 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Inductive Biases in Video Modeling through Neural CDEs
Nov 08, 2023

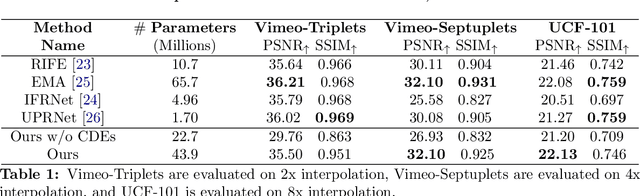

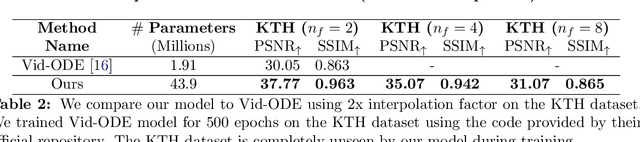
We introduce a novel approach to video modeling that leverages controlled differential equations (CDEs) to address key challenges in video tasks, notably video interpolation and mask propagation. We apply CDEs at varying resolutions leading to a continuous-time U-Net architecture. Unlike traditional methods, our approach does not require explicit optical flow learning, and instead makes use of the inherent continuous-time features of CDEs to produce a highly expressive video model. We demonstrate competitive performance against state-of-the-art models for video interpolation and mask propagation tasks.
TransONet: Automatic Segmentation of Vasculature in Computed Tomographic Angiograms Using Deep Learning
Nov 17, 2023Pathological alterations in the human vascular system underlie many chronic diseases, such as atherosclerosis and aneurysms. However, manually analyzing diagnostic images of the vascular system, such as computed tomographic angiograms (CTAs) is a time-consuming and tedious process. To address this issue, we propose a deep learning model to segment the vascular system in CTA images of patients undergoing surgery for peripheral arterial disease (PAD). Our study focused on accurately segmenting the vascular system (1) from the descending thoracic aorta to the iliac bifurcation and (2) from the descending thoracic aorta to the knees in CTA images using deep learning techniques. Our approach achieved average Dice accuracies of 93.5% and 80.64% in test dataset for (1) and (2), respectively, highlighting its high accuracy and potential clinical utility. These findings demonstrate the use of deep learning techniques as a valuable tool for medical professionals to analyze the health of the vascular system efficiently and accurately. Please visit the GitHub page for this paper at https://github.com/pip-alireza/TransOnet.
Two-stage Joint Transductive and Inductive learning for Nuclei Segmentation
Nov 17, 2023AI-assisted nuclei segmentation in histopathological images is a crucial task in the diagnosis and treatment of cancer diseases. It decreases the time required to manually screen microscopic tissue images and can resolve the conflict between pathologists during diagnosis. Deep Learning has proven useful in such a task. However, lack of labeled data is a significant barrier for deep learning-based approaches. In this study, we propose a novel approach to nuclei segmentation that leverages the available labelled and unlabelled data. The proposed method combines the strengths of both transductive and inductive learning, which have been previously attempted separately, into a single framework. Inductive learning aims at approximating the general function and generalizing to unseen test data, while transductive learning has the potential of leveraging the unlabelled test data to improve the classification. To the best of our knowledge, this is the first study to propose such a hybrid approach for medical image segmentation. Moreover, we propose a novel two-stage transductive inference scheme. We evaluate our approach on MoNuSeg benchmark to demonstrate the efficacy and potential of our method.
Visual Environment Assessment for Safe Autonomous Quadrotor Landing
Nov 17, 2023Autonomous identification and evaluation of safe landing zones are of paramount importance for ensuring the safety and effectiveness of aerial robots in the event of system failures, low battery, or the successful completion of specific tasks. In this paper, we present a novel approach for detection and assessment of potential landing sites for safe quadrotor landing. Our solution efficiently integrates 2D and 3D environmental information, eliminating the need for external aids such as GPS and computationally intensive elevation maps. The proposed pipeline combines semantic data derived from a Neural Network (NN), to extract environmental features, with geometric data obtained from a disparity map, to extract critical geometric attributes such as slope, flatness, and roughness. We define several cost metrics based on these attributes to evaluate safety, stability, and suitability of regions in the environments and identify the most suitable landing area. Our approach runs in real-time on quadrotors equipped with limited computational capabilities. Experimental results conducted in diverse environments demonstrate that the proposed method can effectively assess and identify suitable landing areas, enabling the safe and autonomous landing of a quadrotor.
