 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Online Real-Time Memory-based Video Inpainting Transformers
Mar 24, 2024
Video inpainting tasks have seen significant improvements in recent years with the rise of deep neural networks and, in particular, vision transformers. Although these models show promising reconstruction quality and temporal consistency, they are still unsuitable for live videos, one of the last steps to make them completely convincing and usable. The main limitations are that these state-of-the-art models inpaint using the whole video (offline processing) and show an insufficient frame rate. In our approach, we propose a framework to adapt existing inpainting transformers to these constraints by memorizing and refining redundant computations while maintaining a decent inpainting quality. Using this framework with some of the most recent inpainting models, we show great online results with a consistent throughput above 20 frames per second. The code and pretrained models will be made available upon acceptance.
Partially-Observable Sequential Change-Point Detection for Autocorrelated Data via Upper Confidence Region
Mar 30, 2024Sequential change point detection for multivariate autocorrelated data is a very common problem in practice. However, when the sensing resources are limited, only a subset of variables from the multivariate system can be observed at each sensing time point. This raises the problem of partially observable multi-sensor sequential change point detection. For it, we propose a detection scheme called adaptive upper confidence region with state space model (AUCRSS). It models multivariate time series via a state space model (SSM), and uses an adaptive sampling policy for efficient change point detection and localization. A partially-observable Kalman filter algorithm is developed for online inference of SSM, and accordingly, a change point detection scheme based on a generalized likelihood ratio test is developed. How its detection power relates to the adaptive sampling strategy is analyzed. Meanwhile, by treating the detection power as a reward, its connection with the online combinatorial multi-armed bandit (CMAB) problem is formulated and an adaptive upper confidence region algorithm is proposed for adaptive sampling policy design. Theoretical analysis of the asymptotic average detection delay is performed, and thorough numerical studies with synthetic data and real-world data are conducted to demonstrate the effectiveness of our method.
Bilateral Propagation Network for Depth Completion
Apr 01, 2024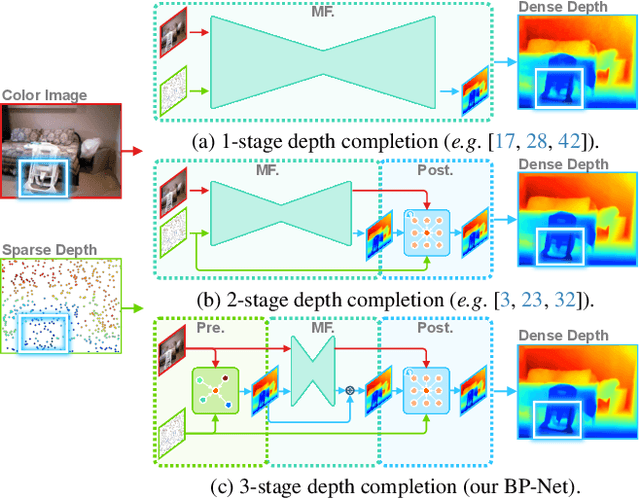
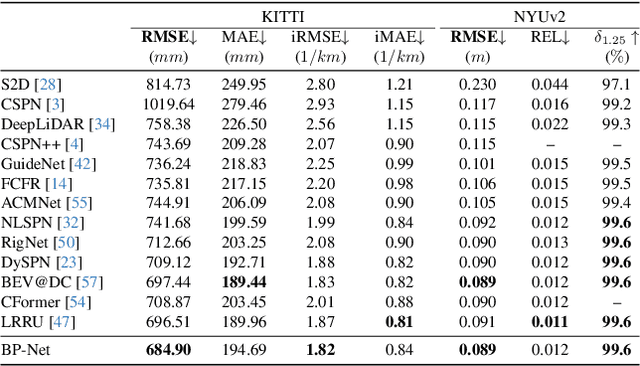
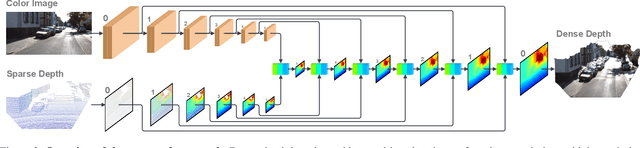
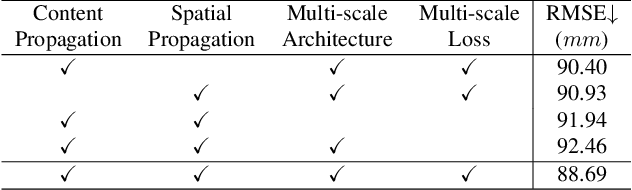
Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.
