 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Space-Time Attention with Shifted Non-Local Search
Sep 28, 2023
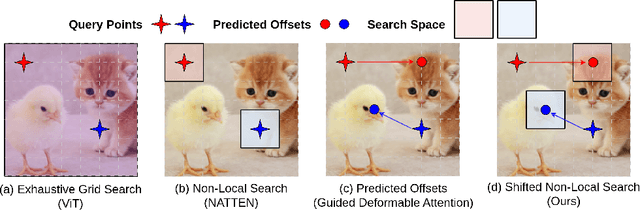
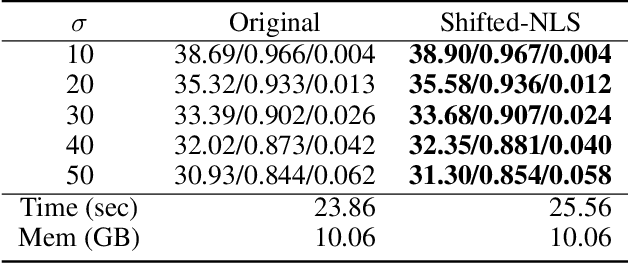


Efficiently computing attention maps for videos is challenging due to the motion of objects between frames. While a standard non-local search is high-quality for a window surrounding each query point, the window's small size cannot accommodate motion. Methods for long-range motion use an auxiliary network to predict the most similar key coordinates as offsets from each query location. However, accurately predicting this flow field of offsets remains challenging, even for large-scale networks. Small spatial inaccuracies significantly impact the attention module's quality. This paper proposes a search strategy that combines the quality of a non-local search with the range of predicted offsets. The method, named Shifted Non-Local Search, executes a small grid search surrounding the predicted offsets to correct small spatial errors. Our method's in-place computation consumes 10 times less memory and is over 3 times faster than previous work. Experimentally, correcting the small spatial errors improves the video frame alignment quality by over 3 dB PSNR. Our search upgrades existing space-time attention modules, which improves video denoising results by 0.30 dB PSNR for a 7.5% increase in overall runtime. We integrate our space-time attention module into a UNet-like architecture to achieve state-of-the-art results on video denoising.
UAV Formation Optimization for Communication-assisted InSAR Sensing
Nov 12, 2023Interferometric synthetic aperture radar (InSAR) is an increasingly important remote sensing technique that enables three-dimensional (3D) sensing applications such as the generation of accurate digital elevation models (DEMs). In this paper, we investigate the joint formation and communication resource allocation optimization for a system comprising two unmanned aerial vehicles (UAVs) to perform InSAR sensing and to transfer the acquired data to the ground. To this end, we adopt as sensing performance metrics the interferometric coherence, i.e., the local correlation between the two co-registered UAV radar images, and the height of ambiguity (HoA), which together are a measure for the accuracy with which the InSAR system can estimate the height of ground objects. In addition, an analytical expression for the coverage of the considered InSAR sensing system is derived. Our objective is to maximize the InSAR coverage while satisfying all relevant InSAR-specific sensing and communication performance metrics. To tackle the non-convexity of the formulated optimization problem, we employ alternating optimization (AO) techniques combined with successive convex approximation (SCA). Our simulation results reveal that the resulting resource allocation algorithm outperforms two benchmark schemes in terms of InSAR coverage while satisfying all sensing and real-time communication requirements. Furthermore, we highlight the importance of efficient communication resource allocation in facilitating real-time sensing and unveil the trade-off between InSAR height estimation accuracy and coverage.
RAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information
Nov 09, 2023As the IT industry advances, system log data becomes increasingly crucial. Many computer systems rely on log texts for management due to restricted access to source code. The need for log anomaly detection is growing, especially in real-world applications, but identifying anomalies in rapidly accumulating logs remains a challenging task. Traditional deep learning-based anomaly detection models require dataset-specific training, leading to corresponding delays. Notably, most methods only focus on sequence-level log information, which makes the detection of subtle anomalies harder, and often involve inference processes that are difficult to utilize in real-time. We introduce RAPID, a model that capitalizes on the inherent features of log data to enable anomaly detection without training delays, ensuring real-time capability. RAPID treats logs as natural language, extracting representations using pre-trained language models. Given that logs can be categorized based on system context, we implement a retrieval-based technique to contrast test logs with the most similar normal logs. This strategy not only obviates the need for log-specific training but also adeptly incorporates token-level information, ensuring refined and robust detection, particularly for unseen logs. We also propose the core set technique, which can reduce the computational cost needed for comparison. Experimental results show that even without training on log data, RAPID demonstrates competitive performance compared to prior models and achieves the best performance on certain datasets. Through various research questions, we verified its capability for real-time detection without delay.