On exploiting the synaptic interaction properties to obtain frequency-specific neurons
Nov 17, 2023
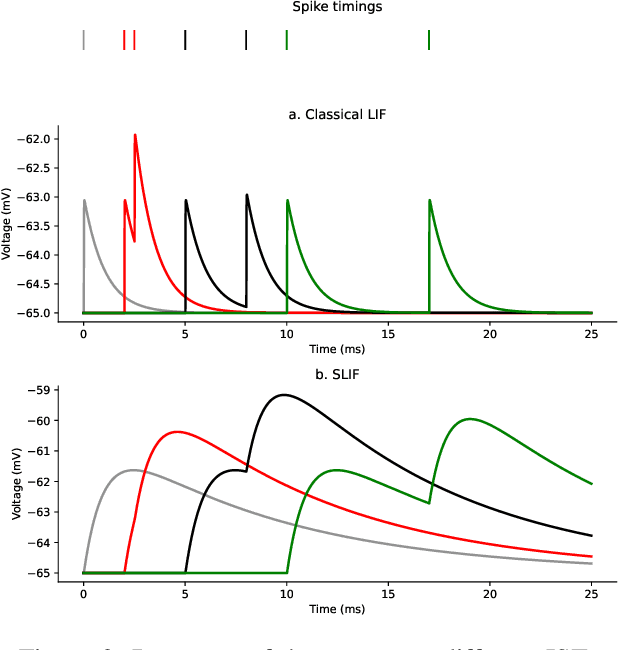
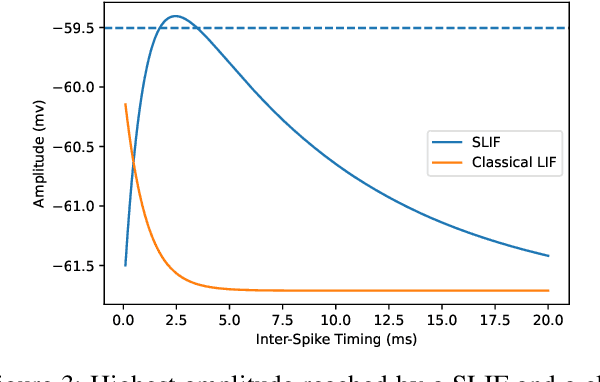
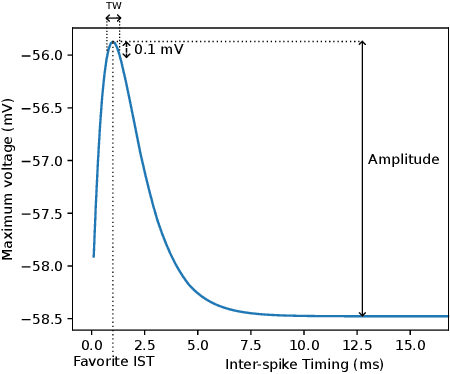
Energy consumption remains the main limiting factors in many IoT applications. In particular, micro-controllers consume far too much power. In order to overcome this problem, new circuit designs have been proposed and the use of spiking neurons and analog computing has emerged as it allows a very significant consumption reduction. However, working in the analog domain brings difficulty to handle the sequential processing of incoming signals as is needed in many use cases. In this paper, we use a bio-inspired phenomenon called Interacting Synapses to produce a time filter, without using non-biological techniques such as synaptic delays. We propose a model of neuron and synapses that fire for a specific range of delays between two incoming spikes, but do not react when this Inter-Spike Timing is not in that range. We study the parameters of the model to understand how to choose them and adapt the Inter-Spike Timing. The originality of the paper is to propose a new way, in the analog domain, to deal with temporal sequences.
