 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Missing Value Imputation for Multi-attribute Sensor Data Streams via Message Propagation (Extended Version)
Nov 14, 2023
Sensor data streams occur widely in various real-time applications in the context of the Internet of Things (IoT). However, sensor data streams feature missing values due to factors such as sensor failures, communication errors, or depleted batteries. Missing values can compromise the quality of real-time analytics tasks and downstream applications. Existing imputation methods either make strong assumptions about streams or have low efficiency. In this study, we aim to accurately and efficiently impute missing values in data streams that satisfy only general characteristics in order to benefit real-time applications more widely. First, we propose a message propagation imputation network (MPIN) that is able to recover the missing values of data instances in a time window. We give a theoretical analysis of why MPIN is effective. Second, we present a continuous imputation framework that consists of data update and model update mechanisms to enable MPIN to perform continuous imputation both effectively and efficiently. Extensive experiments on multiple real datasets show that MPIN can outperform the existing data imputers by wide margins and that the continuous imputation framework is efficient and accurate.
Point Projection Mapping System for Tracking, Registering, Labeling and Validating Optical Tissue Measurements
Nov 22, 2023Validation of newly developed optical tissue sensing techniques for tumor detection during cancer surgery requires an accurate correlation with histological results. Additionally, such accurate correlation facilitates precise data labeling for developing high-performance machine-learning tissue classification models. In this paper, a newly developed Point Projection Mapping system will be introduced, which allows non-destructive tracking of the measurement locations on tissue specimens. Additionally, a framework for accurate registration, validation, and labeling with histopathology results is proposed and validated on a case study. The proposed framework provides a more robust and accurate method for tracking and validation of optical tissue sensing techniques, which saves time and resources compared to conventional techniques available.
TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
