 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Inductive Biases in Video Modeling through Neural CDEs
Nov 08, 2023

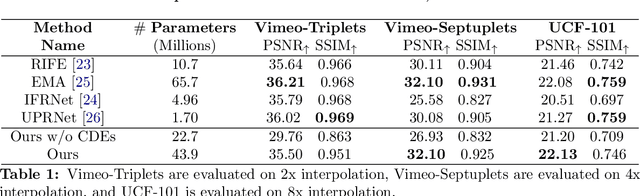

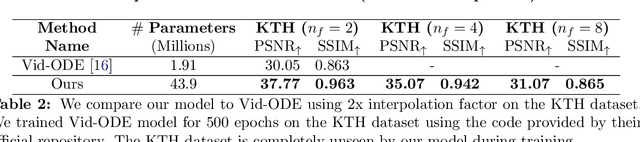
We introduce a novel approach to video modeling that leverages controlled differential equations (CDEs) to address key challenges in video tasks, notably video interpolation and mask propagation. We apply CDEs at varying resolutions leading to a continuous-time U-Net architecture. Unlike traditional methods, our approach does not require explicit optical flow learning, and instead makes use of the inherent continuous-time features of CDEs to produce a highly expressive video model. We demonstrate competitive performance against state-of-the-art models for video interpolation and mask propagation tasks.
Toward Robust Recommendation via Real-time Vicinal Defense
Sep 29, 2023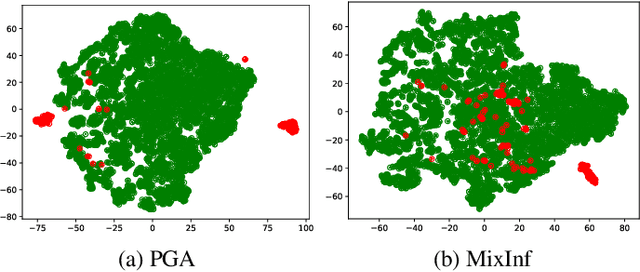
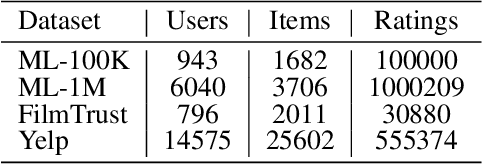
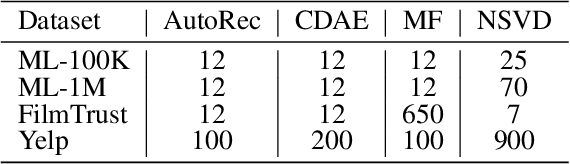
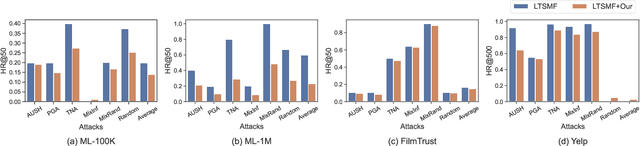
Recommender systems have been shown to be vulnerable to poisoning attacks, where malicious data is injected into the dataset to cause the recommender system to provide biased recommendations. To defend against such attacks, various robust learning methods have been proposed. However, most methods are model-specific or attack-specific, making them lack generality, while other methods, such as adversarial training, are oriented towards evasion attacks and thus have a weak defense strength in poisoning attacks. In this paper, we propose a general method, Real-time Vicinal Defense (RVD), which leverages neighboring training data to fine-tune the model before making a recommendation for each user. RVD works in the inference phase to ensure the robustness of the specific sample in real-time, so there is no need to change the model structure and training process, making it more practical. Extensive experimental results demonstrate that RVD effectively mitigates targeted poisoning attacks across various models without sacrificing accuracy. Moreover, the defensive effect can be further amplified when our method is combined with other strategies.