General Policies, Subgoal Structure, and Planning Width
Nov 09, 2023It has been observed that many classical planning domains with atomic goals can be solved by means of a simple polynomial exploration procedure, called IW, that runs in time exponential in the problem width, which in these cases is bounded and small. Yet, while the notion of width has become part of state-of-the-art planning algorithms such as BFWS, there is no good explanation for why so many benchmark domains have bounded width when atomic goals are considered. In this work, we address this question by relating bounded width with the existence of general optimal policies that in each planning instance are represented by tuples of atoms of bounded size. We also define the notions of (explicit) serializations and serialized width that have a broader scope as many domains have a bounded serialized width but no bounded width. Such problems are solved non-optimally in polynomial time by a suitable variant of the Serialized IW algorithm. Finally, the language of general policies and the semantics of serializations are combined to yield a simple, meaningful, and expressive language for specifying serializations in compact form in the form of sketches, which can be used for encoding domain control knowledge by hand or for learning it from small examples. Sketches express general problem decompositions in terms of subgoals, and sketches of bounded width express problem decompositions that can be solved in polynomial time.
Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery
Nov 06, 2023In the quest for unveiling novel categories at test time, we confront the inherent limitations of traditional supervised recognition models that are restricted by a predefined category set. While strides have been made in the realms of self-supervised and open-world learning towards test-time category discovery, a crucial yet often overlooked question persists: what exactly delineates a category? In this paper, we conceptualize a category through the lens of optimization, viewing it as an optimal solution to a well-defined problem. Harnessing this unique conceptualization, we propose a novel, efficient and self-supervised method capable of discovering previously unknown categories at test time. A salient feature of our approach is the assignment of minimum length category codes to individual data instances, which encapsulates the implicit category hierarchy prevalent in real-world datasets. This mechanism affords us enhanced control over category granularity, thereby equipping our model to handle fine-grained categories adeptly. Experimental evaluations, bolstered by state-of-the-art benchmark comparisons, testify to the efficacy of our solution in managing unknown categories at test time. Furthermore, we fortify our proposition with a theoretical foundation, providing proof of its optimality. Our code is available at https://github.com/SarahRastegar/InfoSieve.
Variational Temporal IRT: Fast, Accurate, and Explainable Inference of Dynamic Learner Proficiency
Nov 14, 2023Dynamic Item Response Models extend the standard Item Response Theory (IRT) to capture temporal dynamics in learner ability. While these models have the potential to allow instructional systems to actively monitor the evolution of learner proficiency in real time, existing dynamic item response models rely on expensive inference algorithms that scale poorly to massive datasets. In this work, we propose Variational Temporal IRT (VTIRT) for fast and accurate inference of dynamic learner proficiency. VTIRT offers orders of magnitude speedup in inference runtime while still providing accurate inference. Moreover, the proposed algorithm is intrinsically interpretable by virtue of its modular design. When applied to 9 real student datasets, VTIRT consistently yields improvements in predicting future learner performance over other learner proficiency models.
Traffic Video Object Detection using Motion Prior
Nov 16, 2023Traffic videos inherently differ from generic videos in their stationary camera setup, thus providing a strong motion prior where objects often move in a specific direction over a short time interval. Existing works predominantly employ generic video object detection framework for traffic video object detection, which yield certain advantages such as broad applicability and robustness to diverse scenarios. However, they fail to harness the strength of motion prior to enhance detection accuracy. In this work, we propose two innovative methods to exploit the motion prior and boost the performance of both fully-supervised and semi-supervised traffic video object detection. Firstly, we introduce a new self-attention module that leverages the motion prior to guide temporal information integration in the fully-supervised setting. Secondly, we utilise the motion prior to develop a pseudo-labelling mechanism to eliminate noisy pseudo labels for the semi-supervised setting. Both of our motion-prior-centred methods consistently demonstrates superior performance, outperforming existing state-of-the-art approaches by a margin of 2% in terms of mAP.