Oct 10, 2023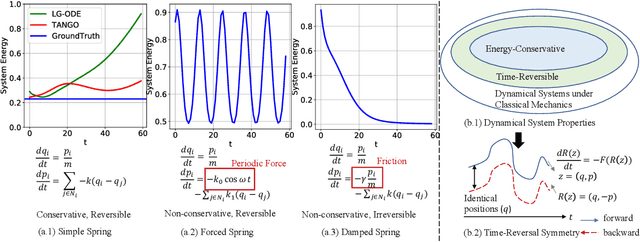
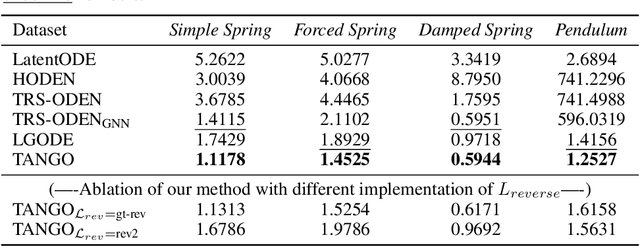
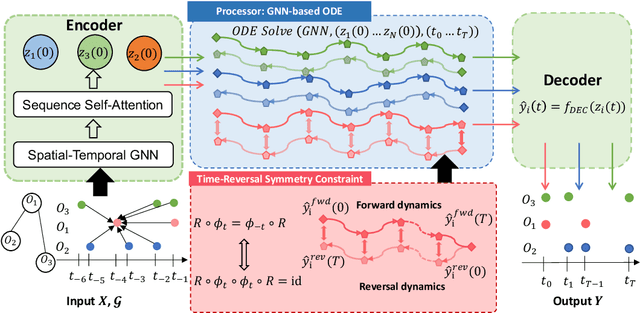
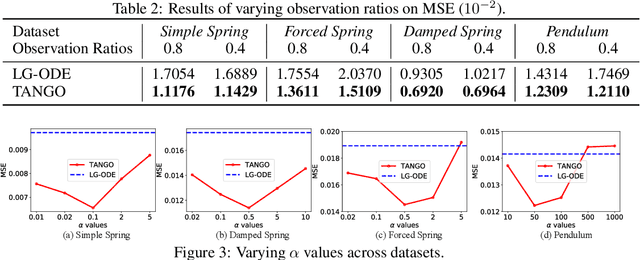
Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Nov 27, 2023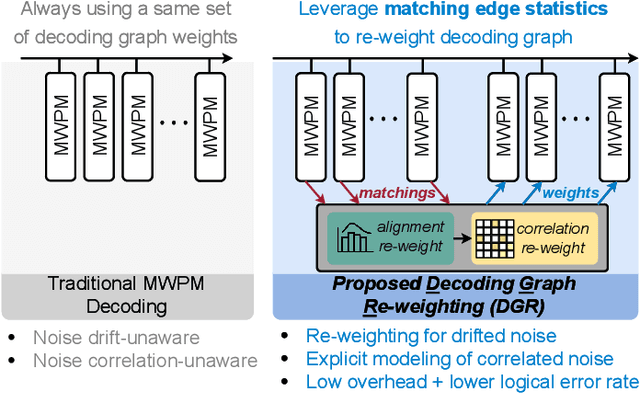
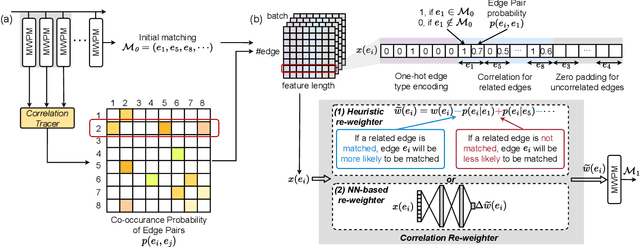
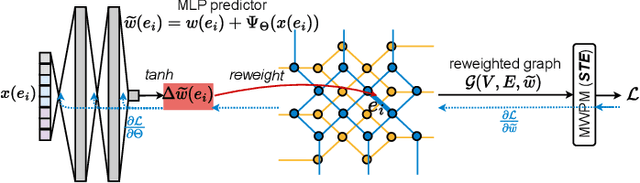
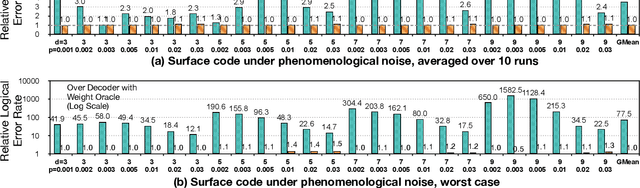
Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
SpotServe: Serving Generative Large Language Models on Preemptible Instances
Nov 27, 2023The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them cheaply. This paper aims to reduce the monetary cost for serving LLMs by leveraging preemptible GPU instances on modern clouds, which offer accesses to spare GPUs at a much cheaper price than regular instances but may be preempted by the cloud at any time. Serving LLMs on preemptible instances requires addressing challenges induced by frequent instance preemptions and the necessity of migrating instances to handle these preemptions. This paper presents SpotServe, the first distributed LLM serving system on preemptible instances. Several key techniques in SpotServe realize fast and reliable serving of generative LLMs on cheap preemptible instances. First, SpotServe dynamically adapts the LLM parallelization configuration for dynamic instance availability and fluctuating workload, while balancing the trade-off among the overall throughput, inference latency and monetary costs. Second, to minimize the cost of migrating instances for dynamic reparallelization, the task of migrating instances is formulated as a bipartite graph matching problem, which uses the Kuhn-Munkres algorithm to identify an optimal migration plan that minimizes communications. Finally, to take advantage of the grace period offered by modern clouds, we introduce stateful inference recovery, a new inference mechanism that commits inference progress at a much finer granularity and allows SpotServe to cheaply resume inference upon preemption. We evaluate on real spot instance preemption traces and various popular LLMs and show that SpotServe can reduce the P99 tail latency by 2.4 - 9.1x compared with the best existing LLM serving systems. We also show that SpotServe can leverage the price advantage of preemptive instances, saving 54% monetary cost compared with only using on-demand instances.
