 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023
Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Robust Domain Misinformation Detection via Multi-modal Feature Alignment
Nov 24, 2023Social media misinformation harms individuals and societies and is potentialized by fast-growing multi-modal content (i.e., texts and images), which accounts for higher "credibility" than text-only news pieces. Although existing supervised misinformation detection methods have obtained acceptable performances in key setups, they may require large amounts of labeled data from various events, which can be time-consuming and tedious. In turn, directly training a model by leveraging a publicly available dataset may fail to generalize due to domain shifts between the training data (a.k.a. source domains) and the data from target domains. Most prior work on domain shift focuses on a single modality (e.g., text modality) and ignores the scenario where sufficient unlabeled target domain data may not be readily available in an early stage. The lack of data often happens due to the dynamic propagation trend (i.e., the number of posts related to fake news increases slowly before catching the public attention). We propose a novel robust domain and cross-modal approach (\textbf{RDCM}) for multi-modal misinformation detection. It reduces the domain shift by aligning the joint distribution of textual and visual modalities through an inter-domain alignment module and bridges the semantic gap between both modalities through a cross-modality alignment module. We also propose a framework that simultaneously considers application scenarios of domain generalization (in which the target domain data is unavailable) and domain adaptation (in which unlabeled target domain data is available). Evaluation results on two public multi-modal misinformation detection datasets (Pheme and Twitter Datasets) evince the superiority of the proposed model. The formal implementation of this paper can be found in this link: https://github.com/less-and-less-bugs/RDCM
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 11, 2023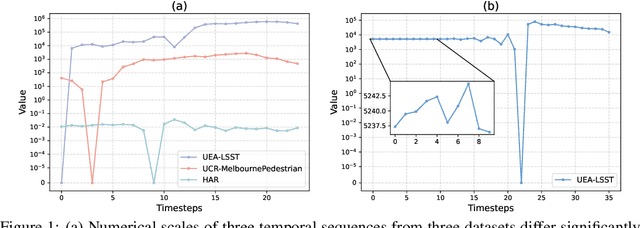
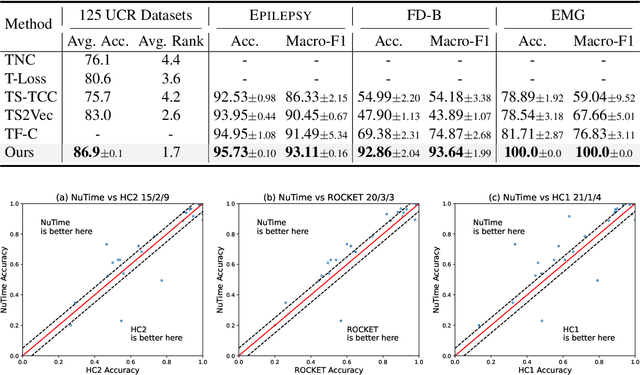
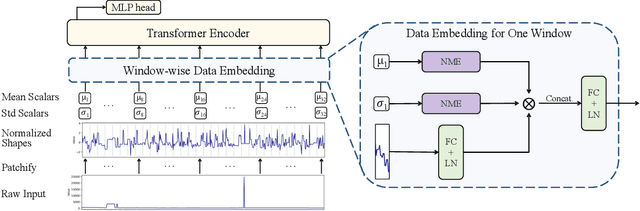
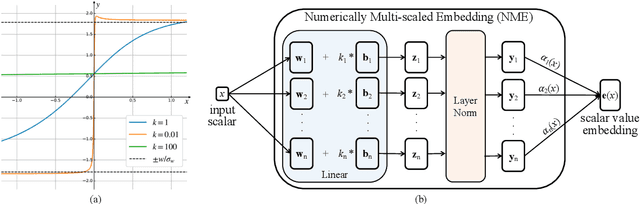
Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Probability of Collision of satellites and space debris for short-term encounters: Rederivation and fast-to-compute upper and lower bounds
Nov 15, 2023The proliferation of space debris in LEO has become a major concern for the space industry. With the growing interest in space exploration, the prediction of potential collisions between objects in orbit has become a crucial issue. It is estimated that, in orbit, there are millions of fragments a few millimeters in size and thousands of inoperative satellites and discarded rocket stages. Given the high speeds that these fragments can reach, even fragments a few millimeters in size can cause fractures in a satellite's hull or put a serious crack in the window of a space shuttle. The conventional method proposed by Akella and Alfriend in 2000 remains widely used to estimate the probability of collision in short-term encounters. Given the small period of time, it is assumed that, during the encounter: (1) trajectories are represented by straight lines with constant velocity; (2) there is no velocity uncertainty and the position exhibits a stationary distribution throughout the encounter; and (3) position uncertainties are independent and represented by Gaussian distributions. This study introduces a novel derivation based on first principles that naturally allows for tight and fast upper and lower bounds for the probability of collision. We tested implementations of both probability and bound computations with the original and our formulation on a real CDM dataset used in ESA's Collision Avoidance Challenge. Our approach reduces the calculation of the probability to two one-dimensional integrals and has the potential to significantly reduce the processing time compared to the traditional method, from 80% to nearly real-time.
