 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OmniControl: Control Any Joint at Any Time for Human Motion Generation
Oct 12, 2023
We present a novel approach named OmniControl for incorporating flexible spatial control signals into a text-conditioned human motion generation model based on the diffusion process. Unlike previous methods that can only control the pelvis trajectory, OmniControl can incorporate flexible spatial control signals over different joints at different times with only one model. Specifically, we propose analytic spatial guidance that ensures the generated motion can tightly conform to the input control signals. At the same time, realism guidance is introduced to refine all the joints to generate more coherent motion. Both the spatial and realism guidance are essential and they are highly complementary for balancing control accuracy and motion realism. By combining them, OmniControl generates motions that are realistic, coherent, and consistent with the spatial constraints. Experiments on HumanML3D and KIT-ML datasets show that OmniControl not only achieves significant improvement over state-of-the-art methods on pelvis control but also shows promising results when incorporating the constraints over other joints.
Unified Long-Term Time-Series Forecasting Benchmark
Sep 27, 2023
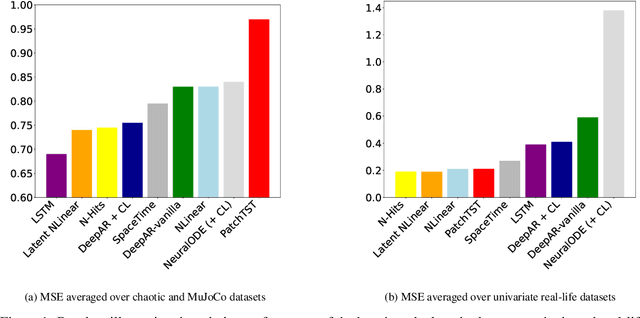
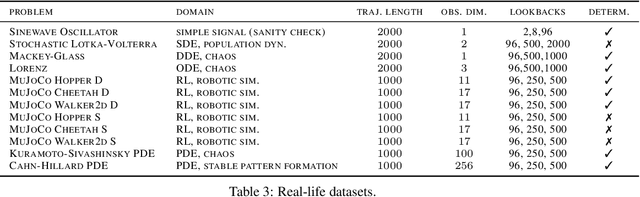
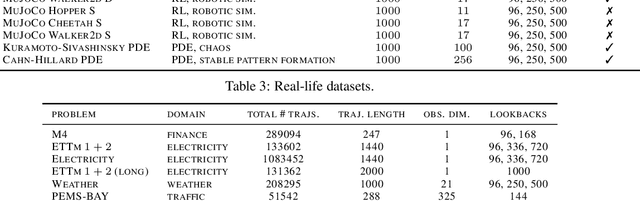
In order to support the advancement of machine learning methods for predicting time-series data, we present a comprehensive dataset designed explicitly for long-term time-series forecasting. We incorporate a collection of datasets obtained from diverse, dynamic systems and real-life records. Each dataset is standardized by dividing it into training and test trajectories with predetermined lookback lengths. We include trajectories of length up to $2000$ to ensure a reliable evaluation of long-term forecasting capabilities. To determine the most effective model in diverse scenarios, we conduct an extensive benchmarking analysis using classical and state-of-the-art models, namely LSTM, DeepAR, NLinear, N-Hits, PatchTST, and LatentODE. Our findings reveal intriguing performance comparisons among these models, highlighting the dataset-dependent nature of model effectiveness. Notably, we introduce a custom latent NLinear model and enhance DeepAR with a curriculum learning phase. Both consistently outperform their vanilla counterparts.
SpectralGPT: Spectral Foundation Model
Nov 13, 2023The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Adversarial Purification for Data-Driven Power System Event Classifiers with Diffusion Models
Nov 13, 2023The global deployment of the phasor measurement units (PMUs) enables real-time monitoring of the power system, which has stimulated considerable research into machine learning-based models for event detection and classification. However, recent studies reveal that machine learning-based methods are vulnerable to adversarial attacks, which can fool the event classifiers by adding small perturbations to the raw PMU data. To mitigate the threats posed by adversarial attacks, research on defense strategies is urgently needed. This paper proposes an effective adversarial purification method based on the diffusion model to counter adversarial attacks on the machine learning-based power system event classifier. The proposed method includes two steps: injecting noise into the PMU data; and utilizing a pre-trained neural network to eliminate the added noise while simultaneously removing perturbations introduced by the adversarial attacks. The proposed adversarial purification method significantly increases the accuracy of the event classifier under adversarial attacks while satisfying the requirements of real-time operations. In addition, the theoretical analysis reveals that the proposed diffusion model-based adversarial purification method decreases the distance between the original and compromised PMU data, which reduces the impacts of adversarial attacks. The empirical results on a large-scale real-world PMU dataset validate the effectiveness and computational efficiency of the proposed adversarial purification method.