Ultra-short-term multi-step wind speed prediction for wind farms based on adaptive noise reduction technology and temporal convolutional network
Nov 27, 2023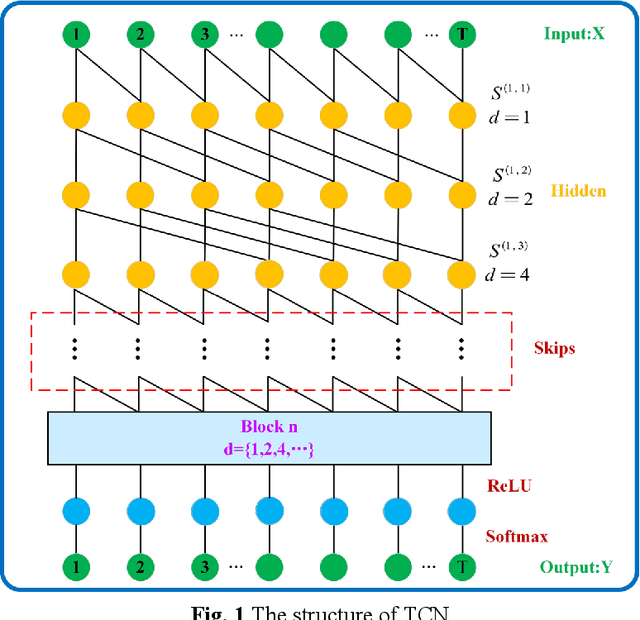
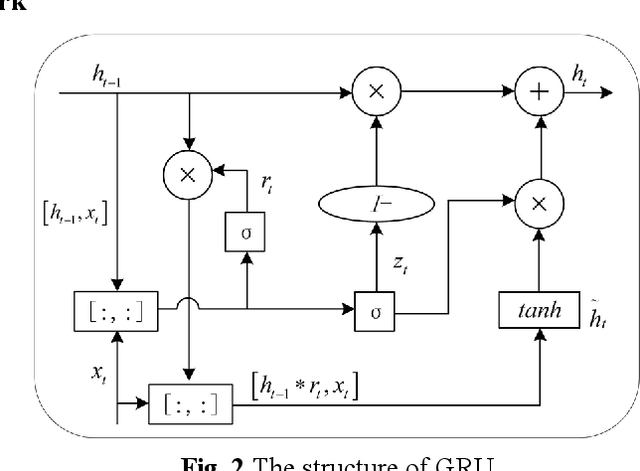

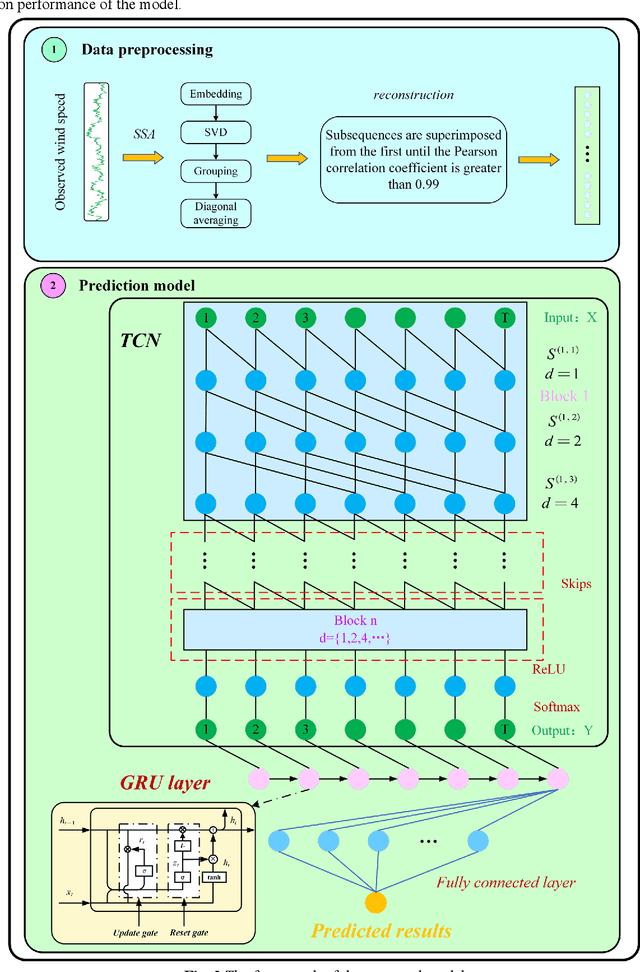
As an important clean and renewable kind of energy, wind power plays an important role in coping with energy crisis and environmental pollution. However, the volatility and intermittency of wind speed restrict the development of wind power. To improve the utilization of wind power, this study proposes a new wind speed prediction model based on data noise reduction technology, temporal convolutional network (TCN), and gated recurrent unit (GRU). Firstly, an adaptive data noise reduction algorithm P-SSA is proposed based on singular spectrum analysis (SSA) and Pearson correlation coefficient. The original wind speed is decomposed into multiple subsequences by SSA and then reconstructed. When the Pearson correlation coefficient between the reconstructed sequence and the original sequence is greater than 0.99, other noise subsequences are deleted to complete the data denoising. Then, the receptive field of the samples is expanded through the causal convolution and dilated convolution of TCN, and the characteristics of wind speed change are extracted. Then, the time feature information of the sequence is extracted by GRU, and then the wind speed is predicted to form the wind speed sequence prediction model of P-SSA-TCN-GRU. The proposed model was validated on three wind farms in Shandong Province. The experimental results show that the prediction performance of the proposed model is better than that of the traditional model and other models based on TCN, and the wind speed prediction of wind farms with high precision and strong stability is realized. The wind speed predictions of this model have the potential to become the data that support the operation and management of wind farms. The code is available at link.
