 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robustness Enhancement in Neural Networks with Alpha-Stable Training Noise
Nov 17, 2023
With the increasing use of deep learning on data collected by non-perfect sensors and in non-perfect environments, the robustness of deep learning systems has become an important issue. A common approach for obtaining robustness to noise has been to train deep learning systems with data augmented with Gaussian noise. In this work, we challenge the common choice of Gaussian noise and explore the possibility of stronger robustness for non-Gaussian impulsive noise, specifically alpha-stable noise. Justified by the Generalized Central Limit Theorem and evidenced by observations in various application areas, alpha-stable noise is widely present in nature. By comparing the testing accuracy of models trained with Gaussian noise and alpha-stable noise on data corrupted by different noise, we find that training with alpha-stable noise is more effective than Gaussian noise, especially when the dataset is corrupted by impulsive noise, thus improving the robustness of the model. The generality of this conclusion is validated through experiments conducted on various deep learning models with image and time series datasets, and other benchmark corrupted datasets. Consequently, we propose a novel data augmentation method that replaces Gaussian noise, which is typically added to the training data, with alpha-stable noise.
RAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information
Nov 09, 2023As the IT industry advances, system log data becomes increasingly crucial. Many computer systems rely on log texts for management due to restricted access to source code. The need for log anomaly detection is growing, especially in real-world applications, but identifying anomalies in rapidly accumulating logs remains a challenging task. Traditional deep learning-based anomaly detection models require dataset-specific training, leading to corresponding delays. Notably, most methods only focus on sequence-level log information, which makes the detection of subtle anomalies harder, and often involve inference processes that are difficult to utilize in real-time. We introduce RAPID, a model that capitalizes on the inherent features of log data to enable anomaly detection without training delays, ensuring real-time capability. RAPID treats logs as natural language, extracting representations using pre-trained language models. Given that logs can be categorized based on system context, we implement a retrieval-based technique to contrast test logs with the most similar normal logs. This strategy not only obviates the need for log-specific training but also adeptly incorporates token-level information, ensuring refined and robust detection, particularly for unseen logs. We also propose the core set technique, which can reduce the computational cost needed for comparison. Experimental results show that even without training on log data, RAPID demonstrates competitive performance compared to prior models and achieves the best performance on certain datasets. Through various research questions, we verified its capability for real-time detection without delay.
General Policies, Subgoal Structure, and Planning Width
Nov 09, 2023It has been observed that many classical planning domains with atomic goals can be solved by means of a simple polynomial exploration procedure, called IW, that runs in time exponential in the problem width, which in these cases is bounded and small. Yet, while the notion of width has become part of state-of-the-art planning algorithms such as BFWS, there is no good explanation for why so many benchmark domains have bounded width when atomic goals are considered. In this work, we address this question by relating bounded width with the existence of general optimal policies that in each planning instance are represented by tuples of atoms of bounded size. We also define the notions of (explicit) serializations and serialized width that have a broader scope as many domains have a bounded serialized width but no bounded width. Such problems are solved non-optimally in polynomial time by a suitable variant of the Serialized IW algorithm. Finally, the language of general policies and the semantics of serializations are combined to yield a simple, meaningful, and expressive language for specifying serializations in compact form in the form of sketches, which can be used for encoding domain control knowledge by hand or for learning it from small examples. Sketches express general problem decompositions in terms of subgoals, and sketches of bounded width express problem decompositions that can be solved in polynomial time.
Bag of Tricks for Fully Test-Time Adaptation
Oct 03, 2023Fully Test-Time Adaptation (TTA), which aims at adapting models to data drifts, has recently attracted wide interest. Numerous tricks and techniques have been proposed to ensure robust learning on arbitrary streams of unlabeled data. However, assessing the true impact of each individual technique and obtaining a fair comparison still constitutes a significant challenge. To help consolidate the community's knowledge, we present a categorization of selected orthogonal TTA techniques, including small batch normalization, stream rebalancing, reliable sample selection, and network confidence calibration. We meticulously dissect the effect of each approach on different scenarios of interest. Through our analysis, we shed light on trade-offs induced by those techniques between accuracy, the computational power required, and model complexity. We also uncover the synergy that arises when combining techniques and are able to establish new state-of-the-art results.