SeaTurtleID2022: A long-span dataset for reliable sea turtle re-identification
Nov 09, 2023This paper introduces the first public large-scale, long-span dataset with sea turtle photographs captured in the wild -- SeaTurtleID2022 (https://www.kaggle.com/datasets/wildlifedatasets/seaturtleid2022). The dataset contains 8729 photographs of 438 unique individuals collected within 13 years, making it the longest-spanned dataset for animal re-identification. All photographs include various annotations, e.g., identity, encounter timestamp, and body parts segmentation masks. Instead of standard "random" splits, the dataset allows for two realistic and ecologically motivated splits: (i) a time-aware closed-set with training, validation, and test data from different days/years, and (ii) a time-aware open-set with new unknown individuals in test and validation sets. We show that time-aware splits are essential for benchmarking re-identification methods, as random splits lead to performance overestimation. Furthermore, a baseline instance segmentation and re-identification performance over various body parts is provided. Finally, an end-to-end system for sea turtle re-identification is proposed and evaluated. The proposed system based on Hybrid Task Cascade for head instance segmentation and ArcFace-trained feature-extractor achieved an accuracy of 86.8%.
DiffSCI: Zero-Shot Snapshot Compressive Imaging via Iterative Spectral Diffusion Model
Nov 19, 2023
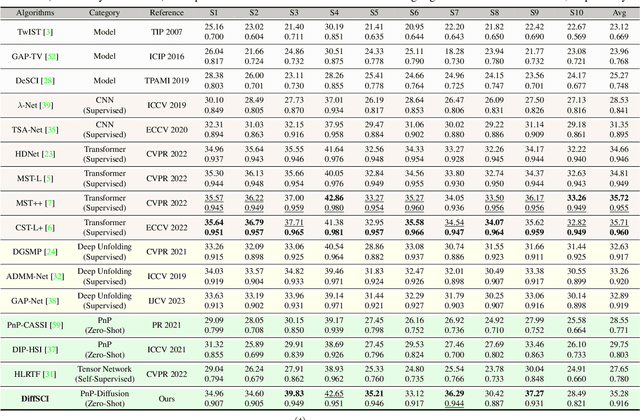
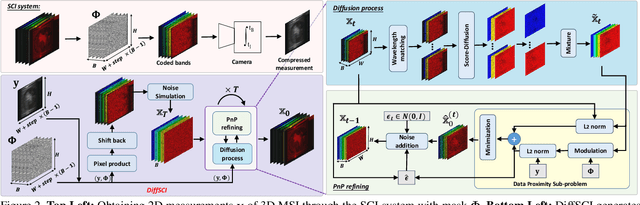
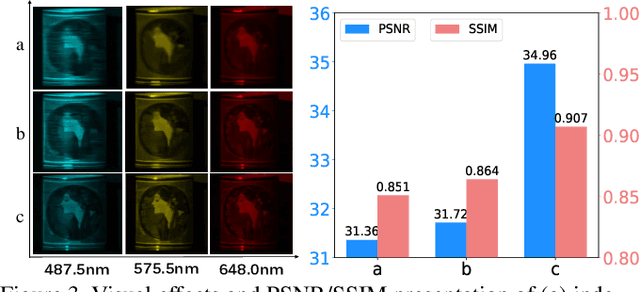
This paper endeavors to advance the precision of snapshot compressive imaging (SCI) reconstruction for multispectral image (MSI). To achieve this, we integrate the advantageous attributes of established SCI techniques and an image generative model, propose a novel structured zero-shot diffusion model, dubbed DiffSCI. DiffSCI leverages the structural insights from the deep prior and optimization-based methodologies, complemented by the generative capabilities offered by the contemporary denoising diffusion model. Specifically, firstly, we employ a pre-trained diffusion model, which has been trained on a substantial corpus of RGB images, as the generative denoiser within the Plug-and-Play framework for the first time. This integration allows for the successful completion of SCI reconstruction, especially in the case that current methods struggle to address effectively. Secondly, we systematically account for spectral band correlations and introduce a robust methodology to mitigate wavelength mismatch, thus enabling seamless adaptation of the RGB diffusion model to MSIs. Thirdly, an accelerated algorithm is implemented to expedite the resolution of the data subproblem. This augmentation not only accelerates the convergence rate but also elevates the quality of the reconstruction process. We present extensive testing to show that DiffSCI exhibits discernible performance enhancements over prevailing self-supervised and zero-shot approaches, surpassing even supervised transformer counterparts across both simulated and real datasets. Our code will be available.
