 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ML KPI Prediction in 5G and B5G Networks
Apr 01, 2024
Network operators are facing new challenges when meeting the needs of their customers. The challenges arise due to the rise of new services, such as HD video streaming, IoT, autonomous driving, etc., and the exponential growth of network traffic. In this context, 5G and B5G networks have been evolving to accommodate a wide range of applications and use cases. Additionally, this evolution brings new features, like the ability to create multiple end-to-end isolated virtual networks using network slicing. Nevertheless, to ensure the quality of service, operators must maintain and optimize their networks in accordance with the key performance indicators (KPIs) and the slice service-level agreements (SLAs). In this paper, we introduce a machine learning (ML) model used to estimate throughput in 5G and B5G networks with end-to-end (E2E) network slices. Then, we combine the predicted throughput with the current network state to derive an estimate of other network KPIs, which can be used to further improve service assurance. To assess the efficiency of our solution, a performance metric was proposed. Numerical evaluations demonstrate that our KPI prediction model outperforms those derived from other methods with the same or nearly the same computational time.
Large Language Models are Capable of Offering Cognitive Reappraisal, if Guided
Apr 01, 2024Large language models (LLMs) have offered new opportunities for emotional support, and recent work has shown that they can produce empathic responses to people in distress. However, long-term mental well-being requires emotional self-regulation, where a one-time empathic response falls short. This work takes a first step by engaging with cognitive reappraisals, a strategy from psychology practitioners that uses language to targetedly change negative appraisals that an individual makes of the situation; such appraisals is known to sit at the root of human emotional experience. We hypothesize that psychologically grounded principles could enable such advanced psychology capabilities in LLMs, and design RESORT which consists of a series of reappraisal constitutions across multiple dimensions that can be used as LLM instructions. We conduct a first-of-its-kind expert evaluation (by clinical psychologists with M.S. or Ph.D. degrees) of an LLM's zero-shot ability to generate cognitive reappraisal responses to medium-length social media messages asking for support. This fine-grained evaluation showed that even LLMs at the 7B scale guided by RESORT are capable of generating empathic responses that can help users reappraise their situations.
A Unified and Interpretable Emotion Representation and Expression Generation
Apr 01, 2024Canonical emotions, such as happy, sad, and fearful, are easy to understand and annotate. However, emotions are often compound, e.g. happily surprised, and can be mapped to the action units (AUs) used for expressing emotions, and trivially to the canonical ones. Intuitively, emotions are continuous as represented by the arousal-valence (AV) model. An interpretable unification of these four modalities - namely, Canonical, Compound, AUs, and AV - is highly desirable, for a better representation and understanding of emotions. However, such unification remains to be unknown in the current literature. In this work, we propose an interpretable and unified emotion model, referred as C2A2. We also develop a method that leverages labels of the non-unified models to annotate the novel unified one. Finally, we modify the text-conditional diffusion models to understand continuous numbers, which are then used to generate continuous expressions using our unified emotion model. Through quantitative and qualitative experiments, we show that our generated images are rich and capture subtle expressions. Our work allows a fine-grained generation of expressions in conjunction with other textual inputs and offers a new label space for emotions at the same time.
Effectively Prompting Small-sized Language Models for Cross-lingual Tasks via Winning Tickets
Apr 01, 2024Current soft prompt methods yield limited performance when applied to small-sized models (fewer than a billion parameters). Deep prompt-tuning, which entails prepending parameters in each layer for enhanced efficacy, presents a solution for prompting small-sized models, albeit requiring carefully designed implementation. In this paper, we introduce the Lottery Ticket Prompt-learning (LTP) framework that integrates winning tickets with soft prompts. The LTP offers a simpler implementation and requires only a one-time execution. We demonstrate LTP on cross-lingual tasks, where prior works rely on external tools like human-designed multilingual templates and bilingual dictionaries, which may not be feasible in a low-resource regime. Specifically, we select a subset of parameters that have been changed the most during the fine-tuning with the Masked Language Modeling objective. Then, we prepend soft prompts to the original pre-trained language model and only update the selected parameters together with prompt-related parameters when adapting to the downstream tasks. We verify the effectiveness of our LTP framework on cross-lingual tasks, specifically targeting low-resource languages. Our approach outperforms the baselines by only updating 20\% of the original parameters.
