kalman filter to estimate the edges of the PV arrays. Furthermore, this work demonstrates the proposal in both simulated and real-world environments using the commercial aerial vehicle (DJI Matrice 100), with the purpose of showcasing the results of the architecture. Our approach is available for the scientific community in: https://github.com/EPVelasco/VisualServoing_NMPC
Two-Stage Predict+Optimize for Mixed Integer Linear Programs with Unknown Parameters in Constraints
Nov 14, 2023Consider the setting of constrained optimization, with some parameters unknown at solving time and requiring prediction from relevant features. Predict+Optimize is a recent framework for end-to-end training supervised learning models for such predictions, incorporating information about the optimization problem in the training process in order to yield better predictions in terms of the quality of the predicted solution under the true parameters. Almost all prior works have focused on the special case where the unknowns appear only in the optimization objective and not the constraints. Hu et al.~proposed the first adaptation of Predict+Optimize to handle unknowns appearing in constraints, but the framework has somewhat ad-hoc elements, and they provided a training algorithm only for covering and packing linear programs. In this work, we give a new \emph{simpler} and \emph{more powerful} framework called \emph{Two-Stage Predict+Optimize}, which we believe should be the canonical framework for the Predict+Optimize setting. We also give a training algorithm usable for all mixed integer linear programs, vastly generalizing the applicability of the framework. Experimental results demonstrate the superior prediction performance of our training framework over all classical and state-of-the-art methods.
DiLoCo: Distributed Low-Communication Training of Language Models
Nov 14, 2023Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected accelerators, with devices exchanging gradients and other intermediate states at each optimization step. While it is difficult to build and maintain a single computing cluster hosting many accelerators, it might be easier to find several computing clusters each hosting a smaller number of devices. In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less. DiLoCo exhibits great robustness to the data distribution of each worker. It is also robust to resources becoming unavailable over time, and vice versa, it can seamlessly leverage resources that become available during training.
A Simple and Powerful Framework for Stable Dynamic Network Embedding
Nov 14, 2023In this paper, we address the problem of dynamic network embedding, that is, representing the nodes of a dynamic network as evolving vectors within a low-dimensional space. While the field of static network embedding is wide and established, the field of dynamic network embedding is comparatively in its infancy. We propose that a wide class of established static network embedding methods can be used to produce interpretable and powerful dynamic network embeddings when they are applied to the dilated unfolded adjacency matrix. We provide a theoretical guarantee that, regardless of embedding dimension, these unfolded methods will produce stable embeddings, meaning that nodes with identical latent behaviour will be exchangeable, regardless of their position in time or space. We additionally define a hypothesis testing framework which can be used to evaluate the quality of a dynamic network embedding by testing for planted structure in simulated networks. Using this, we demonstrate that, even in trivial cases, unstable methods are often either conservative or encode incorrect structure. In contrast, we demonstrate that our suite of stable unfolded methods are not only more interpretable but also more powerful in comparison to their unstable counterparts.
ExpM+NF: Differentially Private Machine Learning that Surpasses DPSGD
Nov 15, 2023In this pioneering work we formulate ExpM+NF, a method for training machine learning (ML) on private data with pre-specified differentially privacy guarantee $\varepsilon>0, \delta=0$, by using the Exponential Mechanism (ExpM) and an auxiliary Normalizing Flow (NF). We articulate theoretical benefits of ExpM+NF over Differentially Private Stochastic Gradient Descent (DPSGD), the state-of-the-art (SOTA) and de facto method for differentially private ML, and we empirically test ExpM+NF against DPSGD using the SOTA implementation (Opacus with PRV accounting) in multiple classification tasks on the Adult Dataset (census data) and MIMIC-III Dataset (electronic healthcare records) using Logistic Regression and GRU-D, a deep learning recurrent neural network with ~20K-100K parameters. In all experiments, ExpM+NF achieves greater than 93% of the non-private training accuracy (AUC) for $\varepsilon \in [1\mathrm{e}{-3}, 1]$, exhibiting greater accuracy (higher AUC) and privacy (lower $\varepsilon$ with $\delta=0$) than DPSGD. Differentially private ML generally considers $\varepsilon \in [1,10]$ to maintain reasonable accuracy; hence, ExpM+NF's ability to provide strong accuracy for orders of magnitude better privacy (smaller $\varepsilon$) substantially pushes what is currently possible in differentially private ML. Training time results are presented showing ExpM+NF is comparable to (slightly faster) than DPSGD. Code for these experiments will be provided after review. Limitations and future directions are provided.