RflyMAD: A Dataset for Multicopter Fault Detection and Health Assessment
Nov 19, 2023This paper presents an open-source dataset RflyMAD, a Multicopter Abnomal Dataset developed by Reliable Flight Control (Rfly) Group aiming to promote the development of research fields like fault detection and isolation (FDI) or health assessment (HA). The entire 114 GB dataset includes 11 types of faults under 6 flight statuses which are adapted from ADS-33 file to cover more occasions in which the multicopters have different mobility levels when faults occur. In the total 5629 flight cases, the fault time is up to 3283 minutes, and there are 2566 cases for software-in-the-loop (SIL) simulation, 2566 cases for hardware-in-the-loop (HIL) simulation and 497 cases for real flight. As it contains simulation data based on RflySim and real flight data, it is possible to improve the quantity while increasing the data quality. In each case, there are ULog, Telemetry log, Flight information and processed files for researchers to use and check. The RflyMAD dataset could be used as a benchmark for fault diagnosis methods and the support relationship between simulation data and real flight is verified through transfer learning methods. More methods as a baseline will be presented in the future, and RflyMAD will be updated with more data and types. In addition, the dataset and related toolkit can be accessed through https://rfly-openha.github.io/documents/4_resources/dataset.html.
Forecasting large collections of time series: feature-based methods
Sep 25, 2023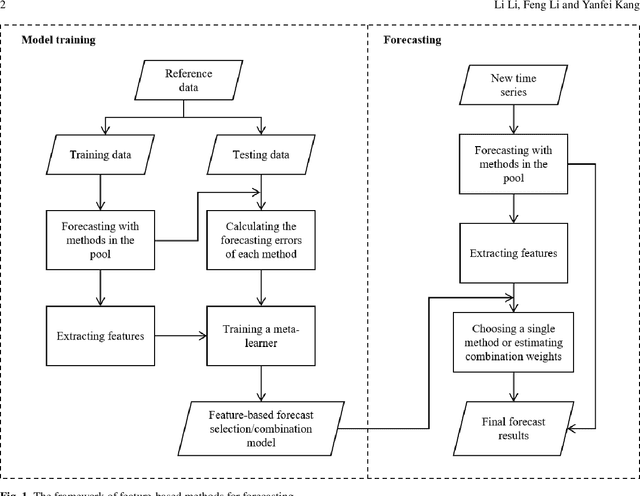
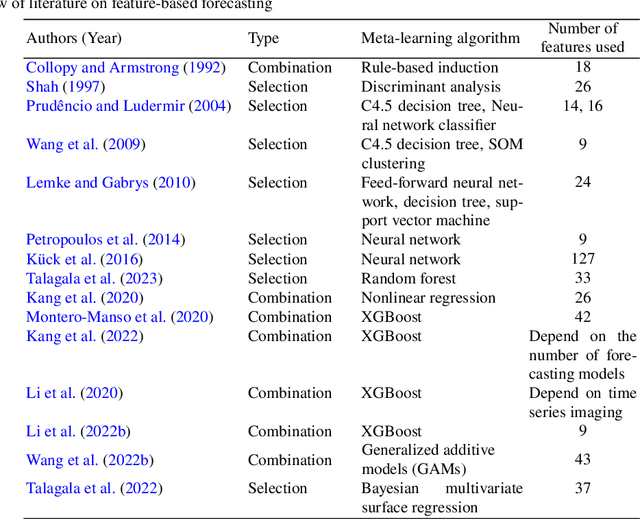
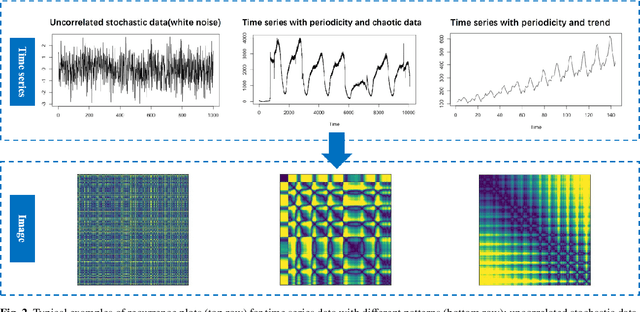
In economics and many other forecasting domains, the real world problems are too complex for a single model that assumes a specific data generation process. The forecasting performance of different methods changes depending on the nature of the time series. When forecasting large collections of time series, two lines of approaches have been developed using time series features, namely feature-based model selection and feature-based model combination. This chapter discusses the state-of-the-art feature-based methods, with reference to open-source software implementations.
