 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Message Propagation Through Time: An Algorithm for Sequence Dependency Retention in Time Series Modeling
Sep 28, 2023
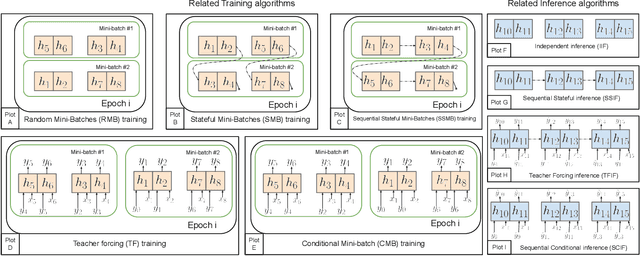
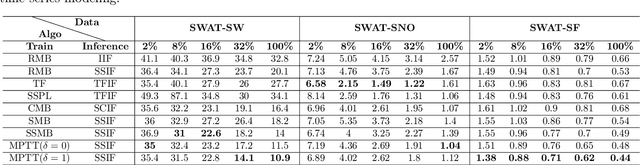
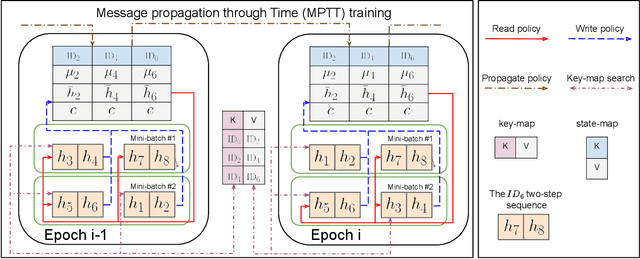

Time series modeling, a crucial area in science, often encounters challenges when training Machine Learning (ML) models like Recurrent Neural Networks (RNNs) using the conventional mini-batch training strategy that assumes independent and identically distributed (IID) samples and initializes RNNs with zero hidden states. The IID assumption ignores temporal dependencies among samples, resulting in poor performance. This paper proposes the Message Propagation Through Time (MPTT) algorithm to effectively incorporate long temporal dependencies while preserving faster training times relative to the stateful solutions. MPTT utilizes two memory modules to asynchronously manage initial hidden states for RNNs, fostering seamless information exchange between samples and allowing diverse mini-batches throughout epochs. MPTT further implements three policies to filter outdated and preserve essential information in the hidden states to generate informative initial hidden states for RNNs, facilitating robust training. Experimental results demonstrate that MPTT outperforms seven strategies on four climate datasets with varying levels of temporal dependencies.
Time CNN and Graph Convolution Network for Epileptic Spike Detection in MEG Data
Oct 13, 2023Magnetoencephalography (MEG) recordings of patients with epilepsy exhibit spikes, a typical biomarker of the pathology. Detecting those spikes allows accurate localization of brain regions triggering seizures. Spike detection is often performed manually. However, it is a burdensome and error prone task due to the complexity of MEG data. To address this problem, we propose a 1D temporal convolutional neural network (Time CNN) coupled with a graph convolutional network (GCN) to classify short time frames of MEG recording as containing a spike or not. Compared to other recent approaches, our models have fewer parameters to train and we propose to use a GCN to account for MEG sensors spatial relationships. Our models produce clinically relevant results and outperform deep learning-based state-of-the-art methods reaching a classification f1-score of 76.7% on a balanced dataset and of 25.5% on a realistic, highly imbalanced dataset, for the spike class.
