 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Agent Combinatorial Path Finding with Heterogeneous Task Duration
Nov 26, 2023
Multi-Agent Combinatorial Path Finding (MCPF) seeks collision-free paths for multiple agents from their initial locations to destinations, visiting a set of intermediate target locations in the middle of the paths, while minimizing the sum of arrival times. While a few approaches have been developed to handle MCPF, most of them simply direct the agent to visit the targets without considering the task duration, i.e., the amount of time needed for an agent to execute the task (such as picking an item) at a target location. MCPF is NP-hard to solve to optimality, and the inclusion of task duration further complicates the problem. This paper investigates heterogeneous task duration, where the duration can be different with respect to both the agents and targets. We develop two methods, where the first method post-processes the paths planned by any MCPF planner to include the task duration and has no solution optimality guarantee; and the second method considers task duration during planning and is able to ensure solution optimality. The numerical and simulation results show that our methods can handle up to 20 agents and 50 targets in the presence of task duration, and can execute the paths subject to robot motion disturbance.
Edge Accelerated Robot Navigation with Hierarchical Motion Planning
Nov 15, 2023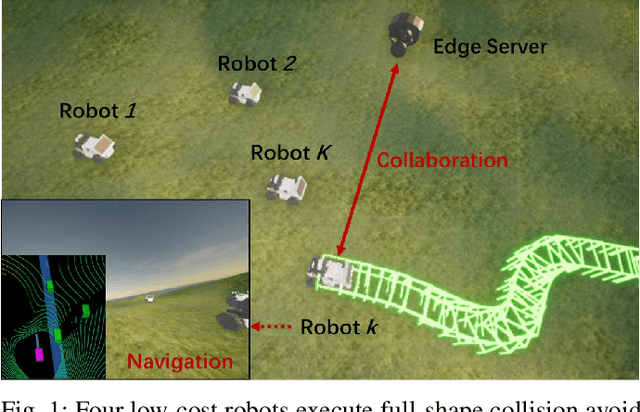
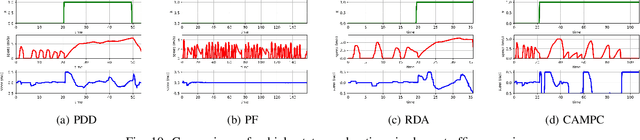
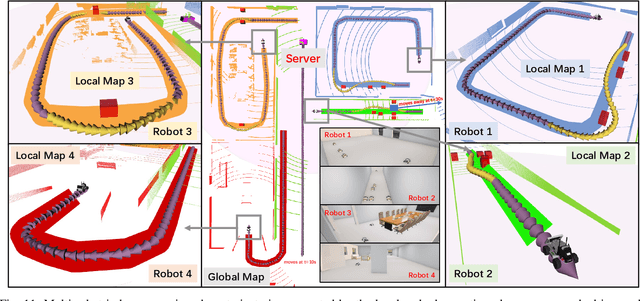
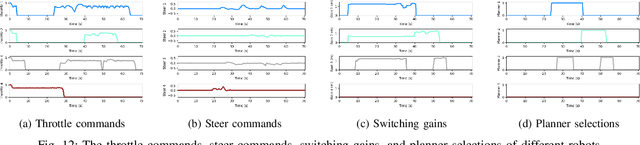
Low-cost autonomous robots suffer from limited onboard computing power, resulting in excessive computation time when navigating in cluttered environments. This paper presents Edge Accelerated Robot Navigation, or EARN for short, to achieve real-time collision avoidance by adopting hierarchical motion planning (HMP). In contrast to existing local or edge motion planning solutions that ignore the interdependency between low-level motion planning and high-level resource allocation, EARN adopts model predictive switching (MPS) that maximizes the expected switching gain w.r.t. robot states and actions under computation and communication resource constraints. As such, each robot can dynamically switch between a point-mass motion planner executed locally to guarantee safety (e.g., path-following) and a full-shape motion planner executed non-locally to guarantee efficiency (e.g., overtaking). The crux to EARN is a two-time scale integrated decision-planning algorithm based on bilevel mixed-integer optimization, and a fast conditional collision avoidance algorithm based on penalty dual decomposition. We validate the performance of EARN in indoor simulation, outdoor simulation, and real-world environments. Experiments show that EARN achieves significantly smaller navigation time and collision ratios than state-of-the-art navigation approaches.