EdgeFM: Leveraging Foundation Model for Open-set Learning on the Edge
Nov 18, 2023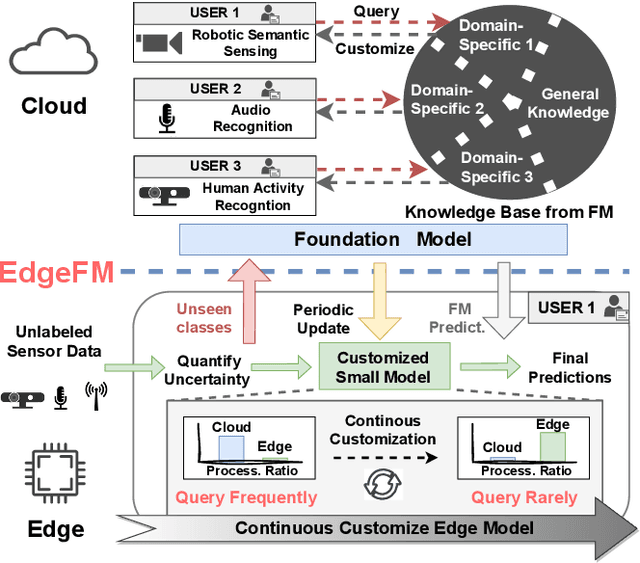
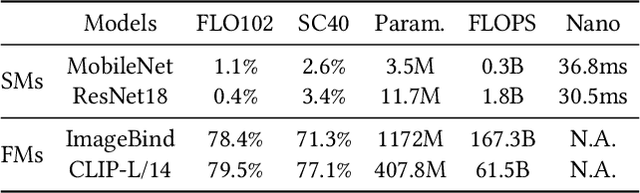
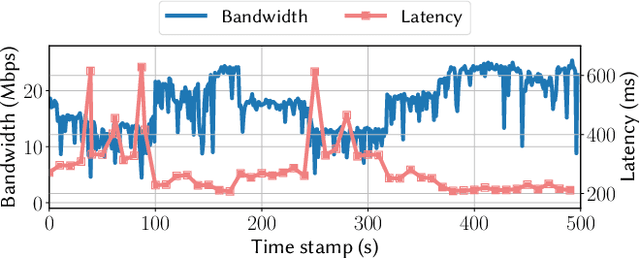
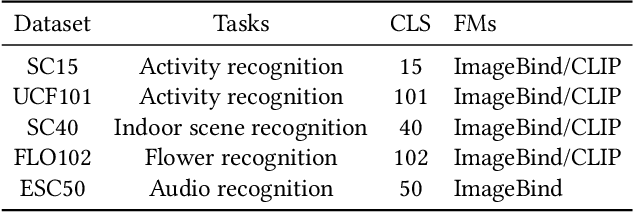
Deep Learning (DL) models have been widely deployed on IoT devices with the help of advancements in DL algorithms and chips. However, the limited resources of edge devices make these on-device DL models hard to be generalizable to diverse environments and tasks. Although the recently emerged foundation models (FMs) show impressive generalization power, how to effectively leverage the rich knowledge of FMs on resource-limited edge devices is still not explored. In this paper, we propose EdgeFM, a novel edge-cloud cooperative system with open-set recognition capability. EdgeFM selectively uploads unlabeled data to query the FM on the cloud and customizes the specific knowledge and architectures for edge models. Meanwhile, EdgeFM conducts dynamic model switching at run-time taking into account both data uncertainty and dynamic network variations, which ensures the accuracy always close to the original FM. We implement EdgeFM using two FMs on two edge platforms. We evaluate EdgeFM on three public datasets and two self-collected datasets. Results show that EdgeFM can reduce the end-to-end latency up to 3.2x and achieve 34.3% accuracy increase compared with the baseline.
Security Fence Inspection at Airports Using Object Detection
Nov 18, 2023To ensure the security of airports, it is essential to protect the airside from unauthorized access. For this purpose, security fences are commonly used, but they require regular inspection to detect damages. However, due to the growing shortage of human specialists and the large manual effort, there is the need for automated methods. The aim is to automatically inspect the fence for damage with the help of an autonomous robot. In this work, we explore object detection methods to address the fence inspection task and localize various types of damages. In addition to evaluating four State-of-the-Art (SOTA) object detection models, we analyze the impact of several design criteria, aiming at adapting to the task-specific challenges. This includes contrast adjustment, optimization of hyperparameters, and utilization of modern backbones. The experimental results indicate that our optimized You Only Look Once v5 (YOLOv5) model achieves the highest accuracy of the four methods with an increase of 6.9% points in Average Precision (AP) compared to the baseline. Moreover, we show the real-time capability of the model. The trained models are published on GitHub: https://github.com/N-Friederich/airport_fence_inspection.