 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Multimodal Dataset of 21,412 Recorded Nights for Sleep and Respiratory Research
Nov 15, 2023
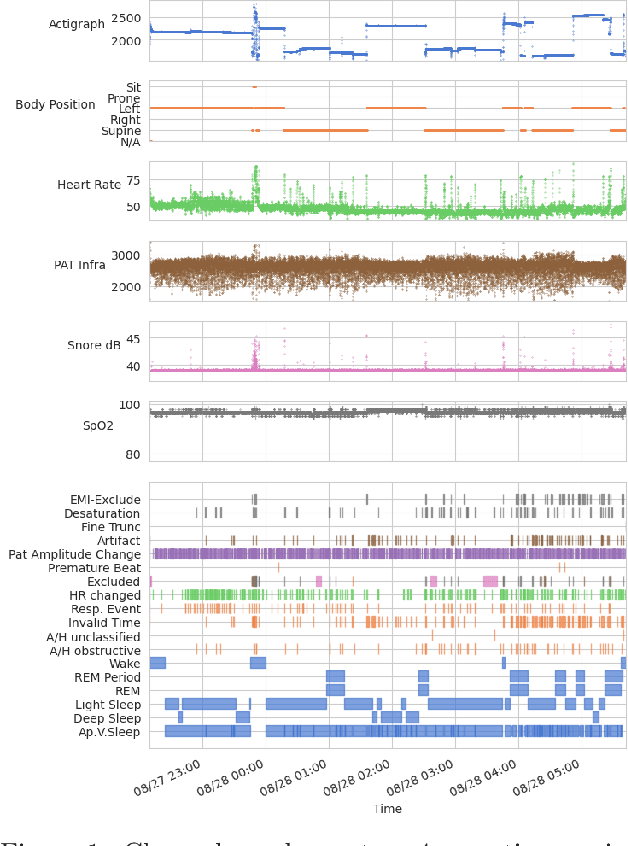
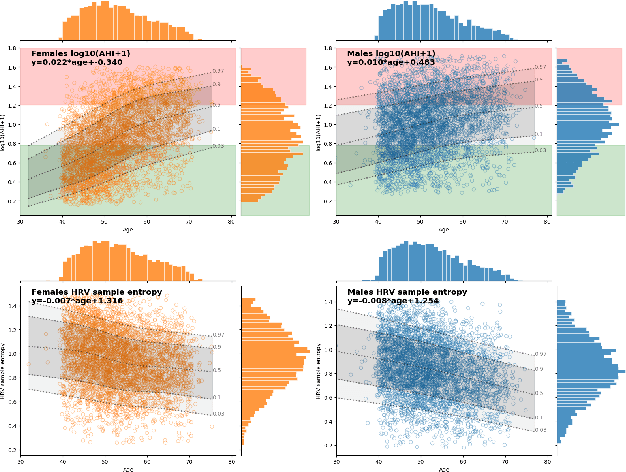
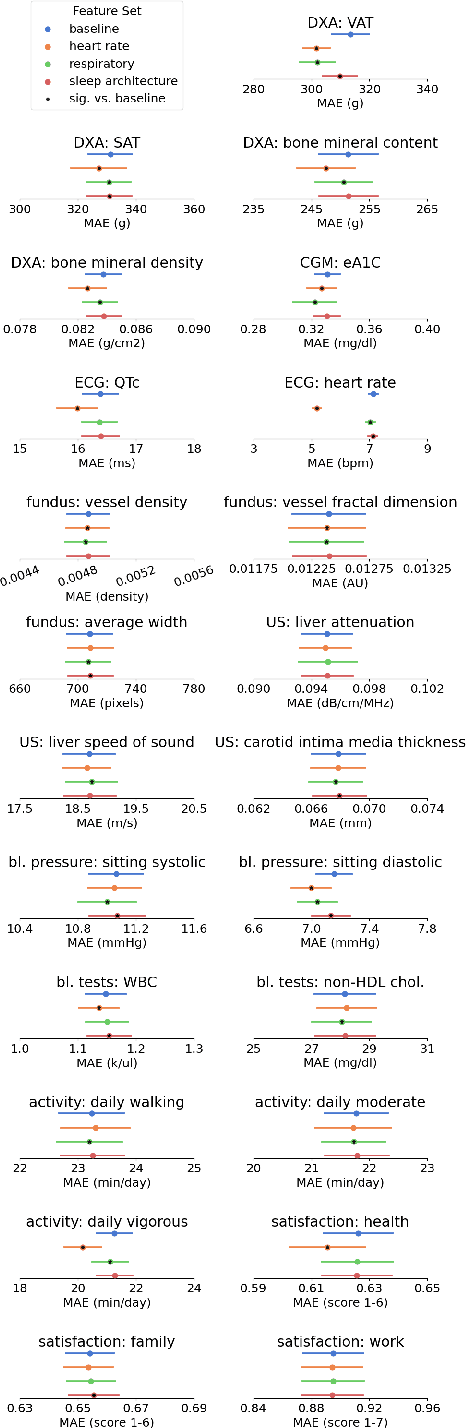
This study introduces a novel, rich dataset obtained from home sleep apnea tests using the FDA-approved WatchPAT-300 device, collected from 7,077 participants over 21,412 nights. The dataset comprises three levels of sleep data: raw multi-channel time-series from sensors, annotated sleep events, and computed summary statistics, which include 447 features related to sleep architecture, sleep apnea, and heart rate variability (HRV). We present reference values for Apnea/Hypopnea Index (AHI), sleep efficiency, Wake After Sleep Onset (WASO), and HRV sample entropy, stratified by age and sex. Moreover, we demonstrate that the dataset improves the predictive capability for various health related traits, including body composition, bone density, blood sugar levels and cardiovascular health. These results illustrate the dataset's potential to advance sleep research, personalized healthcare, and machine learning applications in biomedicine.
AdVENTR: Autonomous Robot Navigation in Complex Outdoor Environments
Nov 15, 2023We present a novel system, AdVENTR for autonomous robot navigation in unstructured outdoor environments that consist of uneven and vegetated terrains. Our approach is general and can enable both wheeled and legged robots to handle outdoor terrain complexity including unevenness, surface properties like poor traction, granularity, obstacle stiffness, etc. We use data from sensors including RGB cameras, 3D Lidar, IMU, robot odometry, and pose information with efficient learning-based perception and planning algorithms that can execute