 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Identifiable Feature Learning for Spatial Data with Nonlinear ICA
Nov 28, 2023
Recently, nonlinear ICA has surfaced as a popular alternative to the many heuristic models used in deep representation learning and disentanglement. An advantage of nonlinear ICA is that a sophisticated identifiability theory has been developed; in particular, it has been proven that the original components can be recovered under sufficiently strong latent dependencies. Despite this general theory, practical nonlinear ICA algorithms have so far been mainly limited to data with one-dimensional latent dependencies, especially time-series data. In this paper, we introduce a new nonlinear ICA framework that employs $t$-process (TP) latent components which apply naturally to data with higher-dimensional dependency structures, such as spatial and spatio-temporal data. In particular, we develop a new learning and inference algorithm that extends variational inference methods to handle the combination of a deep neural network mixing function with the TP prior, and employs the method of inducing points for computational efficacy. On the theoretical side, we show that such TP independent components are identifiable under very general conditions. Further, Gaussian Process (GP) nonlinear ICA is established as a limit of the TP Nonlinear ICA model, and we prove that the identifiability of the latent components at this GP limit is more restricted. Namely, those components are identifiable if and only if they have distinctly different covariance kernels. Our algorithm and identifiability theorems are explored on simulated spatial data and real world spatio-temporal data.
Graph Pre-training and Prompt Learning for Recommendation
Nov 28, 2023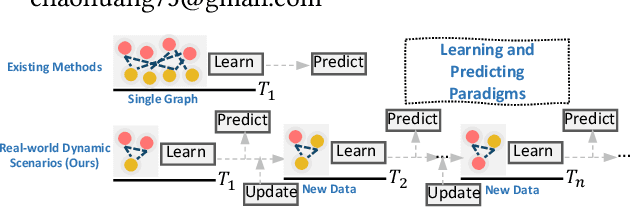
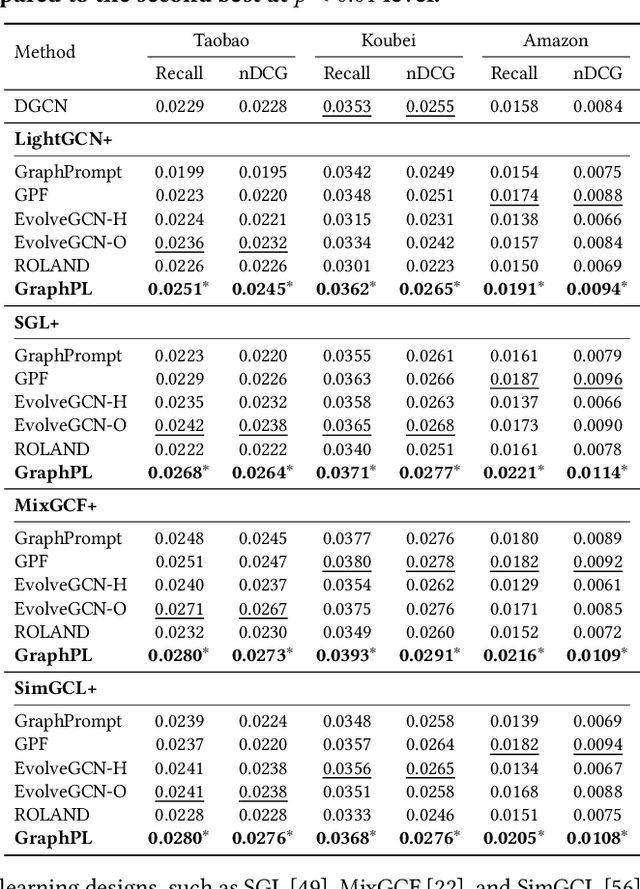
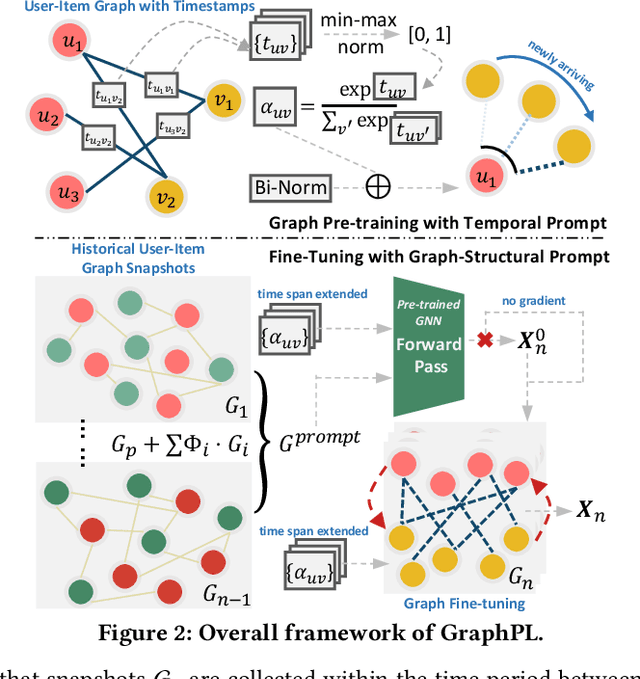
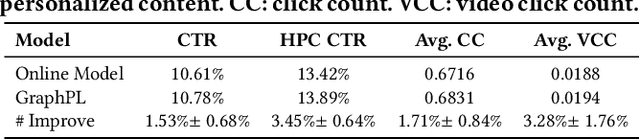
GNN-based recommenders have excelled in modeling intricate user-item interactions through multi-hop message passing. However, existing methods often overlook the dynamic nature of evolving user-item interactions, which impedes the adaption to changing user preferences and distribution shifts in newly arriving data. Thus, their scalability and performances in real-world dynamic environments are limited. In this study, we propose GraphPL, a framework that incorporates parameter-efficient and dynamic graph pre-training with prompt learning. This novel combination empowers GNNs to effectively capture both long-term user preferences and short-term behavior dynamics, enabling the delivery of accurate and timely recommendations. Our GraphPL framework