Aerial IRS with Robotic Anchoring Capabilities: A Novel Way for Adaptive Coverage Enhancement
Nov 15, 2023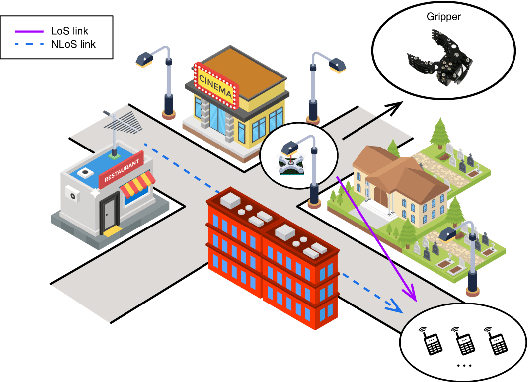
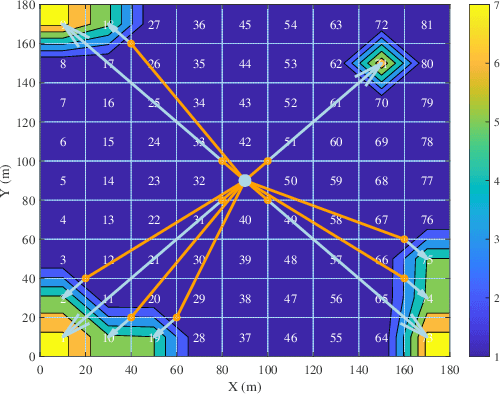
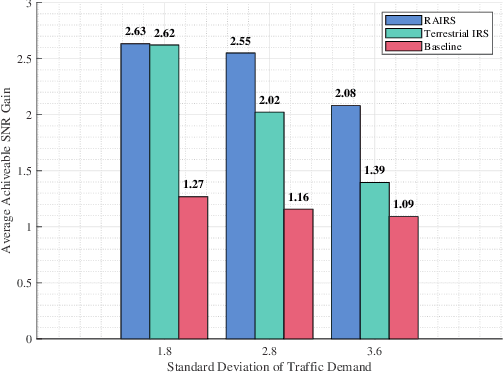
It is widely accepted that integrating intelligent reflecting surfaces (IRSs) with unmanned aerial vehicles (UAV) or drones can assist wireless networks in improving network coverage and end user Quality of Service (QoS). However, the critical constrain of drones is their very limited hovering/flying time. In this paper we propose the concept of robotic aerial IRSs (RA-IRSs), which are in essence drones that in addition to IRS embed an anchoring mechanism that allows them to grasp in an energy neutral manner at tall urban landforms such as lampposts. By doing so, RA-IRSs can completely eliminate the flying/hovering energy consumption and can offer service for multiple hours or even days (something not possible with UAV-mounted IRSs). Using that property we show how RA-IRS can increase network performance by changing their anchoring location to follow the spatio-temporal traffic demand. The proposed methodology, developed through Integer Linear Programming (ILP) formulations offers a significant Signal-to-Noise (SNR) gain in highly heterogeneous regions in terms of traffic demand compared to fixed IRS; hence, addressing urban coverage discrepancies effectively. Numerical simulations validate the superiority of RA-IRSs over fixed terrestrial IRSs in terms of traffic serviceability, sustaining more than 2 times the traffic demand in areas experiencing high heterogeneity, emphasizing their adaptability in improving coverage and QoS in complex urban terrains.
Incremental Object-Based Novelty Detection with Feedback Loop
Nov 15, 2023Object-based Novelty Detection (ND) aims to identify unknown objects that do not belong to classes seen during training by an object detection model. The task is particularly crucial in real-world applications, as it allows to avoid potentially harmful behaviours, e.g. as in the case of object detection models adopted in a self-driving car or in an autonomous robot. Traditional approaches to ND focus on one time offline post processing of the pretrained object detection output, leaving no possibility to improve the model robustness after training and discarding the abundant amount of out-of-distribution data encountered during deployment. In this work, we propose a novel framework for object-based ND, assuming that human feedback can be requested on the predicted output and later incorporated to refine the ND model without negatively affecting the main object detection performance. This refinement operation is repeated whenever new feedback is available. To tackle this new formulation of the problem for object detection, we propose a lightweight ND module attached on top of a pre-trained object detection model, which is incrementally updated through a feedback loop. We also propose a new benchmark to evaluate methods on this new setting and test extensively our ND approach against baselines, showing increased robustness and a successful incorporation of the received feedback.
Fast Certification of Vision-Language Models Using Incremental Randomized Smoothing
Nov 15, 2023A key benefit of deep vision-language models such as CLIP is that they enable zero-shot open vocabulary classification; the user has the ability to define novel class labels via natural language prompts at inference time. However, while CLIP-based zero-shot classifiers have demonstrated competitive performance across a range of domain shifts, they remain highly vulnerable to adversarial attacks. Therefore, ensuring the robustness of such models is crucial for their reliable deployment in the wild. In this work, we introduce Open Vocabulary Certification (OVC), a fast certification method designed for open-vocabulary models like CLIP via randomized smoothing techniques. Given a base "training" set of prompts and their corresponding certified CLIP classifiers, OVC relies on the observation that a classifier with a novel prompt can be viewed as a perturbed version of nearby classifiers in the base training set. Therefore, OVC can rapidly certify the novel classifier using a variation of incremental randomized smoothing. By using a caching trick, we achieve approximately two orders of magnitude acceleration in the certification process for novel prompts. To achieve further (heuristic) speedups, OVC approximates the embedding space at a given input using a multivariate normal distribution bypassing the need for sampling via forward passes through the vision backbone. We demonstrate the effectiveness of OVC on through experimental evaluation using multiple vision-language backbones on the CIFAR-10 and ImageNet test datasets.
DEED: Dynamic Early Exit on Decoder for Accelerating Encoder-Decoder Transformer Models
Nov 15, 2023Encoder-decoder transformer models have achieved great success on various vision-language (VL) tasks, but they suffer from high inference latency. Typically, the decoder takes up most of the latency because of the auto-regressive decoding. To accelerate the inference, we propose an approach of performing Dynamic Early Exit on Decoder (DEED). We build a multi-exit encoder-decoder transformer model which is trained with deep supervision so that each of its decoder layers is capable of generating plausible predictions. In addition, we leverage simple yet practical techniques, including shared generation head and adaptation modules, to keep accuracy when exiting at shallow decoder layers. Based on the multi-exit model, we perform step-level dynamic early exit during inference, where the model may decide to use fewer decoder layers based on its confidence of the current layer at each individual decoding step. Considering different number of decoder layers may be used at different decoding steps, we compute deeper-layer decoder features of previous decoding steps just-in-time, which ensures the features from different decoding steps are semantically aligned. We evaluate our approach with two state-of-the-art encoder-decoder transformer models on various VL tasks. We show our approach can reduce overall inference latency by 30%-60% with comparable or even higher accuracy compared to baselines.