on edge computing hardware. Our system uses a scene-aware switching method to perceive the environment for navigation at any time instant and dynamically switches between multiple perception algorithms. We test our system in a variety of sloped, rocky, muddy, and densely vegetated terrains and demonstrate its performance on Husky and Spot robots.
BrainZ-BP: A Non-invasive Cuff-less Blood Pressure Estimation Approach Leveraging Brain Bio-impedance and Electrocardiogram
Nov 18, 2023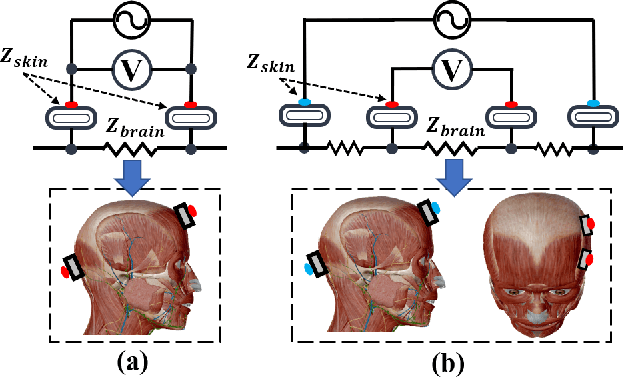
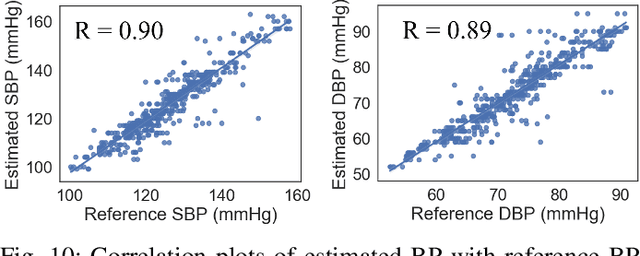
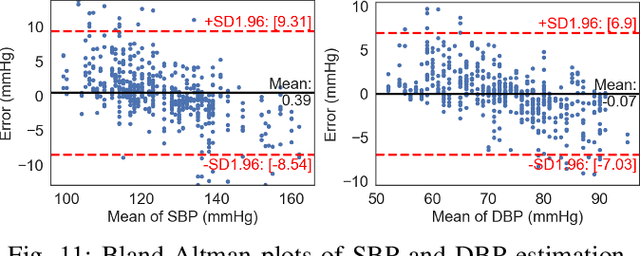
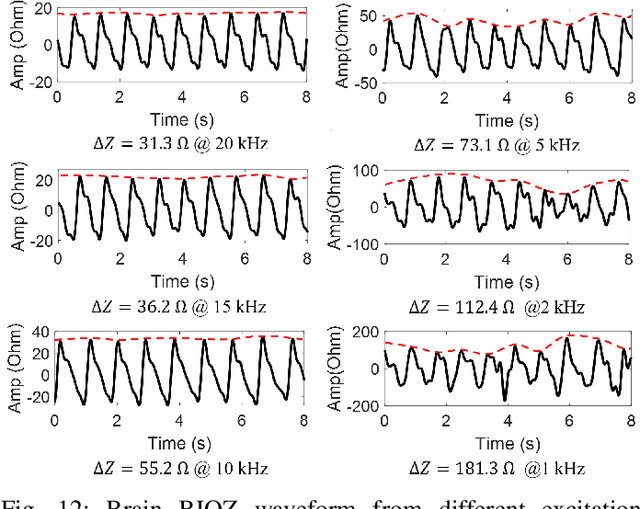
Accurate and continuous blood pressure (BP) monitoring is essential to the early prevention of cardiovascular diseases. Non-invasive and cuff-less BP estimation algorithm has gained much attention in recent years. Previous studies have demonstrated that brain bio-impedance (BIOZ) is a promising technique for non-invasive intracranial pressure (ICP) monitoring. Clinically, treatment for patients with traumatic brain injuries (TBI) requires monitoring the ICP and BP of patients simultaneously. Estimating BP by brain BIOZ directly can reduce the number of sensors attached to the patients, thus improving their comfort. To address the issues, in this study, we explore the feasibility of leveraging brain BIOZ for BP estimation and propose a novel cuff-less BP estimation approach called BrainZ-BP. Two electrodes are placed on the forehead and occipital bone of the head in the anterior-posterior direction for brain BIOZ measurement. Various features including pulse transit time and morphological features of brain BIOZ are extracted and fed into four regression models for BP estimation. Results show that the mean absolute error, root mean square error, and correlation coefficient