addresses the challenge of evolving user preferences by seamlessly integrating a temporal prompt mechanism and a graph-structural prompt learning mechanism into the pre-trained GNN model. The temporal prompt mechanism encodes time information on user-item interaction, allowing the model to naturally capture temporal context, while the graph-structural prompt learning mechanism enables the transfer of pre-trained knowledge to adapt to behavior dynamics without the need for continuous incremental training. We further bring in a dynamic evaluation setting for recommendation to mimic real-world dynamic scenarios and bridge the offline-online gap to a better level. Our extensive experiments including a large-scale industrial deployment showcases the lightweight plug-in scalability of our GraphPL when integrated with various state-of-the-art recommenders, emphasizing the advantages of GraphPL in terms of effectiveness, robustness and efficiency.
Breaking Boundaries: Balancing Performance and Robustness in Deep Wireless Traffic Forecasting
Nov 28, 2023Balancing the trade-off between accuracy and robustness is a long-standing challenge in time series forecasting. While most of existing robust algorithms have achieved certain suboptimal performance on clean data, sustaining the same performance level in the presence of data perturbations remains extremely hard. In this paper, we study a wide array of perturbation scenarios and propose novel defense mechanisms against adversarial attacks using real-world telecom data. We compare our strategy against two existing adversarial training algorithms under a range of maximal allowed perturbations, defined using $\ell_{\infty}$-norm, $\in [0.1,0.4]$. Our findings reveal that our hybrid strategy, which is composed of a classifier to detect adversarial examples, a denoiser to eliminate noise from the perturbed data samples, and a standard forecaster, achieves the best performance on both clean and perturbed data. Our optimal model can retain up to $92.02\%$ the performance of the original forecasting model in terms of Mean Squared Error (MSE) on clean data, while being more robust than the standard adversarially trained models on perturbed data. Its MSE is 2.71$\times$ and 2.51$\times$ lower than those of comparing methods on normal and perturbed data, respectively. In addition, the components of our models can be trained in parallel, resulting in better computational efficiency. Our results indicate that we can optimally balance the trade-off between the performance and robustness of forecasting models by improving the classifier and denoiser, even in the presence of sophisticated and destructive poisoning attacks.