Throughput Maximisation in Ultra-wideband Hybrid-amplified Links
Nov 15, 2023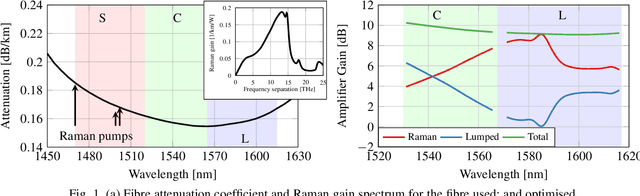
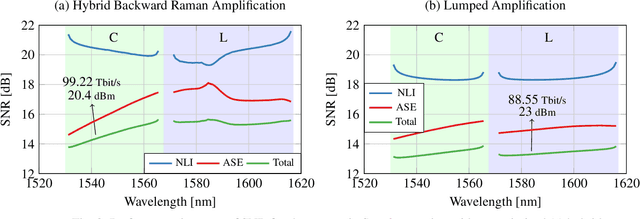
A semi-analytical, real-time nonlinear-interference model including ASE noise in hybrid-amplified links is introduced. Combined with particle-swarm optimisation, the capacity of a hybrid-amplified 10.5 THz 117x57 km link was maximised, increasing throughput by 12% versus an EDFAs-only configuration.
Uncertainty Estimation in Contrast-Enhanced MR Image Translation with Multi-Axis Fusion
Nov 20, 2023In recent years, deep learning has been applied to a wide range of medical imaging and image processing tasks. In this work, we focus on the estimation of epistemic uncertainty for 3D medical image-to-image translation. We propose a novel model uncertainty quantification method, Multi-Axis Fusion (MAF), which relies on the integration of complementary information derived from multiple views on volumetric image data. The proposed approach is applied to the task of synthesizing contrast enhanced T1-weighted images based on native T1, T2 and T2-FLAIR scans. The quantitative findings indicate a strong correlation ($\rho_{\text healthy} = 0.89$) between the mean absolute image synthetization error and the mean uncertainty score for our MAF method. Hence, we consider MAF as a promising approach to solve the highly relevant task of detecting synthetization failures at inference time.