Towards Real-Time Fast Unmanned Aerial Vehicle Detection Using Dynamic Vision Sensors
Mar 18, 2024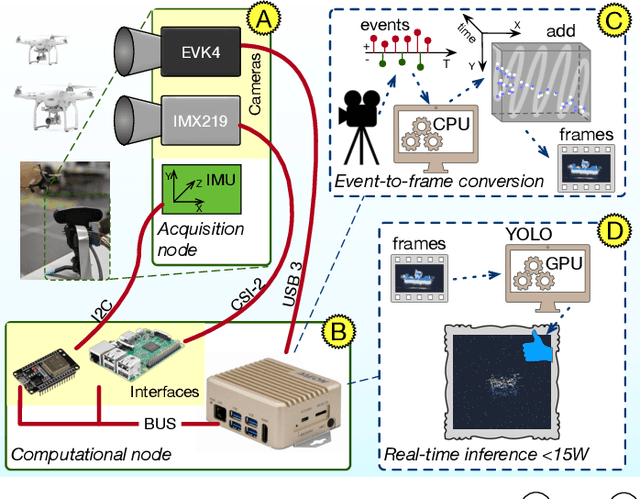



Unmanned Aerial Vehicles (UAVs) are gaining popularity in civil and military applications. However, uncontrolled access to restricted areas threatens privacy and security. Thus, prevention and detection of UAVs are pivotal to guarantee confidentiality and safety. Although active scanning, mainly based on radars, is one of the most accurate technologies, it can be expensive and less versatile than passive inspections, e.g., object recognition. Dynamic vision sensors (DVS) are bio-inspired event-based vision models that leverage timestamped pixel-level brightness changes in fast-moving scenes that adapt well to low-latency object detection. This paper presents F-UAV-D (Fast Unmanned Aerial Vehicle Detector), an embedded system that enables fast-moving drone detection. In particular, we propose a setup to exploit DVS as an alternative to RGB cameras in a real-time and low-power configuration. Our approach leverages the high-dynamic range (HDR) and background suppression of DVS and, when trained with various fast-moving drones, outperforms RGB input in suboptimal ambient conditions such as low illumination and fast-moving scenes. Our results show that F-UAV-D can (i) detect drones by using less than <15 W on average and (ii) perform real-time inference (i.e., <50 ms) by leveraging the CPU and GPU nodes of our edge computer.
Audiosockets: A Python socket package for Real-Time Audio Processing
Mar 14, 2024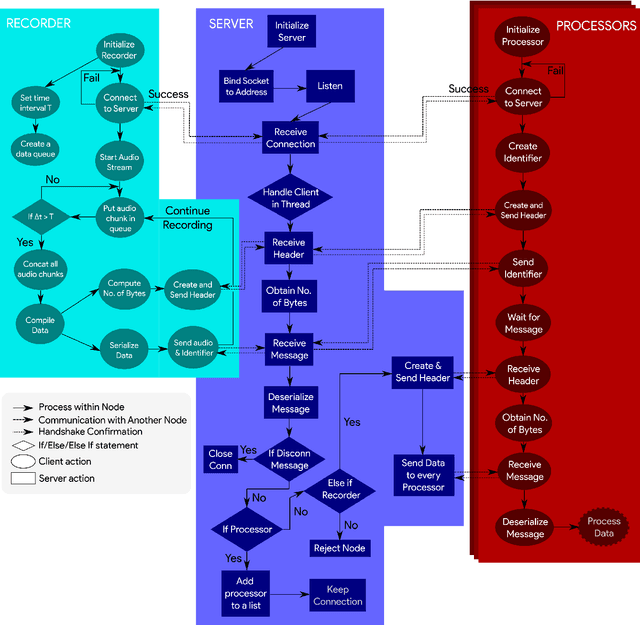
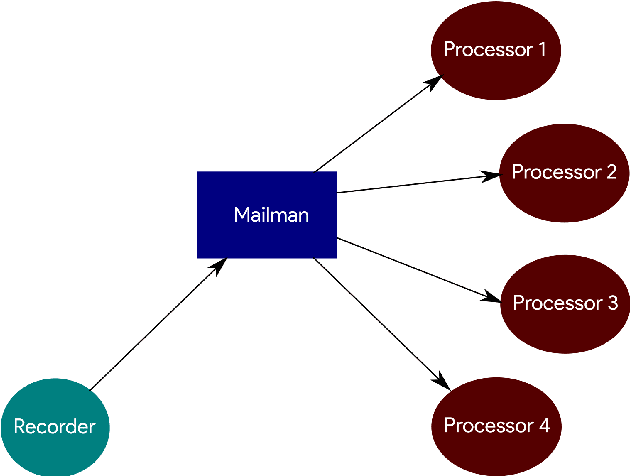
There are many packages in Python which allow one to perform real-time processing on audio data. Unfortunately, due to the synchronous nature of the language, there lacks a framework which allows for distributed parallel processing of the data without requiring a large programming overhead and in which the data acquisition is not blocked by subsequent processing