Creating emoji lexica from unsupervised sentiment analysis of their descriptions
Apr 01, 2024Online media, such as blogs and social networking sites, generate massive volumes of unstructured data of great interest to analyze the opinions and sentiments of individuals and organizations. Novel approaches beyond Natural Language Processing are necessary to quantify these opinions with polarity metrics. So far, the sentiment expressed by emojis has received little attention. The use of symbols, however, has boomed in the past four years. About twenty billion are typed in Twitter nowadays, and new emojis keep appearing in each new Unicode version, making them increasingly relevant to sentiment analysis tasks. This has motivated us to propose a novel approach to predict the sentiments expressed by emojis in online textual messages, such as tweets, that does not require human effort to manually annotate data and saves valuable time for other analysis tasks. For this purpose, we automatically constructed a novel emoji sentiment lexicon using an unsupervised sentiment analysis system based on the definitions given by emoji creators in Emojipedia. Additionally, we automatically created lexicon variants by also considering the sentiment distribution of the informal texts accompanying emojis. All these lexica are evaluated and compared regarding the improvement obtained by including them in sentiment analysis of the annotated datasets provided by Kralj Novak et al. (2015). The results confirm the competitiveness of our approach.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models
Apr 01, 2024Diffusion Models are vulnerable to backdoor attacks, where malicious attackers inject backdoors by poisoning some parts of the training samples during the training stage. This poses a serious threat to the downstream users, who query the diffusion models through the API or directly download them from the internet. To mitigate the threat of backdoor attacks, there have been a plethora of investigations on backdoor detections. However, none of them designed a specialized backdoor detection method for diffusion models, rendering the area much under-explored. Moreover, these prior methods mainly focus on the traditional neural networks in the classification task, which cannot be adapted to the backdoor detections on the generative task easily. Additionally, most of the prior methods require white-box access to model weights and architectures, or the probability logits as additional information, which are not always practical. In this paper, we propose a Unified Framework for Input-level backdoor Detection (UFID) on the diffusion models, which is motivated by observations in the diffusion models and further validated with a theoretical causality analysis. Extensive experiments across different datasets on both conditional and unconditional diffusion models show that our method achieves a superb performance on detection effectiveness and run-time efficiency. The code is available at https://github.com/GuanZihan/official_UFID.
Finite Sample Frequency Domain Identification
Apr 01, 2024We study non-parametric frequency-domain system identification from a finite-sample perspective. We assume an open loop scenario where the excitation input is periodic and consider the Empirical Transfer Function Estimate (ETFE), where the goal is to estimate the frequency response at certain desired (evenly-spaced) frequencies, given input-output samples. We show that under sub-Gaussian colored noise (in time-domain) and stability assumptions, the ETFE estimates are concentrated around the true values. The error rate is of the order of $\mathcal{O}((d_{\mathrm{u}}+\sqrt{d_{\mathrm{u}}d_{\mathrm{y}}})\sqrt{M/N_{\mathrm{tot}}})$, where $N_{\mathrm{tot}}$ is the total number of samples, $M$ is the number of desired frequencies, and $d_{\mathrm{u}},\,d_{\mathrm{y}}$ are the dimensions of the input and output signals respectively. This rate remains valid for general irrational transfer functions and does not require a finite order state-space representation. By tuning $M$, we obtain a $N_{\mathrm{tot}}^{-1/3}$ finite-sample rate for learning the frequency response over all frequencies in the $ \mathcal{H}_{\infty}$ norm. Our result draws upon an extension of the Hanson-Wright inequality to semi-infinite matrices. We study the finite-sample behavior of ETFE in simulations.