Enhancing Student Engagement in Online Learning through Facial Expression Analysis and Complex Emotion Recognition using Deep Learning
Nov 17, 2023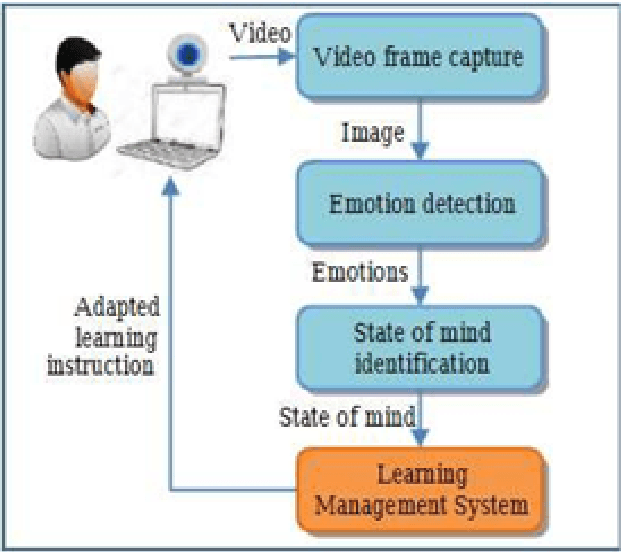

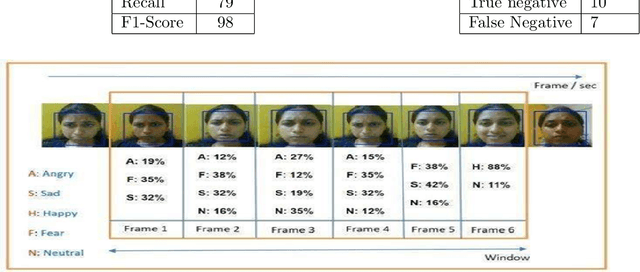
In response to the COVID-19 pandemic, traditional physical classrooms have transitioned to online environments, necessitating effective strategies to ensure sustained student engagement. A significant challenge in online teaching is the absence of real-time feedback from teachers on students learning progress. This paper introduces a novel approach employing deep learning techniques based on facial expressions to assess students engagement levels during online learning sessions. Human emotions cannot be adequately conveyed by a student using only the basic emotions, including anger, disgust, fear, joy, sadness, surprise, and neutrality. To address this challenge, proposed a generation of four complex emotions such as confusion, satisfaction, disappointment, and frustration by combining the basic emotions. These complex emotions are often experienced simultaneously by students during the learning session. To depict these emotions dynamically,utilized a continuous stream of image frames instead of discrete images. The proposed work utilized a Convolutional Neural Network (CNN) model to categorize the fundamental emotional states of learners accurately. The proposed CNN model demonstrates strong performance, achieving a 95% accuracy in precise categorization of learner emotions.
A Video-Based Activity Classification of Human Pickers in Agriculture
Nov 17, 2023In farming systems, harvesting operations are tedious, time- and resource-consuming tasks. Based on this, deploying a fleet of autonomous robots to work alongside farmworkers may provide vast productivity and logistics benefits. Then, an intelligent robotic system should monitor human behavior, identify the ongoing activities and anticipate the worker's needs. In this work, the main contribution consists of creating a benchmark model for video-based human pickers detection, classifying their activities to serve in harvesting operations for different agricultural scenarios. Our solution uses the combination of a Mask Region-based Convolutional Neural Network (Mask R-CNN) for object detection and optical flow for motion estimation with newly added statistical attributes of flow motion descriptors, named as Correlation Sensitivity (CS). A classification criterion is defined based on the Kernel Density Estimation (KDE) analysis and K-means clustering algorithm, which are implemented upon in-house collected dataset from different crop fields like strawberry polytunnels and apple tree orchards. The proposed framework is quantitatively analyzed using sensitivity, specificity, and accuracy measures and shows satisfactory results amidst various dataset challenges such as lighting variation, blur, and occlusions.
