 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Expandable Machine Learning-Optimization Framework to Sequential Decision-Making
Nov 12, 2023
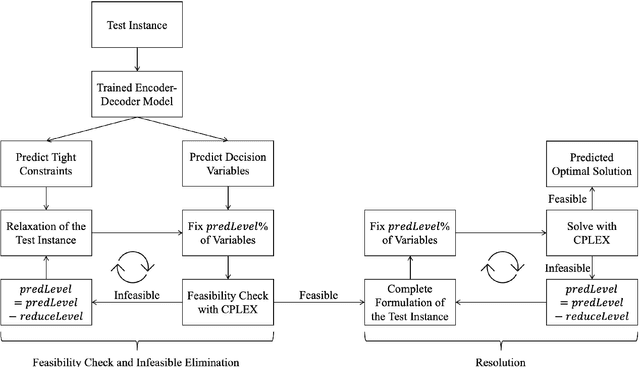
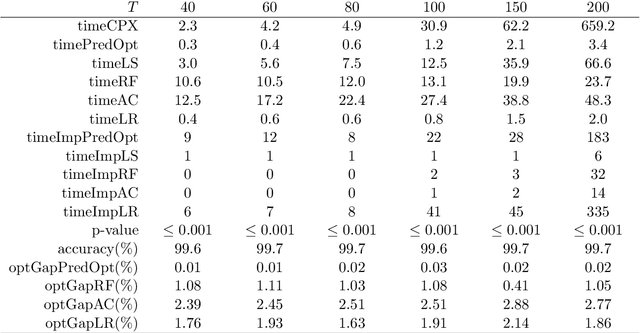
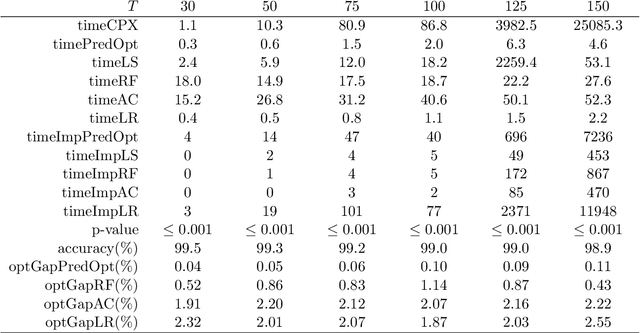
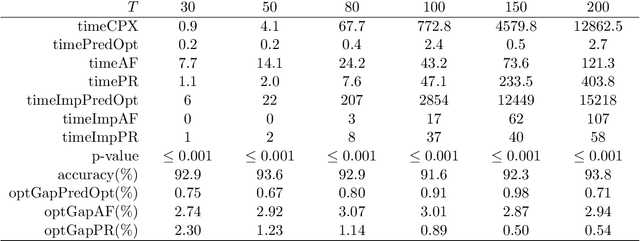
We present an integrated prediction-optimization (PredOpt) framework to efficiently solve sequential decision-making problems by predicting the values of binary decision variables in an optimal solution. We address the key issues of sequential dependence, infeasibility, and generalization in machine learning (ML) to make predictions for optimal solutions to combinatorial problems. The sequential nature of the combinatorial optimization problems considered is captured with recurrent neural networks and a sliding-attention window. We integrate an attention-based encoder-decoder neural network architecture with an infeasibility-elimination and generalization framework to learn high-quality feasible solutions to time-dependent optimization problems. In this framework, the required level of predictions is optimized to eliminate the infeasibility of the ML predictions. These predictions are then fixed in mixed-integer programming (MIP) problems to solve them quickly with the aid of a commercial solver. We demonstrate our approach to tackling the two well-known dynamic NP-Hard optimization problems: multi-item capacitated lot-sizing (MCLSP) and multi-dimensional knapsack (MSMK). Our results show that models trained on shorter and smaller-dimensional instances can be successfully used to predict longer and larger-dimensional problems. The solution time can be reduced by three orders of magnitude with an average optimality gap below 0.1%. We compare PredOpt with various specially designed heuristics and show that our framework outperforms them. PredOpt can be advantageous for solving dynamic MIP problems that need to be solved instantly and repetitively.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023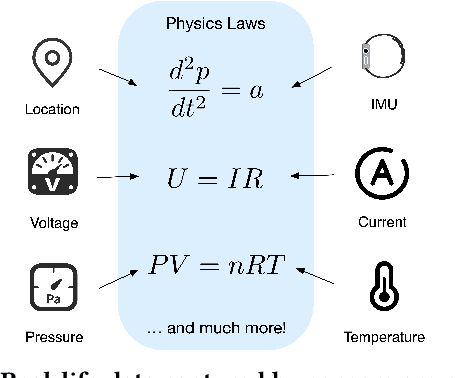
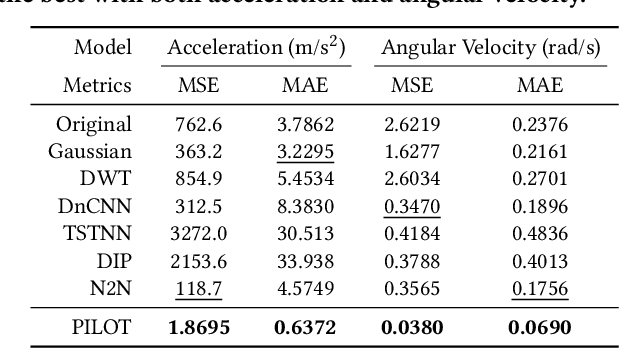
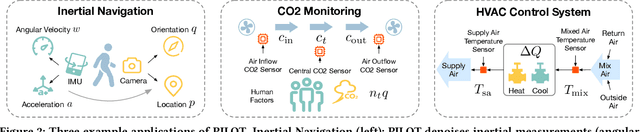

Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Concept Matching: Clustering-based Federated Continual Learning
Nov 12, 2023Federated Continual Learning (FCL) has emerged as a promising paradigm that combines Federated Learning (FL) and Continual Learning (CL). To achieve good model accuracy, FCL needs to tackle catastrophic forgetting due to concept drift over time in CL, and to overcome the potential interference among clients in FL. We propose Concept Matching (CM), a clustering-based framework for FCL to address these challenges. The CM framework groups the client models into concept model clusters, and then builds different global models to capture different concepts in FL over time. In each round, the server sends the global concept models to the clients. To avoid catastrophic forgetting, each client selects the concept model best-matching the concept of the current data for further fine-tuning. To avoid interference among client models with different concepts, the server clusters the models representing the same concept, aggregates the model weights in each cluster, and updates the global concept model with the cluster model of the same concept. Since the server does not know the concepts captured by the aggregated cluster models, we propose a novel server concept matching algorithm that effectively updates a global concept model with a matching cluster model. The CM framework provides flexibility to use different clustering, aggregation, and concept matching algorithms. The evaluation demonstrates that CM outperforms state-of-the-art systems and scales well with the number of clients and the model size.