of random forest regression model are 2.17 mmHg, 3.91 mmHg, and 0.90 for systolic pressure estimation, and are 1.71 mmHg, 3.02 mmHg, and 0.89 for diastolic pressure estimation. The presented BrainZ-BP can be applied in the brain BIOZ-based ICP monitoring scenario to monitor BP simultaneously.
Contextualizing Internet Memes Across Social Media Platforms
Nov 18, 2023Internet memes have emerged as a novel format for communication and expressing ideas on the web. Their fluidity and creative nature are reflected in their widespread use, often across platforms and occasionally for unethical or harmful purposes. While computational work has already analyzed their high-level virality over time and developed specialized classifiers for hate speech detection, there have been no efforts to date that aim to holistically track, identify, and map internet memes posted on social media. To bridge this gap, we investigate whether internet memes across social media platforms can be contextualized by using a semantic repository of knowledge, namely, a knowledge graph. We collect thousands of potential internet meme posts from two social media platforms, namely Reddit and Discord, and perform an extract-transform-load procedure to create a data lake with candidate meme posts. By using vision transformer-based similarity, we match these candidates against the memes cataloged in a recently released knowledge graph of internet memes, IMKG. We provide evidence that memes published online can be identified by mapping them to IMKG. We leverage this grounding to study the prevalence of memes on different platforms, discover popular memes, and select common meme channels and subreddits. Finally, we illustrate how the grounding can enable users to get context about memes on social media thanks to their link to the knowledge graph.