Wireless Communications in Cavity: A Reconfigurable Boundary Modulation based Approach
Nov 15, 2023This paper explores the potential wireless communication applications of Reconfigurable Intelligent Surfaces (RIS) in reverberant wave propagation environments. Unlike in free space, we utilize the sensitivity to boundaries of the enclosed electromagnetic (EM) field and the equivalent perturbation of RISs. For the first time, we introduce the framework of reconfigurable boundary modulation in the cavities . We have proposed a robust boundary modulation scheme that exploits the continuity of object motion and the mutation of the codebook switch, which achieves pulse position modulation (PPM) by RIS-generated equivalent pulses for wireless communication in cavities. This approach achieves around 2 Mbps bit rate in the prototype and demonstrates strong resistance to channel's frequency selectivity resulting in an extremely low bit error rate (BER).
Polygonal Cone Control Barrier Functions (PolyC2BF) for safe navigation in cluttered environments
Nov 15, 2023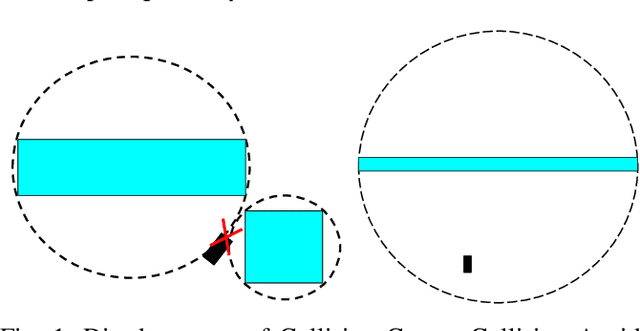
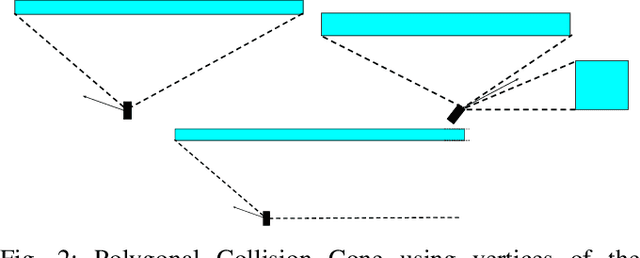
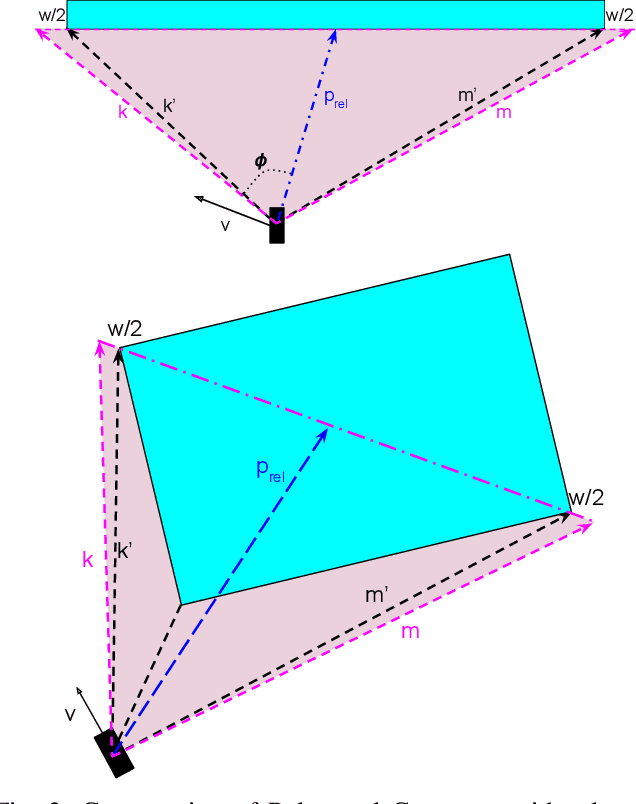
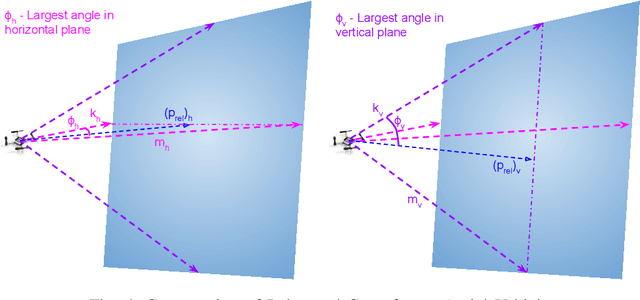
In fields such as mining, search and rescue, and archaeological exploration, ensuring real-time, collision-free navigation of robots in confined, cluttered environments is imperative. Despite the value of established path planning algorithms, they often face challenges in convergence rates and handling dynamic infeasibilities. Alternative techniques like collision cones struggle to accurately represent complex obstacle geometries. This paper introduces a novel category of control barrier functions, known as Polygonal Cone Control Barrier Function (PolyC2BF), which addresses overestimation and computational complexity issues. The proposed PolyC2BF, formulated as a Quadratic Programming (QP) problem, proves effective in facilitating collision-free movement of multiple robots in complex environments. The efficacy of this approach is further demonstrated through PyBullet simulations on quadruped (unicycle model), and crazyflie 2.1 (quadrotor model) in cluttered environments.