Transformer-VQ: Linear-Time Transformers via Vector Quantization
Sep 28, 2023We introduce Transformer-VQ, a decoder-only transformer computing softmax-based dense self-attention in linear time. Transformer-VQ's efficient attention is enabled by vector-quantized keys and a novel caching mechanism. In large-scale experiments, Transformer-VQ is shown highly competitive in quality, with strong results on Enwik8 (0.99 bpb), PG-19 (26.6 ppl), and ImageNet64 (3.16 bpb). Code: https://github.com/transformer-vq/transformer_vq
SceneScore: Learning a Cost Function for Object Arrangement
Nov 14, 2023Arranging objects correctly is a key capability for robots which unlocks a wide range of useful tasks. A prerequisite for creating successful arrangements is the ability to evaluate the desirability of a given arrangement. Our method "SceneScore" learns a cost function for arrangements, such that desirable, human-like arrangements have a low cost. We learn the distribution of training arrangements offline using an energy-based model, solely from example images without requiring environment interaction or human supervision. Our model is represented by a graph neural network which learns object-object relations, using graphs constructed from images. Experiments demonstrate that the learned cost function can be used to predict poses for missing objects, generalise to novel objects using semantic features, and can be composed with other cost functions to satisfy constraints at inference time.
Frequentist Guarantees of Distributed (Non)-Bayesian Inference
Nov 14, 2023Motivated by the need to analyze large, decentralized datasets, distributed Bayesian inference has become a critical research area across multiple fields, including statistics, electrical engineering, and economics. This paper establishes Frequentist properties, such as posterior consistency, asymptotic normality, and posterior contraction rates, for the distributed (non-)Bayes Inference problem among agents connected via a communication network. Our results show that, under appropriate assumptions on the communication graph, distributed Bayesian inference retains parametric efficiency while enhancing robustness in uncertainty quantification. We also explore the trade-off between statistical efficiency and communication efficiency by examining how the design and size of the communication graph impact the posterior contraction rate. Furthermore, We extend our analysis to time-varying graphs and apply our results to exponential family models, distributed logistic regression, and decentralized detection models.
First Step Advantage: Importance of Starting Right in Multi-Step Reasoning
Nov 14, 2023Large Language Models (LLMs) can solve complex reasoning tasks by generating rationales for their predictions. Distilling these capabilities into a smaller, compact model can facilitate the creation of specialized, cost-effective models tailored for specific tasks. However, smaller models often face challenges in complex reasoning tasks and often deviate from the correct reasoning path. We show that LLMs can guide smaller models and bring them back to the correct reasoning path only if they intervene at the right time. We show that smaller models fail to reason primarily due to their difficulty in initiating the process, and that guiding them in the right direction can lead to a performance gain of over 100%. We explore different model sizes and evaluate the benefits of providing guidance to improve reasoning in smaller models.