Self-Supervised Versus Supervised Training for Segmentation of Organoid Images
Nov 19, 2023The process of annotating relevant data in the field of digital microscopy can be both time-consuming and especially expensive due to the required technical skills and human-expert knowledge. Consequently, large amounts of microscopic image data sets remain unlabeled, preventing their effective exploitation using deep-learning algorithms. In recent years it has been shown that a lot of relevant information can be drawn from unlabeled data. Self-supervised learning (SSL) is a promising solution based on learning intrinsic features under a pretext task that is similar to the main task without requiring labels. The trained result is transferred to the main task - image segmentation in our case. A ResNet50 U-Net was first trained to restore images of liver progenitor organoids from augmented images using the Structural Similarity Index Metric (SSIM), alone, and using SSIM combined with L1 loss. Both the encoder and decoder were trained in tandem. The weights were transferred to another U-Net model designed for segmentation with frozen encoder weights, using Binary Cross Entropy, Dice, and Intersection over Union (IoU) losses. For comparison, we used the same U-Net architecture to train two supervised models, one utilizing the ResNet50 encoder as well as a simple CNN. Results showed that self-supervised learning models using a 25\% pixel drop or image blurring augmentation performed better than the other augmentation techniques using the IoU loss. When trained on only 114 images for the main task, the self-supervised learning approach outperforms the supervised method achieving an F1-score of 0.85, with higher stability, in contrast to an F1=0.78 scored by the supervised method. Furthermore, when trained with larger data sets (1,000 images), self-supervised learning is still able to perform better, achieving an F1-score of 0.92, contrasting to a score of 0.85 for the supervised method.
Testing with Non-identically Distributed Samples
Nov 19, 2023We examine the extent to which sublinear-sample property testing and estimation applies to settings where samples are independently but not identically distributed. Specifically, we consider the following distributional property testing framework: Suppose there is a set of distributions over a discrete support of size $k$, $\textbf{p}_1, \textbf{p}_2,\ldots,\textbf{p}_T$, and we obtain $c$ independent draws from each distribution. Suppose the goal is to learn or test a property of the average distribution, $\textbf{p}_{\mathrm{avg}}$. This setup models a number of important practical settings where the individual distributions correspond to heterogeneous entities -- either individuals, chronologically distinct time periods, spatially separated data sources, etc. From a learning standpoint, even with $c=1$ samples from each distribution, $\Theta(k/\varepsilon^2)$ samples are necessary and sufficient to learn $\textbf{p}_{\mathrm{avg}}$ to within error $\varepsilon$ in TV distance. To test uniformity or identity -- distinguishing the case that $\textbf{p}_{\mathrm{avg}}$ is equal to some reference distribution, versus has $\ell_1$ distance at least $\varepsilon$ from the reference distribution, we show that a linear number of samples in $k$ is necessary given $c=1$ samples from each distribution. In contrast, for $c \ge 2$, we recover the usual sublinear sample testing of the i.i.d. setting: we show that $O(\sqrt{k}/\varepsilon^2 + 1/\varepsilon^4)$ samples are sufficient, matching the optimal sample complexity in the i.i.d. case in the regime where $\varepsilon \ge k^{-1/4}$. Additionally, we show that in the $c=2$ case, there is a constant $\rho > 0$ such that even in the linear regime with $\rho k$ samples, no tester that considers the multiset of samples (ignoring which samples were drawn from the same $\textbf{p}_i$) can perform uniformity testing.