Open-Vocabulary Camouflaged Object Segmentation
Nov 19, 2023
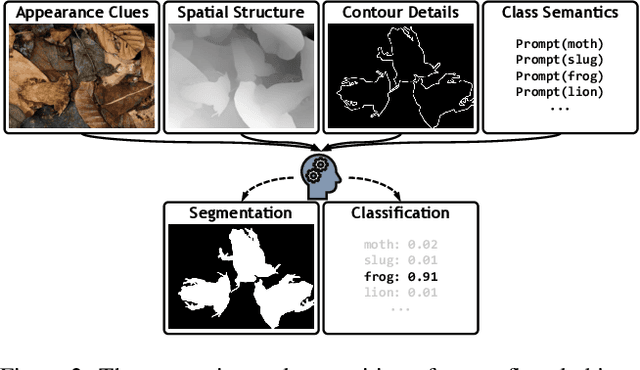
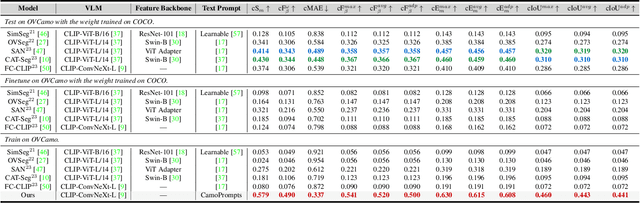

Recently, the emergence of the large-scale vision-language model (VLM), such as CLIP, has opened the way towards open-world object perception. Many works has explored the utilization of pre-trained VLM for the challenging open-vocabulary dense prediction task that requires perceive diverse objects with novel classes at inference time. Existing methods construct experiments based on the public datasets of related tasks, which are not tailored for open vocabulary and rarely involves imperceptible objects camouflaged in complex scenes due to data collection bias and annotation costs. To fill in the gaps, we introduce a new task, open-vocabulary camouflaged object segmentation (OVCOS) and construct a large-scale complex scene dataset (\textbf{OVCamo}) which containing 11,483 hand-selected images with fine annotations and corresponding object classes. Further, we build a strong single-stage open-vocabulary \underline{c}amouflaged \underline{o}bject \underline{s}egmentation transform\underline{er} baseline \textbf{OVCoser} attached to the parameter-fixed CLIP with iterative semantic guidance and structure enhancement. By integrating the guidance of class semantic knowledge and the supplement of visual structure cues from the edge and depth information, the proposed method can efficiently capture camouflaged objects. Moreover, this effective framework also surpasses previous state-of-the-arts of open-vocabulary semantic image segmentation by a large margin on our OVCamo dataset. With the proposed dataset and baseline, we hope that this new task with more practical value can further expand the research on open-vocabulary dense prediction tasks.