Towards a Standardized Reinforcement Learning Framework for AAM Contingency Management
Nov 17, 2023
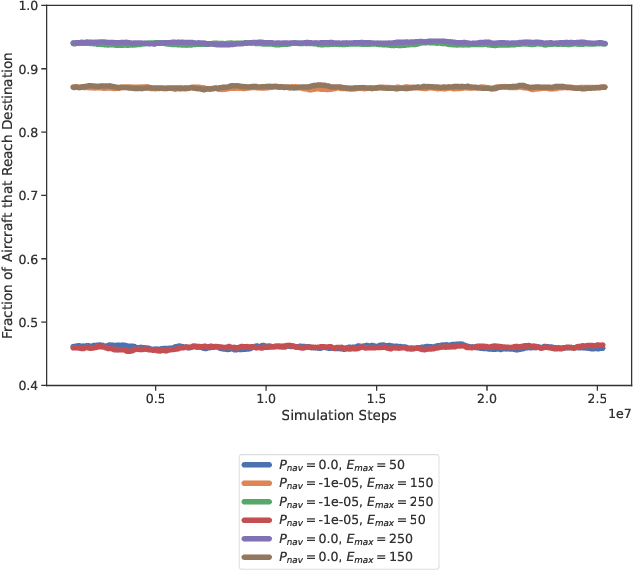

Advanced Air Mobility (AAM) is the next generation of air transportation that includes new entrants such as electric vertical takeoff and landing (eVTOL) aircraft, increasingly autonomous flight operations, and small UAS package delivery. With these new vehicles and operational concepts comes a desire to increase densities far beyond what occurs today in and around urban areas, to utilize new battery technology, and to move toward more autonomously-piloted aircraft. To achieve these goals, it becomes essential to introduce new safety management system capabilities that can rapidly assess risk as it evolves across a span of complex hazards and, if necessary, mitigate risk by executing appropriate contingencies via supervised or automated decision-making during flights. Recently, reinforcement learning has shown promise for real-time decision making across a wide variety of applications including contingency management. In this work, we formulate the contingency management problem as a Markov Decision Process (MDP) and integrate the contingency management MDP into the AAM-Gym simulation framework. This enables rapid prototyping of reinforcement learning algorithms and evaluation of existing systems, thus providing a community benchmark for future algorithm development. We report baseline statistical information for the environment and provide example performance metrics.
Collaborative Grid Mapping for Moving Object Tracking Evaluation
Nov 17, 2023Perception of other road users is a crucial task for intelligent vehicles. Perception systems can use on-board sensors only or be in cooperation with other vehicles or with roadside units. In any case, the performance of perception systems has to be evaluated against ground-truth data, which is a particularly tedious task and requires numerous manual operations. In this article, we propose a novel semi-automatic method for pseudo ground-truth estimation. The principle consists in carrying out experiments with several vehicles equipped with LiDAR sensors and with fixed perception systems located at the roadside in order to collaboratively build reference dynamic data. The method is based on grid mapping and in particular on the elaboration of a background map that holds relevant information that remains valid during a whole dataset sequence. Data from all agents is converted in time-stamped observations grids. A data fusion method that manages uncertainties combines the background map with observations to produce dynamic reference information at each instant. Several datasets have been acquired with three experimental vehicles and a roadside unit. An evaluation of this method is finally provided in comparison to a handmade ground truth.
Is Conventional SNN Really Efficient? A Perspective from Network Quantization
Nov 17, 2023Spiking Neural Networks (SNNs) have been widely praised for their high energy efficiency and immense potential. However, comprehensive research that critically contrasts and correlates SNNs with quantized Artificial Neural Networks (ANNs) remains scant, often leading to skewed comparisons lacking fairness towards ANNs. This paper introduces a unified perspective, illustrating that the time steps in SNNs and quantized bit-widths of activation values present analogous representations. Building on this, we present a more pragmatic and rational approach to estimating the energy consumption of SNNs. Diverging from the conventional Synaptic Operations (SynOps), we champion the "Bit Budget" concept. This notion permits an intricate discourse on strategically allocating computational and storage resources between weights, activation values, and temporal steps under stringent hardware constraints. Guided by the Bit Budget paradigm, we discern that pivoting efforts towards spike patterns and weight quantization, rather than temporal attributes, elicits profound implications for model performance. Utilizing the Bit Budget for holistic design consideration of SNNs elevates model performance across diverse data types, encompassing static imagery and neuromorphic datasets. Our revelations bridge the theoretical chasm between SNNs and quantized ANNs and illuminate a pragmatic trajectory for future endeavors in energy-efficient neural computations.
