 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video Anomaly Detection using GAN
Nov 23, 2023
Accounting for the increased concern for public safety, automatic abnormal event detection and recognition in a surveillance scene is crucial. It is a current open study subject because of its intricacy and utility. The identification of aberrant events automatically, it's a difficult undertaking because everyone's idea of abnormality is different. A typical occurrence in one circumstance could be seen as aberrant in another. Automatic anomaly identification becomes particularly challenging in the surveillance footage with a large crowd due to congestion and high occlusion. With the use of machine learning techniques, this thesis study aims to offer the solution for this use case so that human resources won't be required to keep an eye out for any unusual activity in the surveillance system records. We have developed a novel generative adversarial network (GAN) based anomaly detection model. This model is trained such that it learns together about constructing a high dimensional picture space and determining the latent space from the video's context. The generator uses a residual Autoencoder architecture made up of a multi-stage channel attention-based decoder and a two-stream, deep convolutional encoder that can realise both spatial and temporal data. We have also offered a technique for refining the GAN model that reduces training time while also generalising the model by utilising transfer learning between datasets. Using a variety of assessment measures, we compare our model to the current state-of-the-art techniques on four benchmark datasets. The empirical findings indicate that, in comparison to existing techniques, our network performs favourably on all datasets.
Lego: Learning to Disentangle and Invert Concepts Beyond Object Appearance in Text-to-Image Diffusion Models
Nov 23, 2023Diffusion models have revolutionized generative content creation and text-to-image (T2I) diffusion models in particular have increased the creative freedom of users by allowing scene synthesis using natural language. T2I models excel at synthesizing concepts such as nouns, appearances, and styles. To enable customized content creation based on a few example images of a concept, methods such as Textual Inversion and DreamBooth invert the desired concept and enable synthesizing it in new scenes. However, inverting more general concepts that go beyond object appearance and style (adjectives and verbs) through natural language, remains a challenge. Two key characteristics of these concepts contribute to the limitations of current inversion methods. 1) Adjectives and verbs are entangled with nouns (subject) and can hinder appearance-based inversion methods, where the subject appearance leaks into the concept embedding and 2) describing such concepts often extends beyond single word embeddings (being frozen in ice, walking on a tightrope, etc.) that current methods do not handle. In this study, we introduce Lego, a textual inversion method designed to invert subject entangled concepts from a few example images. Lego disentangles concepts from their associated subjects using a simple yet effective Subject Separation step and employs a Context Loss that guides the inversion of single/multi-embedding concepts. In a thorough user study, Lego-generated concepts were preferred over 70% of the time when compared to the baseline. Additionally, visual question answering using a large language model suggested Lego-generated concepts are better aligned with the text description of the concept.
FinMe: A Performance-Enhanced Large Language Model Trading Agent with Layered Memory and Character Design
Nov 23, 2023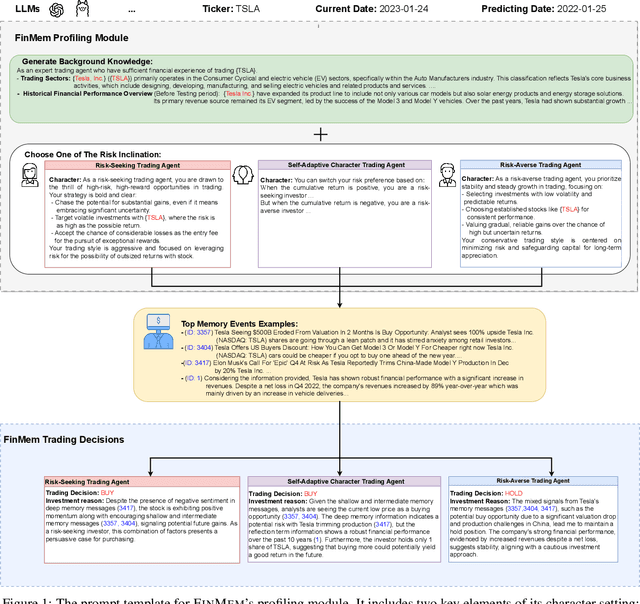
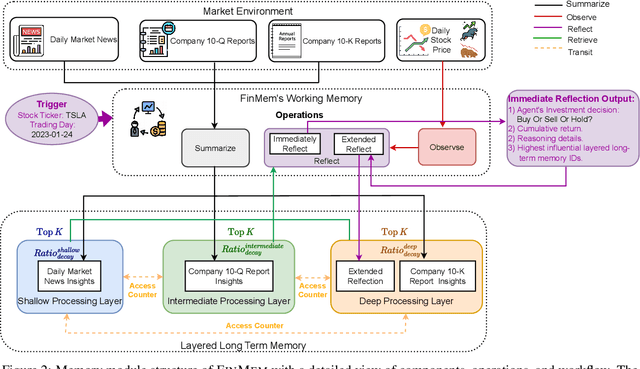
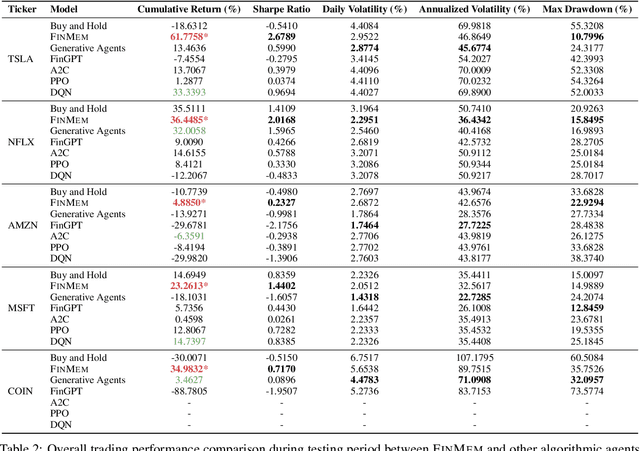

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMe}, a novel LLM-based agent framework devised for financial decision-making, encompassing three core modules: Profiling, to outline the agent's characteristics; Memory, with layered processing, to aid the agent in assimilating realistic hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMe}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMe} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks and funds. We then fine-tuned the agent's perceptual spans to achieve a significant trading performance. Collectively, \textsc{FinMe} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Span-Based Optimal Sample Complexity for Average Reward MDPs