Real-Time Motion Prediction via Heterogeneous Polyline Transformer with Relative Pose Encoding
Oct 19, 2023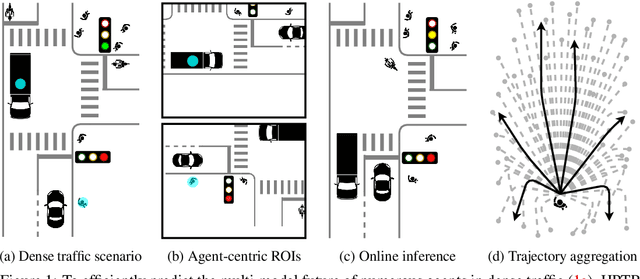
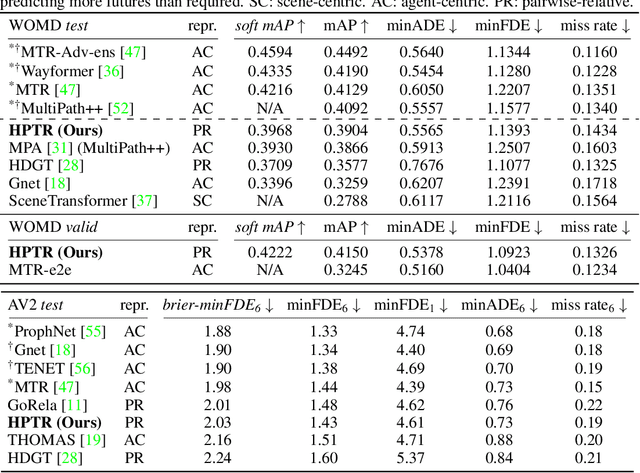
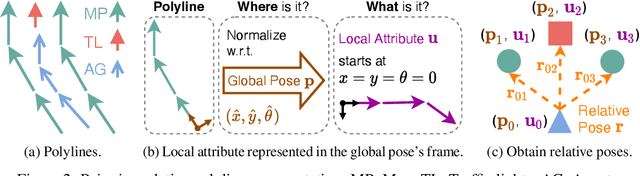
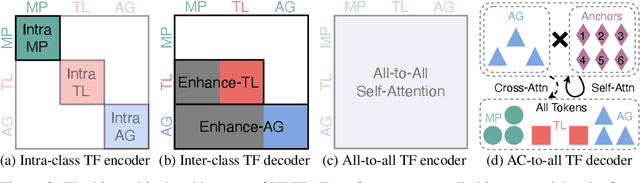
The real-world deployment of an autonomous driving system requires its components to run on-board and in real-time, including the motion prediction module that predicts the future trajectories of surrounding traffic participants. Existing agent-centric methods have demonstrated outstanding performance on public benchmarks. However, they suffer from high computational overhead and poor scalability as the number of agents to be predicted increases. To address this problem, we introduce the K-nearest neighbor attention with relative pose encoding (KNARPE), a novel attention mechanism allowing the pairwise-relative representation to be used by Transformers. Then, based on KNARPE we present the Heterogeneous Polyline Transformer with Relative pose encoding (HPTR), a hierarchical framework enabling asynchronous token update during the online inference. By sharing contexts among agents and reusing the unchanged contexts, our approach is as efficient as scene-centric methods, while performing on par with state-of-the-art agent-centric methods. Experiments on Waymo and Argoverse-2 datasets show that HPTR achieves superior performance among end-to-end methods that do not apply expensive post-processing or model ensembling. The code is available at https://github.com/zhejz/HPTR.
SegReg: Segmenting OARs by Registering MR Images and CT Annotations
Nov 12, 2023Organ at risk (OAR) segmentation is a critical process in radiotherapy treatment planning such as head and neck tumors. Nevertheless, in clinical practice, radiation oncologists predominantly perform OAR segmentations manually on CT scans. This manual process is highly time-consuming and expensive, limiting the number of patients who can receive timely radiotherapy. Additionally, CT scans offer lower soft-tissue contrast compared to MRI. Despite MRI providing superior soft-tissue visualization, its time-consuming nature makes it infeasible for real-time treatment planning. To address these challenges, we propose a method called SegReg, which utilizes Elastic Symmetric Normalization for registering MRI to perform OAR segmentation. SegReg outperforms the CT-only baseline by 16.78% in mDSC and 18.77% in mIoU, showing that it effectively combines the geometric accuracy of CT with the superior soft-tissue contrast of MRI, making accurate automated OAR segmentation for clinical practice become possible.