Deep Attentive Time Warping
Sep 13, 2023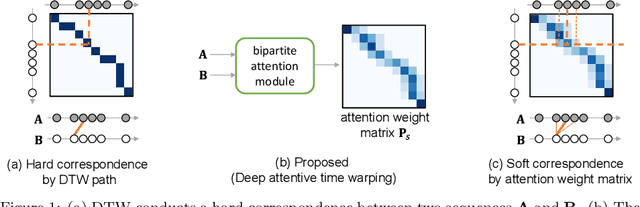
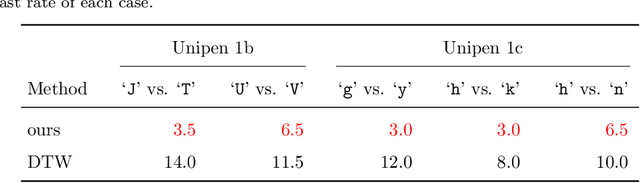
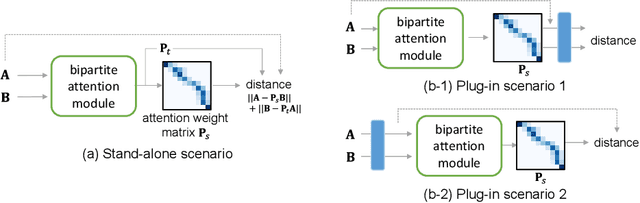
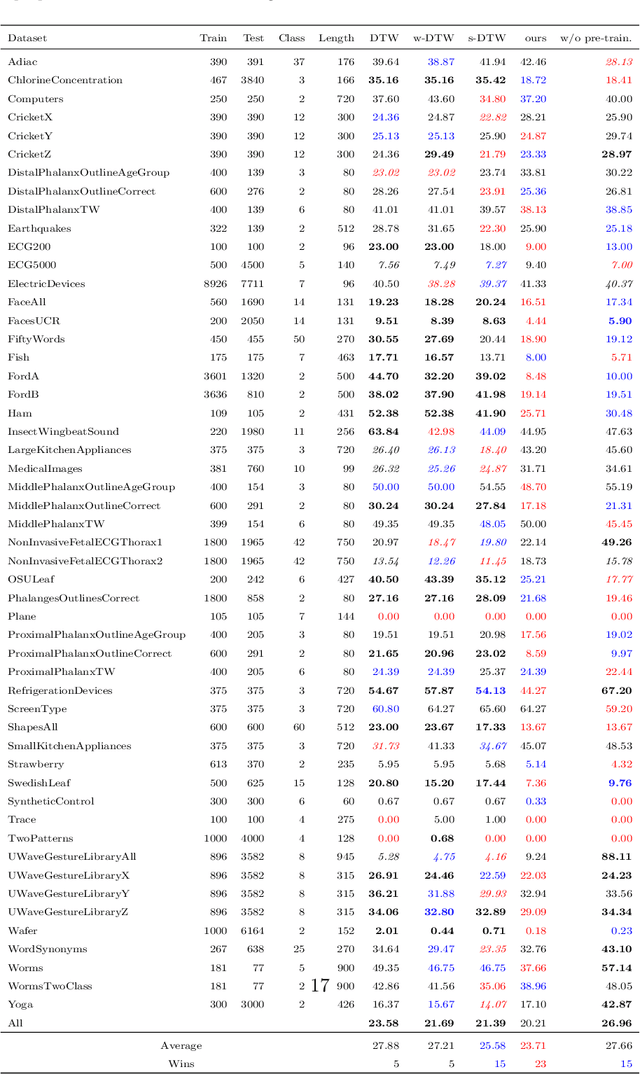
Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.
A Hypothesis on Good Practices for AI-based Systems for Financial Time Series Forecasting: Towards Domain-Driven XAI Methods
Nov 13, 2023
Machine learning and deep learning have become increasingly prevalent in financial prediction and forecasting tasks, offering advantages such as enhanced customer experience, democratising financial services, improving consumer protection, and enhancing risk management. However, these complex models often lack transparency and interpretability, making them challenging to use in sensitive domains like finance. This has led to the rise of eXplainable Artificial Intelligence (XAI) methods aimed at creating models that are easily understood by humans. Classical XAI methods, such as LIME and SHAP, have been developed to provide explanations for complex models. While these methods have made significant contributions, they also have limitations, including computational complexity, inherent model bias, sensitivity to data sampling, and challenges in dealing with feature dependence. In this context, this paper explores good practices for deploying explainability in AI-based systems for finance, emphasising the importance of data quality, audience-specific methods, consideration of data properties, and the stability of explanations. These practices aim to address the unique challenges and requirements of the financial industry and guide the development of effective XAI tools.
Linear Log-Normal Attention with Unbiased Concentration
Nov 22, 2023Transformer models have achieved remarkable results in a wide range of applications. However, their scalability is hampered by the quadratic time and memory complexity of the self-attention mechanism concerning the sequence length. This limitation poses a substantial obstacle when dealing with long documents or high-resolution images. In this work, we study the self-attention mechanism by analyzing the distribution of the attention matrix and its concentration ability. Furthermore, we propose instruments to measure these quantities and introduce a novel self-attention mechanism, Linear Log-Normal Attention, designed to emulate the distribution and concentration behavior of the original self-attention. Our experimental results on popular natural language benchmarks reveal that our proposed Linear Log-Normal Attention outperforms other linearized attention alternatives, offering a promising avenue for enhancing the scalability of transformer models. Our code is available in supplementary materials.