Nov 22, 2023We study the sample complexity of learning an $\varepsilon$-optimal policy in an average-reward Markov decision process (MDP) under a generative model. We establish the complexity bound $\widetilde{O}\left(SA\frac{H}{\varepsilon^2} \right)$, where $H$ is the span of the bias function of the optimal policy and $SA$ is the cardinality of the state-action space. Our result is the first that is minimax optimal (up to log factors) in all parameters $S,A,H$ and $\varepsilon$, improving on existing work that either assumes uniformly bounded mixing times for all policies or has suboptimal dependence on the parameters. Our result is based on reducing the average-reward MDP to a discounted MDP. To establish the optimality of this reduction, we develop improved bounds for $\gamma$-discounted MDPs, showing that $\widetilde{O}\left(SA\frac{H}{(1-\gamma)^2\varepsilon^2} \right)$ samples suffice to learn a $\varepsilon$-optimal policy in weakly communicating MDPs under the regime that $\gamma \geq 1 - \frac{1}{H}$, circumventing the well-known lower bound of $\widetilde{\Omega}\left(SA\frac{1}{(1-\gamma)^3\varepsilon^2} \right)$ for general $\gamma$-discounted MDPs. Our analysis develops upper bounds on certain instance-dependent variance parameters in terms of the span parameter. These bounds are tighter than those based on the mixing time or diameter of the MDP and may be of broader use.
REDS: Resource-Efficient Deep Subnetworks for Dynamic Resource Constraints
Nov 22, 2023Deep models deployed on edge devices frequently encounter resource variability, which arises from fluctuating energy levels, timing constraints, or prioritization of other critical tasks within the system. State-of-the-art machine learning pipelines generate resource-agnostic models, not capable to adapt at runtime. In this work we introduce Resource-Efficient Deep Subnetworks (REDS) to tackle model adaptation to variable resources. In contrast to the state-of-the-art, REDS use structured sparsity constructively by exploiting permutation invariance of neurons, which allows for hardware-specific optimizations. Specifically, REDS achieve computational efficiency by (1) skipping sequential computational blocks identified by a novel iterative knapsack optimizer, and (2) leveraging simple math to re-arrange the order of operations in REDS computational graph to take advantage of the data cache. REDS support conventional deep networks frequently deployed on the edge and provide computational benefits even for small and simple networks. We evaluate REDS on six benchmark architectures trained on the Google Speech Commands, FMNIST and CIFAR10 datasets, and test on four off-the-shelf mobile and embedded hardware platforms. We provide a theoretical result and empirical evidence for REDS outstanding performance in terms of submodels' test set accuracy, and demonstrate an adaptation time in response to dynamic resource constraints of under 40$\mu$s, utilizing a 2-layer fully-connected network on Arduino Nano 33 BLE Sense.
Iris Presentation Attack: Assessing the Impact of Combining Vanadium Dioxide Films with Artificial Eyes
Nov 21, 2023Iris recognition systems, operating in the near infrared spectrum (NIR), have demonstrated vulnerability to presentation attacks, where an adversary uses artifacts such as cosmetic contact lenses, artificial eyes or printed iris images in order to circumvent the system. At the same time, a number of effective presentation attack detection (PAD) methods have been developed. These methods have demonstrated success in detecting artificial eyes (e.g., fake Van Dyke eyes) as presentation attacks. In this work, we seek to alter the optical characteristics of artificial eyes by affixing Vanadium Dioxide (VO2) films on their surface in various spatial configurations. VO2 films can be used to selectively transmit NIR light and can, therefore, be used to regulate the amount of NIR light from the object that is captured by the iris sensor. We study the impact of such images produced by the sensor on two state-of-the-art iris PA detection methods. We observe that the addition of VO2 films on the surface of artificial eyes can cause the PA detection methods to misclassify them as bonafide eyes in some cases. This represents a vulnerability that must be systematically analyzed and effectively addressed.