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
Task-Distributionally Robust Data-Free Meta-Learning
Nov 23, 2023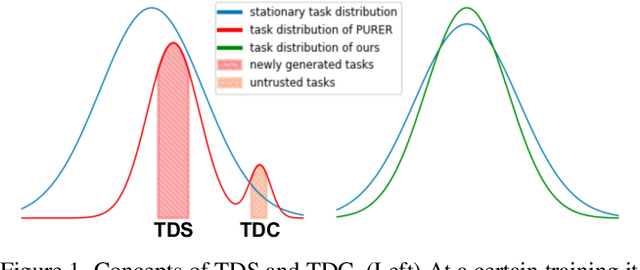
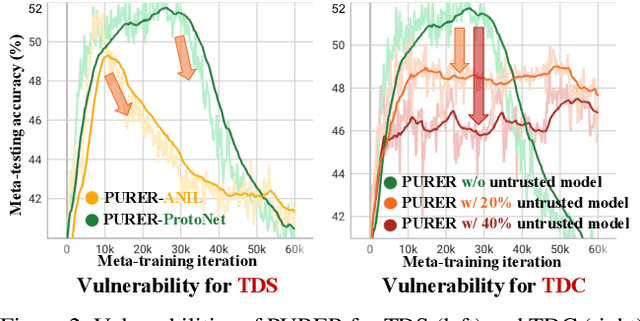
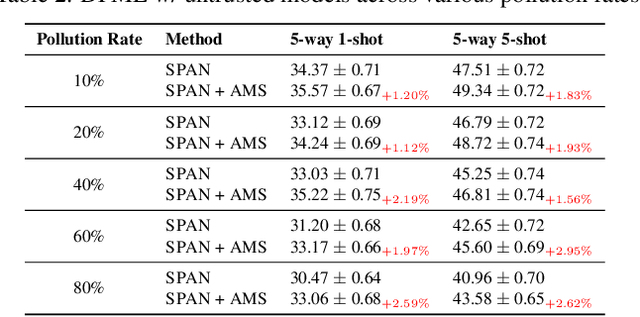
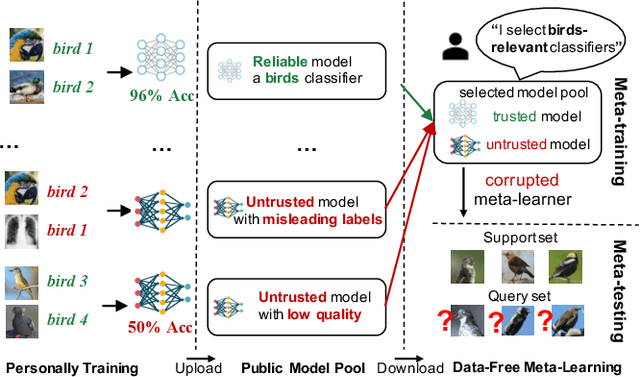
Data-Free Meta-Learning (DFML) aims to efficiently learn new tasks by leveraging multiple pre-trained models without requiring their original training data. Existing inversion-based DFML methods construct pseudo tasks from a learnable dataset, which is inversely generated from the pre-trained model pool. For the first time, we reveal two major challenges hindering their practical deployments: Task-Distribution Shift (TDS) and Task-Distribution Corruption (TDC). TDS leads to a biased meta-learner because of the skewed task distribution towards newly generated tasks. TDC occurs when untrusted models characterized by misleading labels or poor quality pollute the task distribution. To tackle these issues, we introduce a robust DFML framework that ensures task distributional robustness. We propose to meta-learn from a pseudo task distribution, diversified through task interpolation within a compact task-memory buffer. This approach reduces the meta-learner's overreliance on newly generated tasks by maintaining consistent performance across a broader range of interpolated memory tasks, thus ensuring its generalization for unseen tasks. Additionally, our framework seamlessly incorporates an automated model selection mechanism into the meta-training phase, parameterizing each model's reliability as a learnable weight. This is optimized with a policy gradient algorithm inspired by reinforcement learning, effectively addressing the non-differentiable challenge posed by model selection. Comprehensive experiments across various datasets demonstrate the framework's effectiveness in mitigating TDS and TDC, underscoring its potential to improve DFML in real-world scenarios.