Error Analysis of Option Pricing via Deep PDE Solvers: Empirical Study
Nov 13, 2023Option pricing, a fundamental problem in finance, often requires solving non-linear partial differential equations (PDEs). When dealing with multi-asset options, such as rainbow options, these PDEs become high-dimensional, leading to challenges posed by the curse of dimensionality. While deep learning-based PDE solvers have recently emerged as scalable solutions to this high-dimensional problem, their empirical and quantitative accuracy remains not well-understood, hindering their real-world applicability. In this study, we aimed to offer actionable insights into the utility of Deep PDE solvers for practical option pricing implementation. Through comparative experiments, we assessed the empirical performance of these solvers in high-dimensional contexts. Our investigation identified three primary sources of errors in Deep PDE solvers: (i) errors inherent in the specifications of the target option and underlying assets, (ii) errors originating from the asset model simulation methods, and (iii) errors stemming from the neural network training. Through ablation studies, we evaluated the individual impact of each error source. Our results indicate that the Deep BSDE method (DBSDE) is superior in performance and exhibits robustness against variations in option specifications. In contrast, some other methods are overly sensitive to option specifications, such as time to expiration. We also find that the performance of these methods improves inversely proportional to the square root of batch size and the number of time steps. This observation can aid in estimating computational resources for achieving desired accuracies with Deep PDE solvers.
Semantic Communication for Cooperative Perception based on Importance Map
Nov 11, 2023Cooperative perception, which has a broader perception field than single-vehicle perception, has played an increasingly important role in autonomous driving to conduct 3D object detection. Through vehicle-to-vehicle (V2V) communication technology, various connected automated vehicles (CAVs) can share their sensory information (LiDAR point clouds) for cooperative perception. We employ an importance map to extract significant semantic information and propose a novel cooperative perception semantic communication scheme with intermediate fusion. Meanwhile, our proposed architecture can be extended to the challenging time-varying multipath fading channel. To alleviate the distortion caused by the time-varying multipath fading, we adopt explicit orthogonal frequency-division multiplexing (OFDM) blocks combined with channel estimation and channel equalization. Simulation results demonstrate that our proposed model outperforms the traditional separate source-channel coding over various channel models. Moreover, a robustness study indicates that only part of semantic information is key to cooperative perception. Although our proposed model has only been trained over one specific channel, it has the ability to learn robust coded representations of semantic information that remain resilient to various channel models, demonstrating its generality and robustness.
Vital Signs Estimation Using a 26 GHz Multi-Beam Communication Testbed
Nov 19, 2023This paper presents a novel pipeline for vital sign monitoring using a 26 GHz multi-beam communication testbed. In context of Joint Communication and Sensing (JCAS), the advanced communication capability at millimeter-wave bands is comparable to the radio resource of radars and is promising to sense the surrounding environment. Being able to communicate and sense the vital sign of humans present in the environment will enable new vertical services of telecommunication, i.e., remote health monitoring. The proposed processing pipeline leverages spatially orthogonal beams to estimate the vital sign - breath rate and heart rate - of single and multiple persons in static scenarios from the raw Channel State Information samples. We consider both monostatic and bistatic sensing scenarios. For monostatic scenario, we employ the phase time-frequency calibration and Discrete Wavelet Transform to improve the performance compared to the conventional Fast Fourier Transform based methods. For bistatic scenario, we use K-means clustering algorithm to extract multi-person vital signs due to the distinct frequency-domain signal feature between single and multi-person scenarios. The results show that the estimated breath rate and heart rate reach below 2 beats per minute (bpm) error compared to the reference captured by on-body sensor for the single-person monostatic sensing scenario with body-transceiver distance up to 2 m, and the two-person bistatic sensing scenario with BS-UE distance up to 4 m. The presented work does not optimize the OFDM waveform parameters for sensing; it demonstrates a promising JCAS proof-of-concept in contact-free vital sign monitoring using mmWave multi-beam communication systems.
SUQL: Conversational Search over Structured and Unstructured Data with Large Language Models
Nov 16, 2023


Many knowledge sources consist of both structured information such as relational databases as well as unstructured free text. Building a conversational interface to such data sources is challenging. This paper introduces SUQL, Structured and Unstructured Query Language, the first formal executable representation that naturally covers compositions of structured and unstructured data queries. Specifically, it augments SQL with several free-text primitives to form a precise, succinct, and expressive representation. This paper also presents a conversational search agent based on large language models, including a few-shot contextual semantic parser for SUQL. To validate our approach, we introduce a dataset consisting of crowdsourced questions and conversations about real restaurants. Over 51% of the questions in the dataset require both structured and unstructured data, suggesting that it is a common phenomenon. We show that our few-shot conversational agent based on SUQL finds an entity satisfying all user requirements 89.3% of the time, compared to just 65.0% for a strong and commonly used baseline.