Fast Policy Learning for Linear Quadratic Regulator with Entropy Regularization
Nov 23, 2023This paper proposes and analyzes two new policy learning methods: regularized policy gradient (RPG) and iterative policy optimization (IPO), for a class of discounted linear-quadratic regulator (LQR) problems over an infinite time horizon with entropy regularization. Assuming access to the exact policy evaluation, both proposed approaches are proved to converge linearly in finding optimal policies of the regularized LQR. Moreover, the IPO method can achieve a super-linear convergence rate once it enters a local region around the optimal policy. Finally, when the optimal policy from a well-understood environment in an RL problem is appropriately transferred as the initial policy to an RL problem with an unknown environment, the IPO method is shown to enable a super-linear convergence rate if the latter is sufficiently close to the former. The performances of these proposed algorithms are supported by numerical examples.
Introducing the Attribution Stability Indicator: a Measure for Time Series XAI Attributions
Oct 06, 2023
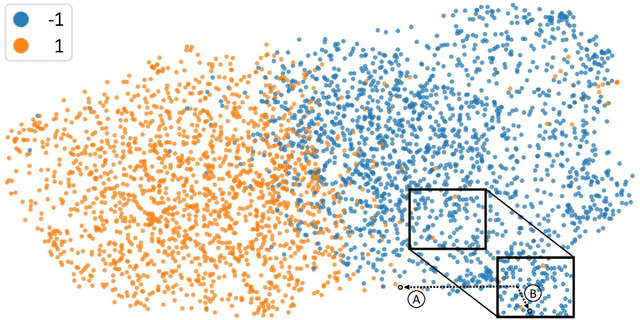
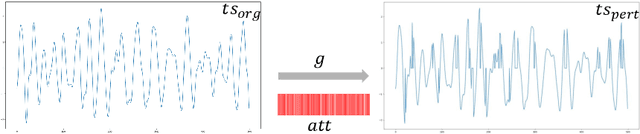

Given the increasing amount and general complexity of time series data in domains such as finance, weather forecasting, and healthcare, there is a growing need for state-of-the-art performance models that can provide interpretable insights into underlying patterns and relationships. Attribution techniques enable the extraction of explanations from time series models to gain insights but are hard to evaluate for their robustness and trustworthiness. We propose the Attribution Stability Indicator (ASI), a measure to incorporate robustness and trustworthiness as properties of attribution techniques for time series into account. We extend a perturbation analysis with correlations of the original time series to the perturbed instance and the attributions to include wanted properties in the measure. We demonstrate the wanted properties based on an analysis of the attributions in a dimension-reduced space and the ASI scores distribution over three whole time series classification datasets.
"HoVer-UNet": Accelerating HoVerNet with UNet-based multi-class nuclei segmentation via knowledge distillation
Nov 21, 2023We present "HoVer-UNet", an approach to distill the knowledge of the multi-branch HoVerNet framework for nuclei instance segmentation and classification in histopathology. We propose a compact, streamlined single UNet network with a Mix Vision Transformer backbone, and equip it with a custom loss function to optimally encode the distilled knowledge of HoVerNet, reducing computational requirements without compromising performances. We show that our model achieved results comparable to HoVerNet on the public PanNuke and Consep datasets with a three-fold reduction in inference time. We make the code of our model publicly available at https://github.com/DIAGNijmegen/HoVer-UNet.