Lyfe Agents: Generative agents for low-cost real-time social interactions
Oct 03, 2023
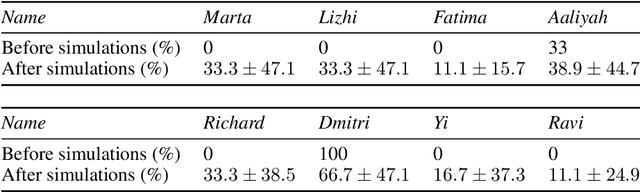
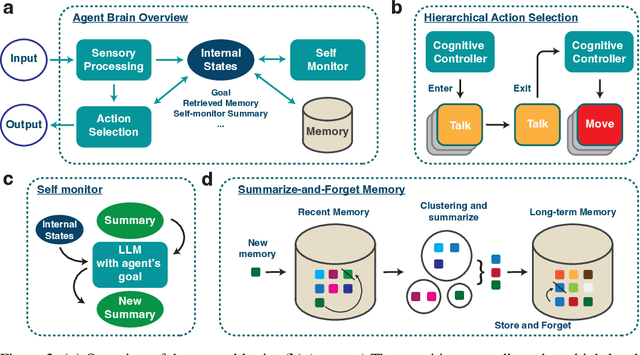
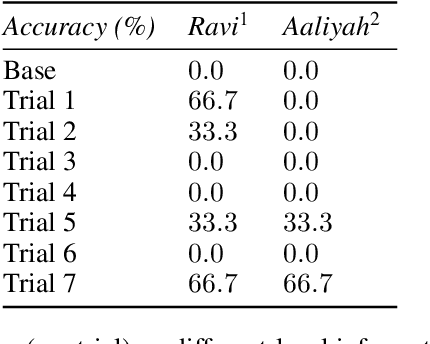
Highly autonomous generative agents powered by large language models promise to simulate intricate social behaviors in virtual societies. However, achieving real-time interactions with humans at a low computational cost remains challenging. Here, we introduce Lyfe Agents. They combine low-cost with real-time responsiveness, all while remaining intelligent and goal-oriented. Key innovations include: (1) an option-action framework, reducing the cost of high-level decisions; (2) asynchronous self-monitoring for better self-consistency; and (3) a Summarize-and-Forget memory mechanism, prioritizing critical memory items at a low cost. We evaluate Lyfe Agents' self-motivation and sociability across several multi-agent scenarios in our custom LyfeGame 3D virtual environment platform. When equipped with our brain-inspired techniques, Lyfe Agents can exhibit human-like self-motivated social reasoning. For example, the agents can solve a crime (a murder mystery) through autonomous collaboration and information exchange. Meanwhile, our techniques enabled Lyfe Agents to operate at a computational cost 10-100 times lower than existing alternatives. Our findings underscore the transformative potential of autonomous generative agents to enrich human social experiences in virtual worlds.
Modeling Sequences as Star Graphs to Address Over-smoothing in Self-attentive Sequential Recommendation
Nov 13, 2023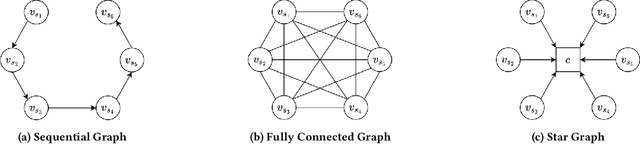
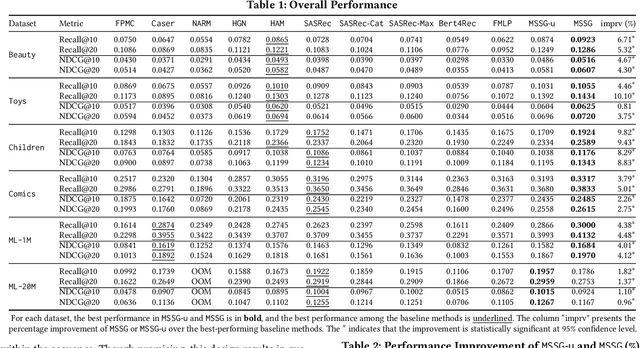
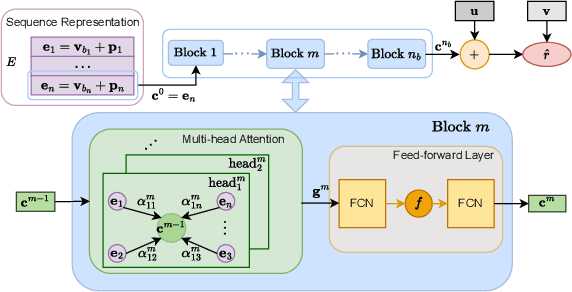
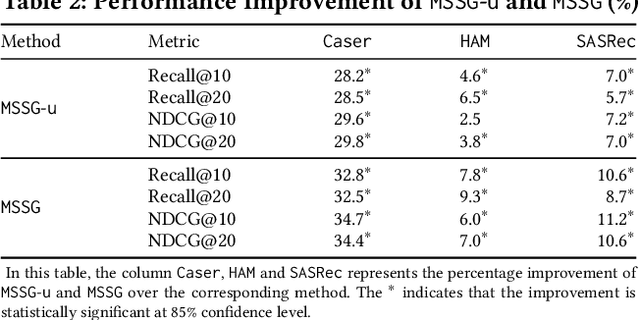
Self-attention (SA) mechanisms have been widely used in developing sequential recommendation (SR) methods, and demonstrated state-of-the-art performance. However, in this paper, we show that self-attentive SR methods substantially suffer from the over-smoothing issue that item embeddings within a sequence become increasingly similar across attention blocks. As widely demonstrated in the literature, this issue could lead to a loss of information in individual items, and significantly degrade models' scalability and performance. To address the over-smoothing issue, in this paper, we view items within a sequence constituting a star graph and develop a method, denoted as MSSG, for SR. Different from existing self-attentive methods, MSSG introduces an additional internal node to specifically capture the global information within the sequence, and does not require information propagation among items. This design fundamentally addresses the over-smoothing issue and enables MSSG a linear time