A Foundational Framework and Methodology for Personalized Early and Timely Diagnosis
Nov 26, 2023Early diagnosis of diseases holds the potential for deep transformation in healthcare by enabling better treatment options, improving long-term survival and quality of life, and reducing overall cost. With the advent of medical big data, advances in diagnostic tests as well as in machine learning and statistics, early or timely diagnosis seems within reach. Early diagnosis research often neglects the potential for optimizing individual diagnostic paths. To enable personalized early diagnosis, a foundational framework is needed that delineates the diagnosis process and systematically identifies the time-dependent value of various diagnostic tests for an individual patient given their unique characteristics. Here, we propose the first foundational framework for early and timely diagnosis. It builds on decision-theoretic approaches to outline the diagnosis process and integrates machine learning and statistical methodology for estimating the optimal personalized diagnostic path. To describe the proposed framework as well as possibly other frameworks, we provide essential definitions. The development of a foundational framework is necessary for several reasons: 1) formalism provides clarity for the development of decision support tools; 2) observed information can be complemented with estimates of the future patient trajectory; 3) the net benefit of counterfactual diagnostic paths and associated uncertainties can be modeled for individuals 4) 'early' and 'timely' diagnosis can be clearly defined; 5) a mechanism emerges for assessing the value of technologies in terms of their impact on personalized early diagnosis, resulting health outcomes and incurred costs. Finally, we hope that this foundational framework will unlock the long-awaited potential of timely diagnosis and intervention, leading to improved outcomes for patients and higher cost-effectiveness for healthcare systems.
ChAda-ViT : Channel Adaptive Attention for Joint Representation Learning of Heterogeneous Microscopy Images
Nov 26, 2023Unlike color photography images, which are consistently encoded into RGB channels, biological images encompass various modalities, where the type of microscopy and the meaning of each channel varies with each experiment. Importantly, the number of channels can range from one to a dozen and their correlation is often comparatively much lower than RGB, as each of them brings specific information content. This aspect is largely overlooked by methods designed out of the bioimage field, and current solutions mostly focus on intra-channel spatial attention, often ignoring the relationship between channels, yet crucial in most biological applications. Importantly, the variable channel type and count prevent the projection of several experiments to a unified representation for large scale pre-training. In this study, we propose ChAda-ViT, a novel Channel Adaptive Vision Transformer architecture employing an Inter-Channel Attention mechanism on images with an arbitrary number, order and type of channels. We also introduce IDRCell100k, a bioimage dataset with a rich set of 79 experiments covering 7 microscope modalities, with a multitude of channel types, and channel counts varying from 1 to 10 per experiment. Our proposed architecture, trained in a self-supervised manner, outperforms existing approaches in several biologically relevant downstream tasks. Additionally, it can be used to bridge the gap for the first time between assays with different microscopes, channel numbers or types by embedding various image and experimental modalities into a unified biological image representation. The latter should facilitate interdisciplinary studies and pave the way for better adoption of deep learning in biological image-based analyses. Code and Data to be released soon.
Accurate and Fast Fischer-Tropsch Reaction Microkinetics using PINNs
Nov 17, 2023Microkinetics allows detailed modelling of chemical transformations occurring in many industrially relevant reactions. Traditional way of solving the microkinetics model for Fischer-Tropsch synthesis (FTS) becomes inefficient when it comes to more advanced real-time applications. In this work, we address these challenges by using physics-informed neural networks(PINNs) for modelling FTS microkinetics. We propose a computationally efficient and accurate method, enabling the ultra-fast solution of the existing microkinetics models in realistic process conditions. The proposed PINN model computes the fraction of vacant catalytic sites, a key quantity in FTS microkinetics, with median relative error (MRE) of 0.03%, and the FTS product formation rates with MRE of 0.1%. Compared to conventional equation solvers, the model achieves up to 1E+06 times speed-up when running on GPUs, thus being fast enough for multi-scale and multi-physics reactor modelling and enabling its applications in real-time process control and optimization.