operations. This work improves on packages used for audio data collection with a light-weight backend and a simple interface that allows for distributed processing through a socket-based structure. This is intended for real-time audio machine learning and data processing in Python with a quick deployment of multiple parallel operations on the same data, allowing users to spend less time debugging and more time developing.
Just Shift It: Test-Time Prototype Shifting for Zero-Shot Generalization with Vision-Language Models
Mar 19, 2024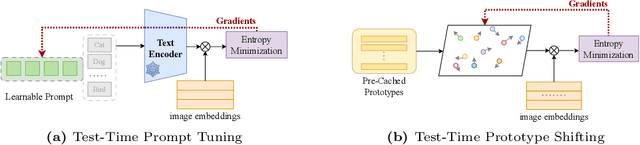
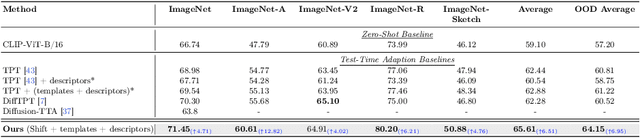
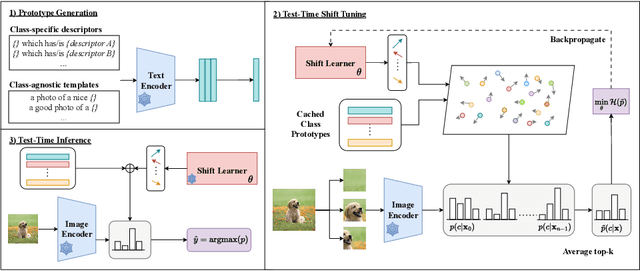

Advancements in vision-language models (VLMs) have propelled the field of computer vision, particularly in the zero-shot learning setting. Despite their promise, the effectiveness of these models often diminishes due to domain shifts in test environments. To address this, we introduce the Test-Time Prototype Shifting (TPS) framework, a pioneering approach designed to adapt VLMs to test datasets using unlabeled test inputs. Our method is based on the notion of modulating per-class prototypes in the shared embedding space. By pre-computing and caching prototypes generated with the pre-trained text encoder, TPS not only facilitates optimization-free prototype reuse for subsequent predictions but also enables seamless integration with current advancements in prompt engineering. At test-time, TPS dynamically learns shift vectors for each prototype based solely on the given test sample, effectively bridging the domain gap and enhancing classification accuracy. A notable aspect of our framework is its significantly reduced memory and computational demands when compared to conventional text-prompt tuning methods. Extensive evaluations across 15 datasets involving natural distribution shifts and cross-dataset generalization demonstrate TPS's superior performance, achieving state-of-the-art results while reducing resource requirements.