Digital Socrates: Evaluating LLMs through explanation critiques
Nov 16, 2023While LLMs can provide reasoned explanations along with their answers, the nature and quality of those explanations are still poorly understood. In response, our goal is to define a detailed way of characterizing the explanation capabilities of modern models and to create a nuanced, interpretable explanation evaluation tool that can generate such characterizations automatically, without relying on expensive API calls or human annotations. Our approach is to (a) define the new task of explanation critiquing - identifying and categorizing any main flaw in an explanation and providing suggestions to address the flaw, (b) create a sizeable, human-verified dataset for this task, and (c) train an open-source, automatic critiquing model (called Digital Socrates) using this data. Through quantitative and qualitative analysis, we demonstrate how Digital Socrates is useful for revealing insights about student models by examining their reasoning chains, and how it can provide high-quality, nuanced, automatic evaluation of those model explanations for the first time. Digital Socrates thus fills an important gap in evaluation tools for understanding and improving the explanation behavior of models.
Effective Large Language Model Adaptation for Improved Grounding
Nov 16, 2023Large language models (LLMs) have achieved remarkable advancements in natural language understanding, generation, and manipulation of text-based data. However, one major issue towards their widespread deployment in the real world is that they can generate "hallucinated" answers that are not factual. Towards this end, this paper focuses on improving grounding from a holistic perspective with a novel framework, AGREE, Adaptation of LLMs for GRounding EnhancEment. We start with the design of an iterative test-time adaptation (TTA) capability that takes into account the support information generated in self-grounded responses. To effectively enable this capability, we tune LLMs to ground the claims in their responses to retrieved documents by providing citations. This tuning on top of the pre-trained LLMs requires a small amount of data that needs to be constructed in a particular way to learn the grounding information, for which we introduce a data construction method. Our results show that the tuning-based AGREE framework generates better grounded responses with more accurate citations compared to prompting-based approaches.
Reconstructing Continuous Light Field From Single Coded Image
Nov 16, 2023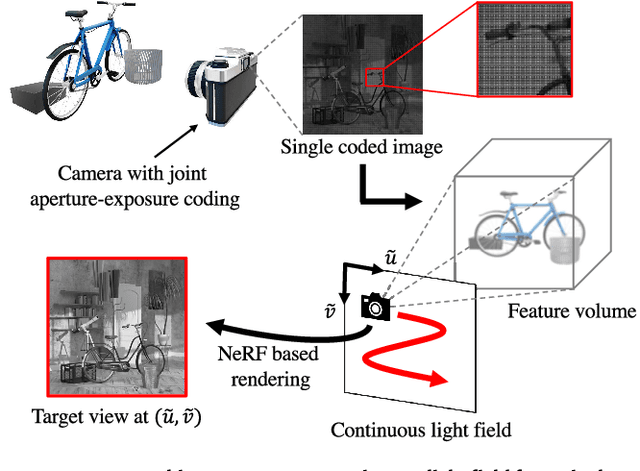

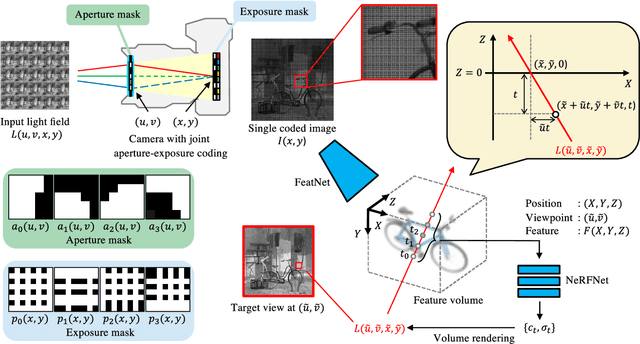

We propose a method for reconstructing a continuous light field of a target scene from a single observed image. Our method takes the best of two worlds: joint aperture-exposure coding for compressive light-field acquisition, and a neural radiance field (NeRF) for view synthesis. Joint aperture-exposure coding implemented in a camera enables effective embedding of 3-D scene information into an observed image, but in previous works, it was used only for reconstructing discretized light-field views. NeRF-based neural rendering enables high quality view synthesis of a 3-D scene from continuous viewpoints, but when only a single image is given as the input, it struggles to achieve satisfactory quality. Our method integrates these two techniques into an efficient and end-to-end trainable pipeline. Trained on a wide variety of scenes, our method can reconstruct continuous light fields accurately and efficiently without any test time optimization. To our knowledge, this is the first work to bridge two worlds: camera design for efficiently acquiring 3-D information and neural rendering.