LSTM-CNN: An efficient diagnostic network for Parkinson's disease utilizing dynamic handwriting analysis
Nov 20, 2023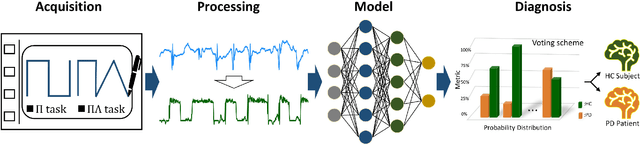
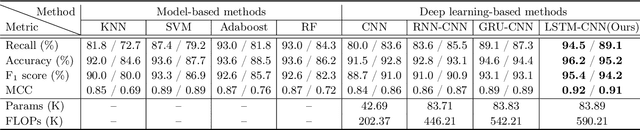
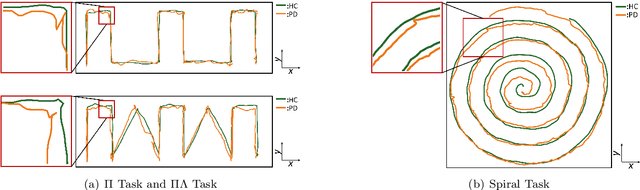
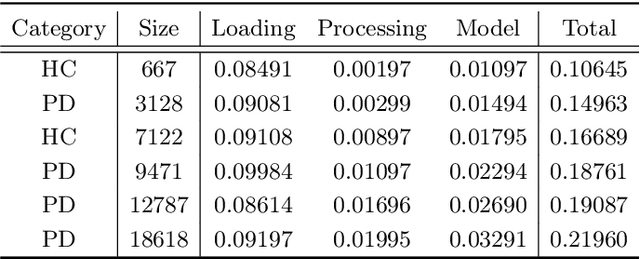
Background and objectives: Dynamic handwriting analysis, due to its non-invasive and readily accessible nature, has recently emerged as a vital adjunctive method for the early diagnosis of Parkinson's disease. In this study, we design a compact and efficient network architecture to analyse the distinctive handwriting patterns of patients' dynamic handwriting signals, thereby providing an objective identification for the Parkinson's disease diagnosis. Methods: The proposed network is based on a hybrid deep learning approach that fully leverages the advantages of both long short-term memory (LSTM) and convolutional neural networks (CNNs). Specifically, the LSTM block is adopted to extract the time-varying features, while the CNN-based block is implemented using one-dimensional convolution for low computational cost. Moreover, the hybrid model architecture is continuously refined under ablation studies for superior performance. Finally, we evaluate the proposed method with its generalization under a five-fold cross-validation, which validates its efficiency and robustness. Results: The proposed network demonstrates its versatility by achieving impressive classification accuracies on both our new DraWritePD dataset ($96.2\%$) and the well-established PaHaW dataset ($90.7\%$). Moreover, the network architecture also stands out for its excellent lightweight design, occupying a mere $0.084$M of parameters, with a total of only $0.59$M floating-point operations. It also exhibits near real-time CPU inference performance, with inference times ranging from $0.106$ to $0.220$s. Conclusions: We present a series of experiments with extensive analysis, which systematically demonstrate the effectiveness and efficiency of the proposed hybrid neural network in extracting distinctive handwriting patterns for precise diagnosis of Parkinson's disease.
You Only Look at Once for Real-time and Generic Multi-Task
Oct 10, 2023High precision, lightweight, and real-time responsiveness are three essential requirements for implementing autonomous driving. In this study, we present an adaptive, real-time, and lightweight multi-task model designed to concurrently address object detection, drivable area segmentation, and lane line segmentation tasks. Specifically, we developed an end-to-end multi-task model with a unified and streamlined segmentation structure. We introduced a learnable parameter that adaptively concatenate features in segmentation necks, using the same loss function for all segmentation tasks. This eliminates the need for customizations and enhances the model's generalization capabilities. We also introduced a segmentation head composed only of a series of convolutional layers, which reduces the inference time. We achieved competitive results on the BDD100k dataset, particularly in visualization outcomes. The performance results show a mAP50 of 81.1% for object detection, a mIoU of 91.0% for drivable area segmentation, and an IoU of 28.8% for lane line segmentation. Additionally, we introduced real-world scenarios to evaluate our model's performance in a real scene, which significantly outperforms competitors. This demonstrates that our model not only exhibits competitive performance but is also more flexible and faster than existing multi-task models. The source codes and pre-trained models are released at https://github.com/JiayuanWang-JW/YOLOv8-multi-task