FPGA-Accelerated Correspondence-free Point Cloud Registration with PointNet Features
Apr 01, 2024Point cloud registration serves as a basis for vision and robotic applications including 3D reconstruction and mapping. Despite significant improvements on the quality of results, recent deep learning approaches are computationally expensive and power-hungry, making them difficult to deploy on resource-constrained edge devices. To tackle this problem, in this paper, we propose a fast, accurate, and robust registration for low-cost embedded FPGAs. Based on a parallel and pipelined PointNet feature extractor, we develop custom accelerator cores namely PointLKCore and ReAgentCore, for two different learning-based methods. They are both correspondence-free and computationally efficient as they avoid the costly feature matching step involving nearest-neighbor search. The proposed cores are implemented on the Xilinx ZCU104 board and evaluated using both synthetic and real-world datasets, showing the substantial improvements in the trade-offs between runtime and registration quality. They run 44.08-45.75x faster than ARM Cortex-A53 CPU and offer 1.98-11.13x speedups over Intel Xeon CPU and Nvidia Jetson boards, while consuming less than 1W and achieving 163.11-213.58x energy-efficiency compared to Nvidia GeForce GPU. The proposed cores are more robust to noise and large initial misalignments than the classical methods and quickly find reasonable solutions in less than 15ms, demonstrating the real-time performance.
Towards Label-Efficient Human Matting: A Simple Baseline for Weakly Semi-Supervised Trimap-Free Human Matting
Apr 01, 2024This paper presents a new practical training method for human matting, which demands delicate pixel-level human region identification and significantly laborious annotations. To reduce the annotation cost, most existing matting approaches often rely on image synthesis to augment the dataset. However, the unnaturalness of synthesized training images brings in a new domain generalization challenge for natural images. To address this challenge, we introduce a new learning paradigm, weakly semi-supervised human matting (WSSHM), which leverages a small amount of expensive matte labels and a large amount of budget-friendly segmentation labels, to save the annotation cost and resolve the domain generalization problem. To achieve the goal of WSSHM, we propose a simple and effective training method, named Matte Label Blending (MLB), that selectively guides only the beneficial knowledge of the segmentation and matte data to the matting model. Extensive experiments with our detailed analysis demonstrate our method can substantially improve the robustness of the matting model using a few matte data and numerous segmentation data. Our training method is also easily applicable to real-time models, achieving competitive accuracy with breakneck inference speed (328 FPS on NVIDIA V100 GPU). The implementation code is available at \url{https://github.com/clovaai/WSSHM}.
A Novel Algorithm for Digital Lithological Mapping-Case Studies in Sri Lanka's Mineral Exploration
Apr 01, 2024Conventional manual lithological mapping (MLM) through field surveys are resource-extensive and time-consuming. Digital lithological mapping (DLM), harnessing remotely sensed spectral imaging techniques, provides an effective strategy to streamline target locations for MLM or an efficient alternative to MLM. DLM relies on laboratory-generated generic end-member signatures of minerals for spectral analysis. Thus, the accuracy of DLM may be limited due to the presence of site-specific impurities. A strategy, based on a hybrid machine-learning and signal-processing algorithm, is proposed in this paper to tackle this problem of site-specific impurities. In addition, a soil pixel alignment strategy is proposed here to visualize the relative purity of the target minerals. The proposed methodologies are validated via case studies for mapping of Limestone deposits in Jaffna, Ilmenite deposits in Pulmoddai and Mannar, and Montmorillonite deposits in Murunkan, Sri Lanka. The results of satellite-based spectral imaging analysis were corroborated with X-ray diffraction (XRD) and Magnetic Separation (MS) analysis of soil samples collected from those sites via field surveys. There exists a good correspondence between the relative availability of the minerals with the XRD and MS results. In particular, correlation coefficients of 0.8115 and 0.9853 were found for the sites in Pulmoddai and Jaffna respectively.