Pseudo Label-Guided Data Fusion and Output Consistency for Semi-Supervised Medical Image Segmentation
Nov 17, 2023Supervised learning algorithms based on Convolutional Neural Networks have become the benchmark for medical image segmentation tasks, but their effectiveness heavily relies on a large amount of labeled data. However, annotating medical image datasets is a laborious and time-consuming process. Inspired by semi-supervised algorithms that use both labeled and unlabeled data for training, we propose the PLGDF framework, which builds upon the mean teacher network for segmenting medical images with less annotation. We propose a novel pseudo-label utilization scheme, which combines labeled and unlabeled data to augment the dataset effectively. Additionally, we enforce the consistency between different scales in the decoder module of the segmentation network and propose a loss function suitable for evaluating the consistency. Moreover, we incorporate a sharpening operation on the predicted results, further enhancing the accuracy of the segmentation. Extensive experiments on three publicly available datasets demonstrate that the PLGDF framework can largely improve performance by incorporating the unlabeled data. Meanwhile, our framework yields superior performance compared to six state-of-the-art semi-supervised learning methods. The codes of this study are available at https://github.com/ortonwang/PLGDF.
Signal Processing Meets SGD: From Momentum to Filter
Nov 17, 2023In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.
TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series
Oct 02, 2023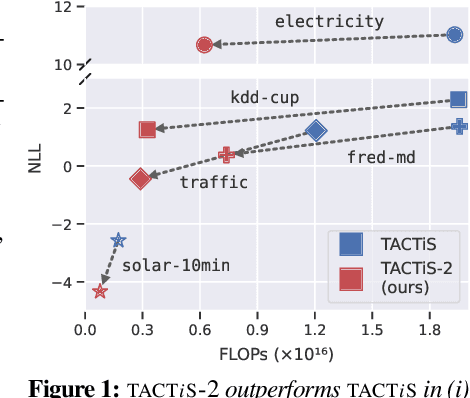
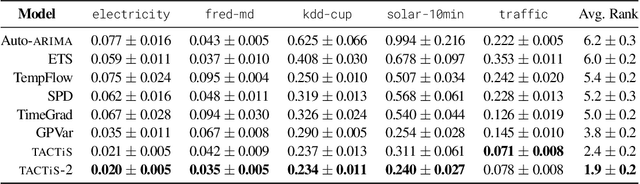
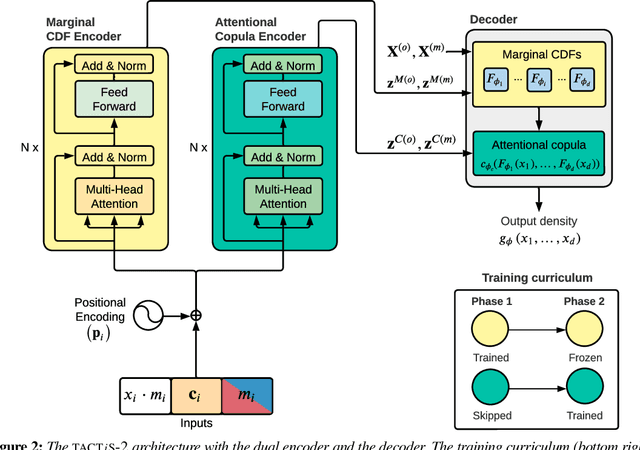
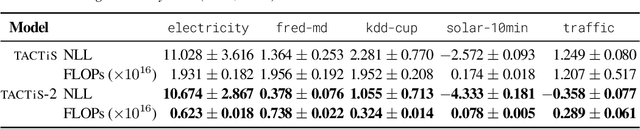
We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including forecasting, interpolation, and their combinations. Building on copula theory, we propose a simplified objective for the recently-introduced transformer-based attentional copulas (TACTiS), wherein the number of distributional parameters now scales linearly with the number of variables instead of factorially. The new objective requires the introduction of a training curriculum, which goes hand-in-hand with necessary changes to the original architecture. We show that the resulting model has significantly better training dynamics and achieves state-of-the-art performance across diverse real-world forecasting tasks, while maintaining the flexibility of prior work, such as seamless handling of unaligned and unevenly-sampled time series.