A Data-Free Approach to Mitigate Catastrophic Forgetting in Federated Class Incremental Learning for Vision Tasks
Nov 21, 2023Deep learning models often suffer from forgetting previously learned information when trained on new data. This problem is exacerbated in federated learning (FL), where the data is distributed and can change independently for each user. Many solutions are proposed to resolve this catastrophic forgetting in a centralized setting. However, they do not apply directly to FL because of its unique complexities, such as privacy concerns and resource limitations. To overcome these challenges, this paper presents a framework for $\textbf{federated class incremental learning}$ that utilizes a generative model to synthesize samples from past distributions. This data can be later exploited alongside the training data to mitigate catastrophic forgetting. To preserve privacy, the generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Moreover, our solution does not demand the users to store old data or models, which gives them the freedom to join/leave the training at any time. Additionally, we introduce SuperImageNet, a new regrouping of the ImageNet dataset specifically tailored for federated continual learning. We demonstrate significant improvements compared to existing baselines through extensive experiments on multiple datasets.
Self-Supervised Music Source Separation Using Vector-Quantized Source Category Estimates
Nov 21, 2023Music source separation is focused on extracting distinct sonic elements from composite tracks. Historically, many methods have been grounded in supervised learning, necessitating labeled data, which is occasionally constrained in its diversity. More recent methods have delved into N-shot techniques that utilize one or more audio samples to aid in the separation. However, a challenge with some of these methods is the necessity for an audio query during inference, making them less suited for genres with varied timbres and effects. This paper offers a proof-of-concept for a self-supervised music source separation system that eliminates the need for audio queries at inference time. In the training phase, while it adopts a query-based approach, we introduce a modification by substituting the continuous embedding of query audios with Vector Quantized (VQ) representations. Trained end-to-end with up to N classes as determined by the VQ's codebook size, the model seeks to effectively categorise instrument classes. During inference, the input is partitioned into N sources, with some potentially left unutilized based on the mix's instrument makeup. This methodology suggests an alternative avenue for considering source separation across diverse music genres. We provide examples and additional results online.
Attention Deficit is Ordered! Fooling Deformable Vision Transformers with Collaborative Adversarial Patches
Nov 21, 2023The latest generation of transformer-based vision models have proven to be superior to Convolutional Neural Network (CNN)-based models across several vision tasks, largely attributed to their remarkable prowess in relation modeling. Deformable vision transformers significantly reduce the quadratic complexity of modeling attention by using sparse attention structures, enabling them to be used in larger scale applications such as multi-view vision systems. Recent work demonstrated adversarial attacks against transformers; we show that these attacks do not transfer to deformable transformers due to their sparse attention structure. Specifically, attention in deformable transformers is modeled using pointers to the most relevant other tokens. In this work, we contribute for the first time adversarial attacks that manipulate the attention of deformable transformers, distracting them to focus on irrelevant parts of the image. We also develop new collaborative attacks where a source patch manipulates attention to point to a target patch that adversarially attacks the system. In our experiments, we find that only 1% patched area of the input field can lead to 0% AP. We also show that the attacks provide substantial versatility to support different attacker scenarios because of their ability to redirect attention under the attacker control.
ResMGCN: Residual Message Graph Convolution Network for Fast Biomedical Interactions Discovering
Nov 13, 2023Biomedical information graphs are crucial for interaction discovering of biomedical information in modern age, such as identification of multifarious molecular interactions and drug discovery, which attracts increasing interests in biomedicine, bioinformatics, and human healthcare communities. Nowadays, more and more graph neural networks have been proposed to learn the entities of biomedical information and precisely reveal biomedical molecule interactions with state-of-the-art results. These methods remedy the fading of features from a far distance but suffer from remedying such problem at the expensive cost of redundant memory and time. In our paper, we propose a novel Residual Message Graph Convolution Network (ResMGCN) for fast and precise biomedical interaction prediction in a different idea. Specifically, instead of enhancing the message from far nodes, ResMGCN aggregates lower-order information with the next round higher information to guide the node update to obtain a more meaningful node representation. ResMGCN is able to perceive and preserve various messages from the previous layer and high-order information in the current layer with least memory and time cost to obtain informative representations of biomedical entities. We conduct experiments on four biomedical interaction network datasets, including protein-protein, drug-drug, drug-target, and gene-disease interactions, which demonstrates that ResMGCN outperforms previous state-of-the-art models while achieving superb effectiveness on both storage and time.