Supervised low-rank semi-nonnegative matrix factorization with frequency regularization for forecasting spatio-temporal data
Nov 15, 2023We propose a novel methodology for forecasting spatio-temporal data using supervised semi-nonnegative matrix factorization (SSNMF) with frequency regularization. Matrix factorization is employed to decompose spatio-temporal data into spatial and temporal components. To improve clarity in the temporal patterns, we introduce a nonnegativity constraint on the time domain along with regularization in the frequency domain. Specifically, regularization in the frequency domain involves selecting features in the frequency space, making an interpretation in the frequency domain more convenient. We propose two methods in the frequency domain: soft and hard regularizations, and provide convergence guarantees to first-order stationary points of the corresponding constrained optimization problem. While our primary motivation stems from geophysical data analysis based on GRACE (Gravity Recovery and Climate Experiment) data, our methodology has the potential for wider application. Consequently, when applying our methodology to GRACE data, we find that the results with the proposed methodology are comparable to previous research in the field of geophysical sciences but offer clearer interpretability.
RIS Position and Orientation Estimation via Multi-Carrier Transmissions and Multiple Receivers
Nov 15, 2023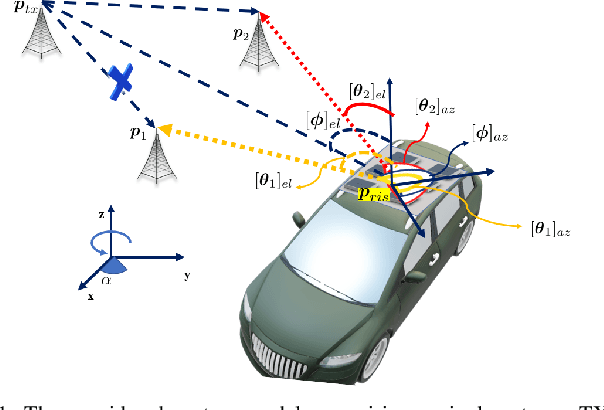
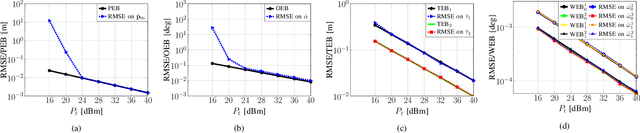
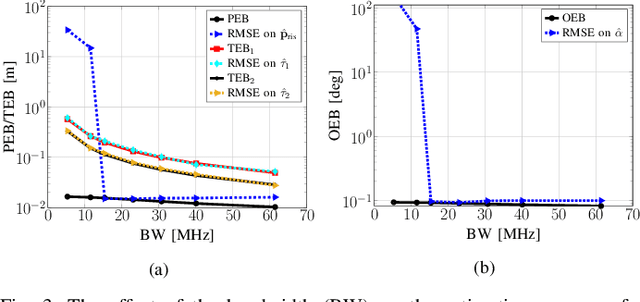
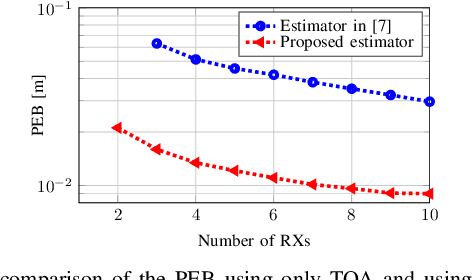
Reconfigurable intelligent surfaces (RISs) are considered as an enabling technology for the upcoming sixth generation of wireless systems, exhibiting significant potential for radio localization and sensing. An RIS is usually treated as an anchor point with known position and orientation when deployed to offer user localization. However, it can also be attached to a user to enable its localization in a semi-passive manner. In this paper, we consider a static user equipped with an RIS and study the RIS localization problem (i.e., joint three-dimensional position and orientation estimation), when operating in a system comprising a single-antenna transmitter and multiple synchronized single-antenna receivers with known locations. We present a multi-stage estimator using time-of-arrival and spatial frequency measurements, and derive the Cram\'er-Rao lower bounds for the estimated parameters to validate the estimator's performance. Our simulation results demonstrate the efficiency of the proposed RIS state estimation approach under various system operation parameters.
Correlation-aware active learning for surgery video segmentation
Nov 15, 2023Semantic segmentation is a complex task that relies heavily on large amounts of annotated image data. However, annotating such data can be time-consuming and resource-intensive, especially in the medical domain. Active Learning (AL) is a popular approach that can help to reduce this burden by iteratively selecting images for annotation to improve the model performance. In the case of video data, it is important to consider the model uncertainty and the temporal nature of the sequences when selecting images for annotation. This work proposes a novel AL strategy for surgery video segmentation, \COALSamp{}, COrrelation-aWare Active Learning. Our approach involves projecting images into a latent space that has been fine-tuned using contrastive learning and then selecting a fixed number of representative images from local clusters of video frames. We demonstrate the effectiveness of this approach on two video datasets of surgical instruments and three real-world video datasets. The datasets and code will be made publicly available upon receiving necessary approvals.