complexity with respect to the sequence length. We compare MSSG with ten state-of-the-art baseline methods on six public benchmark datasets. Our experimental results demonstrate that MSSG significantly outperforms the baseline methods, with an improvement of as much as 10.10%. Our analysis shows the superior scalability of MSSG over the state-of-the-art self-attentive methods. Our complexity analysis and run-time performance comparison together show that MSSG is both theoretically and practically more efficient than self-attentive methods. Our analysis of the attention weights learned in SA-based methods indicates that on sparse recommendation data, modeling dependencies in all item pairs using the SA mechanism yields limited information gain, and thus, might not benefit the recommendation performance
Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery
Nov 06, 2023In the quest for unveiling novel categories at test time, we confront the inherent limitations of traditional supervised recognition models that are restricted by a predefined category set. While strides have been made in the realms of self-supervised and open-world learning towards test-time category discovery, a crucial yet often overlooked question persists: what exactly delineates a category? In this paper, we conceptualize a category through the lens of optimization, viewing it as an optimal solution to a well-defined problem. Harnessing this unique conceptualization, we propose a novel, efficient and self-supervised method capable of discovering previously unknown categories at test time. A salient feature of our approach is the assignment of minimum length category codes to individual data instances, which encapsulates the implicit category hierarchy prevalent in real-world datasets. This mechanism affords us enhanced control over category granularity, thereby equipping our model to handle fine-grained categories adeptly. Experimental evaluations, bolstered by state-of-the-art benchmark comparisons, testify to the efficacy of our solution in managing unknown categories at test time. Furthermore, we fortify our proposition with a theoretical foundation, providing proof of its optimality. Our code is available at https://github.com/SarahRastegar/InfoSieve.
Transformer-VQ: Linear-Time Transformers via Vector Quantization
Sep 28, 2023We introduce Transformer-VQ, a decoder-only transformer computing softmax-based dense self-attention in linear time. Transformer-VQ's efficient attention is enabled by vector-quantized keys and a novel caching mechanism. In large-scale experiments, Transformer-VQ is shown highly competitive in quality, with strong results on Enwik8 (0.99 bpb), PG-19 (26.6 ppl), and ImageNet64 (3.16 bpb). Code: https://github.com/transformer-vq/transformer_vq