Pushing the Limits of Pre-training for Time Series Forecasting in the CloudOps Domain
Oct 10, 2023Time series has been left behind in the era of pre-training and transfer learning. While research in the fields of natural language processing and computer vision are enjoying progressively larger datasets to train massive models, the most popular time series datasets consist of only tens of thousands of time steps, limiting our ability to study the effectiveness of pre-training and scaling. Recent studies have also cast doubt on the need for expressive models and scale. To alleviate these issues, we introduce three large-scale time series forecasting datasets from the cloud operations (CloudOps) domain, the largest having billions of observations, enabling further study into pre-training and scaling of time series models. We build the empirical groundwork for studying pre-training and scaling of time series models and pave the way for future research by identifying a promising candidate architecture. We show that it is a strong zero-shot baseline and benefits from further scaling, both in model and dataset size. Accompanying these datasets and results is a suite of comprehensive benchmark results comparing classical and deep learning baselines to our pre-trained method - achieving a 27% reduction in error on the largest dataset. Code and datasets will be released.
You Only Explain Once
Nov 23, 2023In this paper, we propose a new black-box explainability algorithm and tool, YO-ReX, for efficient explanation of the outputs of object detectors. The new algorithm computes explanations for all objects detected in the image simultaneously. Hence, compared to the baseline, the new algorithm reduces the number of queries by a factor of 10X for the case of ten detected objects. The speedup increases further with with the number of objects. Our experimental results demonstrate that YO-ReX can explain the outputs of YOLO with a negligible overhead over the running time of YOLO. We also demonstrate similar results for explaining SSD and Faster R-CNN. The speedup is achieved by avoiding backtracking by combining aggressive pruning with a causal analysis.
Time-Domain Channel Estimation for Extremely Large MIMO THz Communications with Beam Squint
Oct 23, 2023In this paper, we study the problem of extremely large (XL) multiple-input multiple-output (MIMO) channel estimation in the Terahertz (THz) frequency band, considering the presence of propagation delays across the entire array apertures, which leads to frequency selectivity, a problem known as beam squint. Multi-carrier transmission schemes which are usually deployed to address this problem, suffer from high peak-to-average power ratio, which is specifically dominant in THz communications where low transmit power is realized. Diverging from the usual approach, we devise a novel channel estimation problem formulation in the time domain for single-carrier (SC) modulation, which favors transmissions in THz, and incorporate the beam-squint effect in a sparse vector recovery problem that is solved via sparse optimization tools. In particular, the beam squint and the sparse MIMO channel are jointly tracked by using an alternating minimization approach that decomposes the two estimation problems. The presented performance evaluation results validate that the proposed SC technique exhibits superior performance than the conventional one as well as than state-of-the-art multi-carrier approaches.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Unsupervised high-throughput segmentation of cells and cell nuclei in quantitative phase images
Nov 24, 2023In the effort to aid cytologic diagnostics by establishing automatic single cell screening using high throughput digital holographic microscopy for clinical studies thousands of images and millions of cells are captured. The bottleneck lies in an automatic, fast, and unsupervised segmentation technique that does not limit the types of cells which might occur. We propose an unsupervised multistage method that segments correctly without confusing noise or reflections with cells and without missing cells that also includes the detection of relevant inner structures, especially the cell nucleus in the unstained cell. In an effort to make the information reasonable and interpretable for cytopathologists, we also introduce new cytoplasmic and nuclear features of potential help for cytologic diagnoses which exploit the quantitative phase information inherent to the measurement scheme. We show that the segmentation provides consistently good results over many experiments on patient samples in a reasonable per cell analysis time.
Set Features for Anomaly Detection
Nov 24, 2023This paper proposes set features for detecting anomalies in samples that consist of unusual combinations of normal elements. Many leading methods discover anomalies by detecting an unusual part of a sample. For example, state-of-the-art segmentation-based approaches, first classify each element of the sample (e.g., image patch) as normal or anomalous and then classify the entire sample as anomalous if it contains anomalous elements. However, such approaches do not extend well to scenarios where the anomalies are expressed by an unusual combination of normal elements. In this paper, we overcome this limitation by proposing set features that model each sample by the distribution of its elements. We compute the anomaly score of each sample using a simple density estimation method, using fixed features. Our approach outperforms the previous state-of-the-art in image-level logical anomaly detection and sequence-level time series anomaly detection.