* Accepted for presentation at the ARTMAN workshop, part of the ACM Conference on Computer and Communications Security (CCS), 2023
MicroNAS: Memory and Latency Constrained Hardware-Aware Neural Architecture Search for Time Series Classification on Microcontrollers
Oct 27, 2023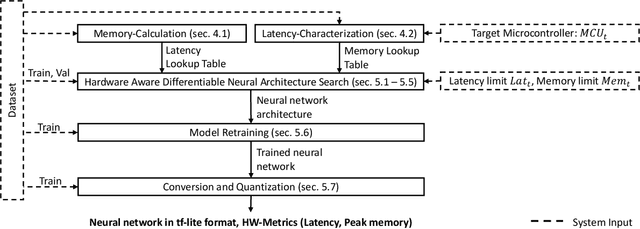
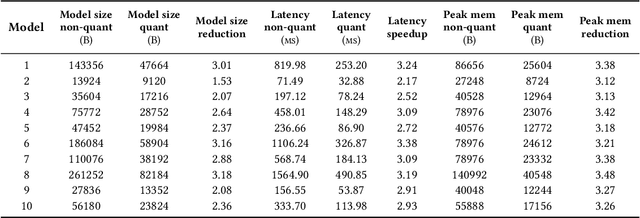
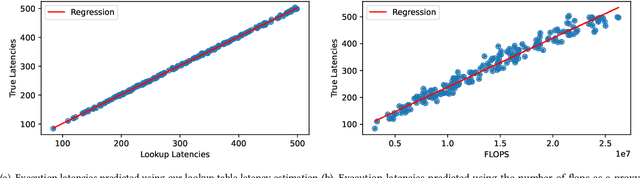
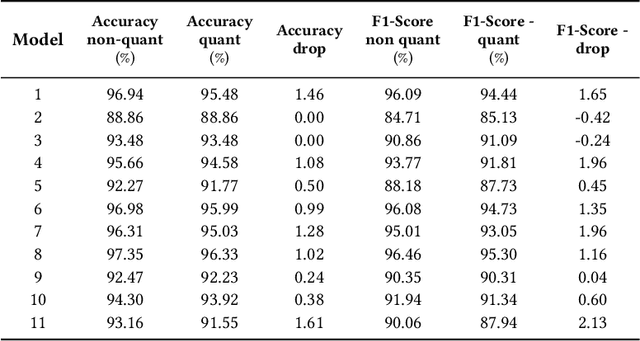
This paper presents MicroNAS, a system designed to automatically search and generate neural network architectures capable of classifying time series data on resource-constrained microcontrollers (MCUs) and generating standard tf-lite ML models. MicroNAS takes into account user-defined constraints on execution latency and peak memory consumption on a target MCU. This approach ensures that the resulting neural network architectures are optimised for the specific constraints and requirements of the MCU on which they are implemented. To achieve this, MicroNAS uses a look-up table estimation approach for accurate execution latency calculations, with a minimum error of only 1.02ms. This accurate latency estimation on MCUs sets it apart from other hardware-aware neural architecture search (HW-NAS) methods that use less accurate estimation techniques. Finally, MicroNAS delivers performance close to that of state-of-the-art models running on desktop computers, achieving high classification accuracies on recognised datasets (93.93% on UCI-HAR and 96.33% on SkodaR) while running on a Cortex-M4 MCU.
A Machine Learning-based Algorithm for Automated Detection of Frequency-based Events in Recorded Time Series of Sensor Data
Oct 16, 2023Automated event detection has emerged as one of the fundamental practices to monitor the behavior of technical systems by means of sensor data. In the automotive industry, these methods are in high demand for tracing events in time series data. For assessing the active vehicle safety systems, a diverse range of driving scenarios is conducted. These scenarios involve the recording of the vehicle's behavior using external sensors, enabling the evaluation of operational performance. In such setting, automated detection methods not only accelerate but also standardize and objectify the evaluation by avoiding subjective, human-based appraisals in the data inspection. This work proposes a novel event detection method that allows to identify frequency-based events in time series data. To this aim, the time series data is mapped to representations in the time-frequency domain, known as scalograms. After filtering scalograms to enhance relevant parts of the signal, an object detection model is trained to detect the desired event objects in the scalograms. For the analysis of unseen time series data, events can be detected in their scalograms with the trained object detection model and are thereafter mapped back to the time series data to mark the corresponding time interval. The algorithm, evaluated on unseen datasets, achieves a precision rate of 0.97 in event detection, providing sharp time interval boundaries whose accurate indication by human visual inspection is challenging. Incorporating this method into the vehicle development process enhances the accuracy and reliability of event detection, which holds major importance for rapid testing analysis.