Human Still Wins over LLM: An Empirical Study of Active Learning on Domain-Specific Annotation Tasks
Nov 16, 2023Large Language Models (LLMs) have demonstrated considerable advances, and several claims have been made about their exceeding human performance. However, in real-world tasks, domain knowledge is often required. Low-resource learning methods like Active Learning (AL) have been proposed to tackle the cost of domain expert annotation, raising this question: Can LLMs surpass compact models trained with expert annotations in domain-specific tasks? In this work, we conduct an empirical experiment on four datasets from three different domains comparing SOTA LLMs with small models trained on expert annotations with AL. We found that small models can outperform GPT-3.5 with a few hundreds of labeled data, and they achieve higher or similar performance with GPT-4 despite that they are hundreds time smaller. Based on these findings, we posit that LLM predictions can be used as a warmup method in real-world applications and human experts remain indispensable in tasks involving data annotation driven by domain-specific knowledge.
Online Continual Knowledge Learning for Language Models
Nov 16, 2023Large Language Models (LLMs) serve as repositories of extensive world knowledge, enabling them to perform tasks such as question-answering and fact-checking. However, this knowledge can become obsolete as global contexts change. In this paper, we introduce a novel problem in the realm of continual learning: Online Continual Knowledge Learning (OCKL). This problem formulation aims to manage the dynamic nature of world knowledge in LMs under real-time constraints. We propose a new benchmark and evaluation metric designed to measure both the rate of new knowledge acquisition and the retention of previously learned knowledge. Our empirical evaluation, conducted using a variety of state-of-the-art methods, establishes robust base-lines for OCKL. Our results reveal that existing continual learning approaches are unfortunately insufficient for tackling the unique challenges posed by OCKL. We identify key factors that influence the trade-off between knowledge acquisition and retention, thereby advancing our understanding of how to train LMs in a continually evolving environment.
Multi-Step Dialogue Workflow Action Prediction
Nov 16, 2023In task-oriented dialogue, a system often needs to follow a sequence of actions, called a workflow, that complies with a set of guidelines in order to complete a task. In this paper, we propose the novel problem of multi-step workflow action prediction, in which the system predicts multiple future workflow actions. Accurate prediction of multiple steps allows for multi-turn automation, which can free up time to focus on more complex tasks. We propose three modeling approaches that are simple to implement yet lead to more action automation: 1) fine-tuning on a training dataset, 2) few-shot in-context learning leveraging retrieval and large language model prompting, and 3) zero-shot graph traversal, which aggregates historical action sequences into a graph for prediction. We show that multi-step action prediction produces features that improve accuracy on downstream dialogue tasks like predicting task success, and can increase automation of steps by 20% without requiring as much feedback from a human overseeing the system.
Utility AI for Dynamic Task Offloading in the Multi-Edge Infrastructure
Nov 16, 2023To circumvent persistent connectivity to the cloud infrastructure, the current emphasis on computing at network edge devices in the multi-robot domain is a promising enabler for delay-sensitive jobs, yet its adoption is rife with challenges. This paper proposes a novel utility-aware dynamic task offloading strategy based on a multi-edge-robot system that takes into account computation, communication, and task execution load to minimize the overall service time for delay-sensitive applications. Prior to task offloading, continuous device, network, and task profiling are performed, and for each task assigned, an edge with maximum utility is derived using a weighted utility maximization technique, and a system reward assignment for task connectivity or sensitivity is performed. A scheduler is in charge of task assignment, whereas an executor is responsible for task offloading on edge devices. Experimental comparisons of the proposed approach with conventional offloading methods indicate better performance in terms of optimizing resource utilization and minimizing task latency.