 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SwiftLearn: A Data-Efficient Training Method of Deep Learning Models using Importance Sampling
Nov 25, 2023
In this paper, we present SwiftLearn, a data-efficient approach to accelerate training of deep learning models using a subset of data samples selected during the warm-up stages of training. This subset is selected based on an importance criteria measured over the entire dataset during warm-up stages, aiming to preserve the model performance with fewer examples during the rest of training. The importance measure we propose could be updated during training every once in a while, to make sure that all of the data samples have a chance to return to the training loop if they show a higher importance. The model architecture is unchanged but since the number of data samples controls the number of forward and backward passes during training, we can reduce the training time by reducing the number of training samples used in each epoch of training. Experimental results on a variety of CV and NLP models during both pretraining and finetuning show that the model performance could be preserved while achieving a significant speed-up during training. More specifically, BERT finetuning on GLUE benchmark shows that almost 90% of the data can be dropped achieving an end-to-end average speedup of 3.36x while keeping the average accuracy drop less than 0.92%.
Unbalancedness in Neural Monge Maps Improves Unpaired Domain Translation
Nov 25, 2023In optimal transport (OT), a Monge map is known as a mapping that transports a source distribution to a target distribution in the most cost-efficient way. Recently, multiple neural estimators for Monge maps have been developed and applied in diverse unpaired domain translation tasks, e.g. in single-cell biology and computer vision. However, the classic OT framework enforces mass conservation, which makes it prone to outliers and limits its applicability in real-world scenarios. The latter can be particularly harmful in OT domain translation tasks, where the relative position of a sample within a distribution is explicitly taken into account. While unbalanced OT tackles this challenge in the discrete setting, its integration into neural Monge map estimators has received limited attention. We propose a theoretically grounded method to incorporate unbalancedness into any Monge map estimator. We improve existing estimators to model cell trajectories over time and to predict cellular responses to perturbations. Moreover, our approach seamlessly integrates with the OT flow matching (OT-FM) framework. While we show that OT-FM performs competitively in image translation, we further improve performance by incorporating unbalancedness (UOT-FM), which better preserves relevant features. We hence establish UOT-FM as a principled method for unpaired image translation.
Introducing SSBD+ Dataset with a Convolutional Pipeline for detecting Self-Stimulatory Behaviours in Children using raw videos
Nov 25, 2023Conventionally, evaluation for the diagnosis of Autism spectrum disorder is done by a trained specialist through questionnaire-based formal assessments and by observation of behavioral cues under various settings to capture the early warning signs of autism. These evaluation techniques are highly subjective and their accuracy relies on the experience of the specialist. In this regard, machine learning-based methods for automated capturing of early signs of autism from the recorded videos of the children is a promising alternative. In this paper, the authors propose a novel pipelined deep learning architecture to detect certain self-stimulatory behaviors that help in the diagnosis of autism spectrum disorder (ASD). The authors also supplement their tool with an augmented version of the Self Stimulatory Behavior Dataset (SSBD) and also propose a new label in SSBD Action detection: no-class. The deep learning model with the new dataset is made freely available for easy adoption to the researchers and developers community. An overall accuracy of around 81% was achieved from the proposed pipeline model that is targeted for real-time and hands-free automated diagnosis. All of the source code, data, licenses of use, and other relevant material is made freely available in https://github.com/sarl-iiitb/
Key Issues in Wireless Transmission for NTN-Assisted Internet of Things
Nov 25, 2023Non-terrestrial networks (NTNs) have become appealing resolutions for seamless coverage in the next-generation wireless transmission, where a large number of Internet of Things (IoT) devices diversely distributed can be efficiently served. The explosively growing number of IoT devices brings a new challenge for massive connection. The long-distance wireless signal propagation in NTNs leads to severe path loss and large latency, where the accurate acquisition of channel state information (CSI) is another challenge, especially for fast-moving non-terrestrial base stations (NTBSs). Moreover, the scarcity of on-board resources of NTBSs is also a challenge for resource allocation. To this end, we investigate three key issues, where the existing schemes and emerging resolutions for these three key issues have been comprehensively presented. The first issue is to enable the massive connection by designing random access to establish the wireless link and multiple access to transmit data streams. The second issue is to accurately acquire CSI in various channel conditions by channel estimation and beam training, where orthogonal time frequency space modulation and dynamic codebooks are on focus. The third issue is to efficiently allocate the wireless resources, including power allocation, spectrum sharing, beam hopping, and beamforming. At the end of this article, some future research topics are identified.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.
Some Like It Small: Czech Semantic Embedding Models for Industry Applications
Nov 23, 2023This article focuses on the development and evaluation of Small-sized Czech sentence embedding models. Small models are important components for real-time industry applications in resource-constrained environments. Given the limited availability of labeled Czech data, alternative approaches, including pre-training, knowledge distillation, and unsupervised contrastive fine-tuning, are investigated. Comprehensive intrinsic and extrinsic analyses are conducted, showcasing the competitive performance of our models compared to significantly larger counterparts, with approximately 8 times smaller size and 5 times faster speed than conventional Base-sized models. To promote cooperation and reproducibility, both the models and the evaluation pipeline are made publicly accessible. Ultimately, this article presents practical applications of the developed sentence embedding models in Seznam.cz, the Czech search engine. These models have effectively replaced previous counterparts, enhancing the overall search experience for instance, in organic search, featured snippets, and image search. This transition has yielded improved performance.