Designing Long-term Group Fair Policies in Dynamical Systems
Nov 21, 2023Neglecting the effect that decisions have on individuals (and thus, on the underlying data distribution) when designing algorithmic decision-making policies may increase inequalities and unfairness in the long term - even if fairness considerations were taken in the policy design process. In this paper, we propose a novel framework for achieving long-term group fairness in dynamical systems, in which current decisions may affect an individual's features in the next step, and thus, future decisions. Specifically, our framework allows us to identify a time-independent policy that converges, if deployed, to the targeted fair stationary state of the system in the long term, independently of the initial data distribution. We model the system dynamics with a time-homogeneous Markov chain and optimize the policy leveraging the Markov chain convergence theorem to ensure unique convergence. We provide examples of different targeted fair states of the system, encompassing a range of long-term goals for society and policymakers. Furthermore, we show how our approach facilitates the evaluation of different long-term targets by examining their impact on the group-conditional population distribution in the long term and how it evolves until convergence.
A Multi-In-Single-Out Network for Video Frame Interpolation without Optical Flow
Nov 26, 2023In general, deep learning-based video frame interpolation (VFI) methods have predominantly focused on estimating motion vectors between two input frames and warping them to the target time. While this approach has shown impressive performance for linear motion between two input frames, it exhibits limitations when dealing with occlusions and nonlinear movements. Recently, generative models have been applied to VFI to address these issues. However, as VFI is not a task focused on generating plausible images, but rather on predicting accurate intermediate frames between two given frames, performance limitations still persist. In this paper, we propose a multi-in-single-out (MISO) based VFI method that does not rely on motion vector estimation, allowing it to effectively model occlusions and nonlinear motion. Additionally, we introduce a novel motion perceptual loss that enables MISO-VFI to better capture the spatio-temporal correlations within the video frames. Our MISO-VFI method achieves state-of-the-art results on VFI benchmarks Vimeo90K, Middlebury, and UCF101, with a significant performance gap compared to existing approaches.
Maintenance Techniques for Anomaly Detection AIOps Solutions
Nov 17, 2023Anomaly detection techniques are essential in automating the monitoring of IT systems and operations. These techniques imply that machine learning algorithms are trained on operational data corresponding to a specific period of time and that they are continuously evaluated on newly emerging data. Operational data is constantly changing over time, which affects the performance of deployed anomaly detection models. Therefore, continuous model maintenance is required to preserve the performance of anomaly detectors over time. In this work, we analyze two different anomaly detection model maintenance techniques in terms of the model update frequency, namely blind model retraining and informed model retraining. We further investigate the effects of updating the model by retraining it on all the available data (full-history approach) and on only the newest data (sliding window approach). Moreover, we investigate whether a data change monitoring tool is capable of determining when the anomaly detection model needs to be updated through retraining.
Machine-learning parameter tracking with partial state observation
Nov 15, 2023Complex and nonlinear dynamical systems often involve parameters that change with time, accurate tracking of which is essential to tasks such as state estimation, prediction, and control. Existing machine-learning methods require full state observation of the underlying system and tacitly assume adiabatic changes in the parameter. Formulating an inverse problem and exploiting reservoir computing, we develop a model-free and fully data-driven framework to accurately track time-varying parameters from partial state observation in real time. In particular, with training data from a subset of the dynamical variables of the system for a small number of known parameter values, the framework is able to accurately predict the parameter variations in time. Low- and high-dimensional, Markovian and non-Markovian nonlinear dynamical systems are used to demonstrate the power of the machine-learning based parameter-tracking framework. Pertinent issues affecting the tracking performance are addressed.
Source-Free Domain Adaptation with Frozen Multimodal Foundation Model
Nov 27, 2023Source-Free Domain Adaptation (SFDA) aims to adapt a source model for a target domain, with only access to unlabeled target training data and the source model pre-trained on a supervised source domain. Relying on pseudo labeling and/or auxiliary supervision, conventional methods are inevitably error-prone. To mitigate this limitation, in this work we for the first time explore the potentials of off-the-shelf vision-language (ViL) multimodal models (e.g.,CLIP) with rich whilst heterogeneous knowledge. We find that directly applying the ViL model to the target domain in a zero-shot fashion is unsatisfactory, as it is not specialized for this particular task but largely generic. To make it task specific, we propose a novel Distilling multimodal Foundation model(DIFO)approach. Specifically, DIFO alternates between two steps during adaptation: (i) Customizing the ViL model by maximizing the mutual information with the target model in a prompt learning manner, (ii) Distilling the knowledge of this customized ViL model to the target model. For more fine-grained and reliable distillation, we further introduce two effective regularization terms, namely most-likely category encouragement and predictive consistency. Extensive experiments show that DIFO significantly outperforms the state-of-the-art alternatives. Our source code will be released.