On Difficulties of Attention Factorization through Shared Memory
Mar 31, 2024Transformers have revolutionized deep learning in numerous fields, including natural language processing, computer vision, and audio processing. Their strength lies in their attention mechanism, which allows for the discovering of complex input relationships. However, this mechanism's quadratic time and memory complexity pose challenges for larger inputs. Researchers are now investigating models like Linear Unified Nested Attention (Luna) or Memory Augmented Transformer, which leverage external learnable memory to either reduce the attention computation complexity down to linear, or to propagate information between chunks in chunk-wise processing. Our findings challenge the conventional thinking on these models, revealing that interfacing with the memory directly through an attention operation is suboptimal, and that the performance may be considerably improved by filtering the input signal before communicating with memory.
Resolution Limit of Single-Photon LiDAR
Mar 31, 2024Single-photon Light Detection and Ranging (LiDAR) systems are often equipped with an array of detectors for improved spatial resolution and sensing speed. However, given a fixed amount of flux produced by the laser transmitter across the scene, the per-pixel Signal-to-Noise Ratio (SNR) will decrease when more pixels are packed in a unit space. This presents a fundamental trade-off between the spatial resolution of the sensor array and the SNR received at each pixel. Theoretical characterization of this fundamental limit is explored. By deriving the photon arrival statistics and introducing a series of new approximation techniques, the Mean Squared Error (MSE) of the maximum-likelihood estimator of the time delay is derived. The theoretical predictions align well with simulations and real data.
MCformer: Multivariate Time Series Forecasting with Mixed-Channels Transformer
Mar 14, 2024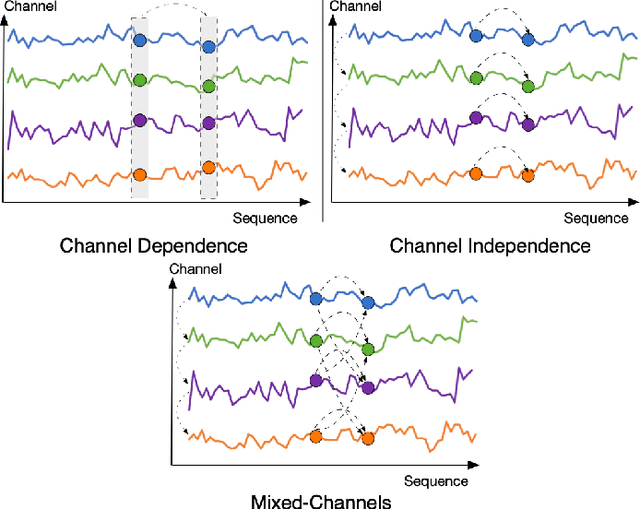

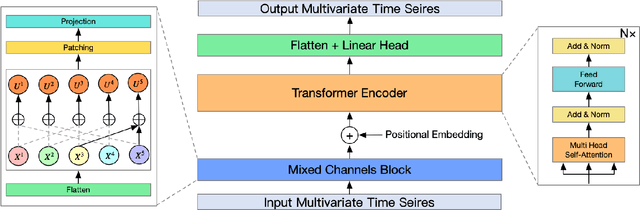

The massive generation of time-series data by largescale Internet of Things (IoT) devices necessitates the exploration of more effective models for multivariate time-series forecasting. In previous models, there was a predominant use of the Channel Dependence (CD) strategy (where each channel represents a univariate sequence). Current state-of-the-art (SOTA) models primarily rely on the Channel Independence (CI) strategy. The CI strategy treats all channels as a single channel, expanding the dataset to improve generalization performance and avoiding inter-channel correlation that disrupts long-term features. However, the CI strategy faces the challenge of interchannel correlation forgetting. To address this issue, we propose an innovative Mixed Channels strategy, combining the data expansion advantages of the CI strategy with the ability to counteract inter-channel correlation forgetting. Based on this strategy, we introduce MCformer, a multivariate time-series forecasting model with mixed channel features. The model blends a specific number of channels, leveraging an attention mechanism to effectively capture inter-channel correlation information when modeling long-term features. Experimental results demonstrate that the Mixed Channels strategy outperforms pure CI strategy in multivariate time-series forecasting tasks.