Locally Optimal Descent for Dynamic Stepsize Scheduling
Nov 23, 2023We introduce a novel dynamic learning-rate scheduling scheme grounded in theory with the goal of simplifying the manual and time-consuming tuning of schedules in practice. Our approach is based on estimating the locally-optimal stepsize, guaranteeing maximal descent in the direction of the stochastic gradient of the current step. We first establish theoretical convergence bounds for our method within the context of smooth non-convex stochastic optimization, matching state-of-the-art bounds while only assuming knowledge of the smoothness parameter. We then present a practical implementation of our algorithm and conduct systematic experiments across diverse datasets and optimization algorithms, comparing our scheme with existing state-of-the-art learning-rate schedulers. Our findings indicate that our method needs minimal tuning when compared to existing approaches, removing the need for auxiliary manual schedules and warm-up phases and achieving comparable performance with drastically reduced parameter tuning.
Function-constrained Program Synthesis
Nov 27, 2023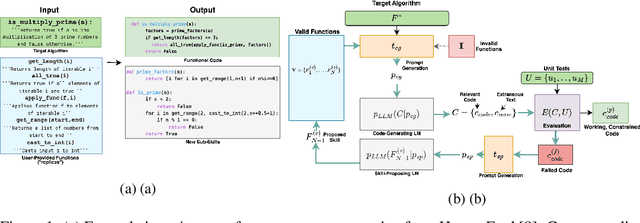



This work introduces (1) a technique that allows large language models (LLMs) to leverage user-provided code when solving programming tasks and (2) a method to iteratively generate modular sub-functions that can aid future code generation attempts when the initial code generated by the LLM is inadequate. Generating computer programs in general-purpose programming languages like Python poses a challenge for LLMs when instructed to use code provided in the prompt. Code-specific LLMs (e.g., GitHub Copilot, CodeLlama2) can generate code completions in real-time by drawing on all code available in a development environment. However, restricting code-specific LLMs to use only in-context code is not straightforward, as the model is not explicitly instructed to use the user-provided code and users cannot highlight precisely which snippets of code the model should incorporate into its context. Moreover, current systems lack effective recovery methods, forcing users to iteratively re-prompt the model with modified prompts until a sufficient solution is reached. Our method differs from traditional LLM-powered code-generation by constraining code-generation to an explicit function set and enabling recovery from failed attempts through automatically generated sub-functions. When the LLM cannot produce working code, we generate modular sub-functions to aid subsequent attempts at generating functional code. A by-product of our method is a library of reusable sub-functions that can solve related tasks, imitating a software team where efficiency scales with experience. We also introduce a new "half-shot" evaluation paradigm that provides tighter estimates of LLMs' coding abilities compared to traditional zero-shot evaluation. Our proposed evaluation method encourages models to output solutions in a structured format, decreasing syntax errors that can be mistaken for poor coding ability.
Spatio-Temporal Graph Neural Point Process for Traffic Congestion Event Prediction
Nov 15, 2023Traffic congestion event prediction is an important yet challenging task in intelligent transportation systems. Many existing works about traffic prediction integrate various temporal encoders and graph convolution networks (GCNs), called spatio-temporal graph-based neural networks, which focus on predicting dense variables such as flow, speed and demand in time snapshots, but they can hardly forecast the traffic congestion events that are sparsely distributed on the continuous time axis. In recent years, neural point process (NPP) has emerged as an appropriate framework for event prediction in continuous time scenarios. However, most conventional works about NPP cannot model the complex spatio-temporal dependencies and congestion evolution patterns. To address these limitations, we propose a spatio-temporal graph neural point process framework, named STGNPP for traffic congestion event prediction. Specifically, we first design the spatio-temporal graph learning module to fully capture the long-range spatio-temporal dependencies from the historical traffic state data along with the road network. The extracted spatio-temporal hidden representation and congestion event information are then fed into a continuous gated recurrent unit to model the congestion evolution patterns. In particular, to fully exploit the periodic information, we also improve the intensity function calculation of the point process with a periodic gated mechanism. Finally, our model simultaneously predicts the occurrence time and duration of the next congestion. Extensive experiments on two real-world datasets demonstrate that our method achieves superior performance in comparison to existing state-of-the-art approaches.
Path Planning in 3D with Motion Primitives for Wind Energy-Harvesting Fixed-Wing Aircraft
Nov 17, 2023In this work, a set of motion primitives is defined for use in an energy-aware motion planning problem. The motion primitives are defined as sequences of control inputs to a simplified four-DOF dynamics model and are used to replace the traditional continuous control space used in many sampling-based motion planners. The primitives are implemented in a Stable Sparse Rapidly Exploring Random Tree (SST) motion planner and compared to an identical planner using a continuous control space. The planner using primitives was found to run 11.0\% faster but yielded solution paths that were on average worse with higher variance. Also, the solution path travel time is improved by about 50\%. Using motion primitives for sampling spaces in SST can effectively reduce the run time of the algorithm, although at the cost of solution quality.