Counter-Empirical Attacking based on Adversarial Reinforcement Learning for Time-Relevant Scoring System
Nov 09, 2023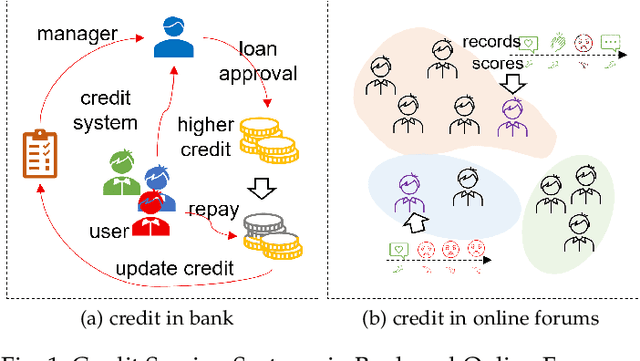
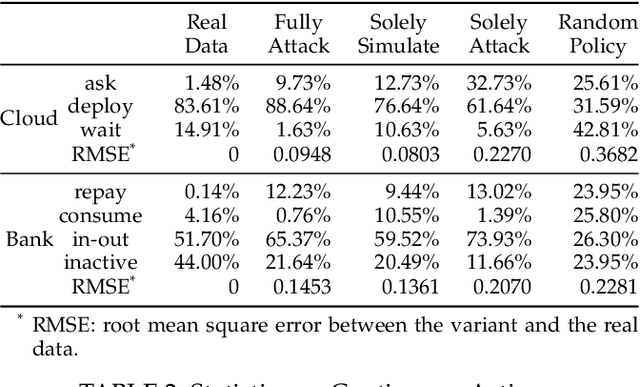
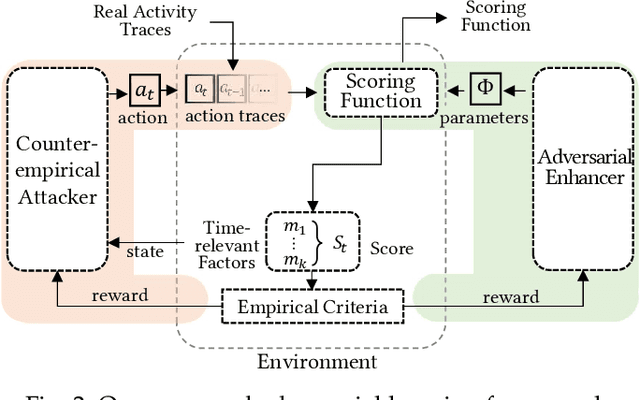
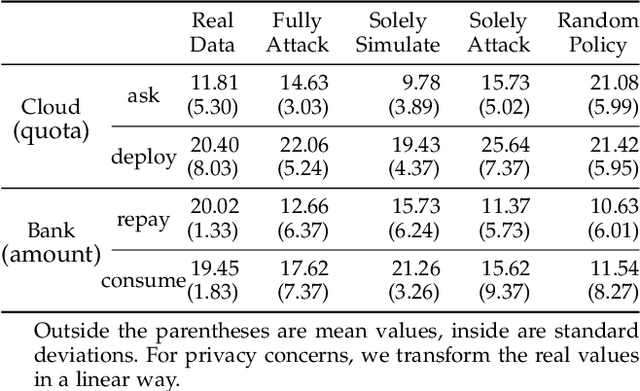
Scoring systems are commonly seen for platforms in the era of big data. From credit scoring systems in financial services to membership scores in E-commerce shopping platforms, platform managers use such systems to guide users towards the encouraged activity pattern, and manage resources more effectively and more efficiently thereby. To establish such scoring systems, several "empirical criteria" are firstly determined, followed by dedicated top-down design for each factor of the score, which usually requires enormous effort to adjust and tune the scoring function in the new application scenario. What's worse, many fresh projects usually have no ground-truth or any experience to evaluate a reasonable scoring system, making the designing even harder. To reduce the effort of manual adjustment of the scoring function in every new scoring system, we innovatively study the scoring system from the preset empirical criteria without any ground truth, and propose a novel framework to improve the system from scratch. In this paper, we propose a "counter-empirical attacking" mechanism that can generate "attacking" behavior traces and try to break the empirical rules of the scoring system. Then an adversarial "enhancer" is applied to evaluate the scoring system and find the improvement strategy. By training the adversarial learning problem, a proper scoring function can be learned to be robust to the attacking activity traces that are trying to violate the empirical criteria. Extensive experiments have been conducted on two scoring systems including a shared computing resource platform and a financial credit system. The experimental results have validated the effectiveness of our proposed framework.
Discretized Distributed Optimization over Dynamic Digraphs
Nov 14, 2023We consider a discrete-time model of continuous-time distributed optimization over dynamic directed-graphs (digraphs) with applications to distributed learning. Our optimization algorithm works over general strongly connected dynamic networks under switching topologies, e.g., in mobile multi-agent systems and volatile networks due to link failures. Compared to many existing lines of work, there is no need for bi-stochastic weight designs on the links. The existing literature mostly needs the link weights to be stochastic using specific weight-design algorithms needed both at the initialization and at all times when the topology of the network changes. This paper eliminates the need for such algorithms and paves the way for distributed optimization over time-varying digraphs. We derive the bound on the gradient-tracking step-size and discrete time-step for convergence and prove dynamic stability using arguments from consensus algorithms, matrix perturbation theory, and Lyapunov theory. This work, particularly, is an improvement over existing stochastic-weight undirected networks in case of link removal or packet drops. This is because the existing literature may need to rerun time-consuming and computationally complex algorithms for stochastic design, while the proposed strategy works as long as the underlying network is weight-symmetric and balanced. The proposed optimization framework finds applications to distributed classification and learning.