 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Speech Enhancement and Separation with a Unified Deep Neural Network for Single/Dual Talker Scenarios
Oct 16, 2023
This paper introduces a practical approach for leveraging a real-time deep learning model to alternate between speech enhancement and joint speech enhancement and separation depending on whether the input mixture contains one or two active speakers. Scale-invariant signal-to-distortion ratio (SI-SDR) has shown to be a highly effective training measure in time-domain speech separation. However, the SI-SDR metric is ill-defined for zero-energy target signals, which is a problem when training a speech separation model using utterances with varying numbers of talkers. Unlike existing solutions that focus on modifying the loss function to accommodate zero-energy target signals, the proposed approach circumvents this problem by training the model to extract speech on both its output channels regardless if the input is a single or dual-talker mixture. A lightweight speaker overlap detection (SOD) module is also introduced to differentiate between single and dual-talker segments in real-time. The proposed module takes advantage of the new formulation by operating directly on the separated masks, given by the separation model, instead of the original mixture, thus effectively simplifying the detection task. Experimental results show that the proposed training approach outperforms existing solutions, and the SOD module exhibits high accuracy.
Masked Autoencoders Are Robust Neural Architecture Search Learners
Nov 20, 2023Neural Architecture Search (NAS) currently relies heavily on labeled data, which is both expensive and time-consuming to acquire. In this paper, we propose a novel NAS framework based on Masked Autoencoders (MAE) that eliminates the need for labeled data during the search process. By replacing the supervised learning objective with an image reconstruction task, our approach enables the robust discovery of network architectures without compromising performance and generalization ability. Additionally, we address the problem of performance collapse encountered in the widely-used Differentiable Architecture Search (DARTS) method in the unsupervised paradigm by introducing a multi-scale decoder. Through extensive experiments conducted on various search spaces and datasets, we demonstrate the effectiveness and robustness of the proposed method, providing empirical evidence of its superiority over baseline approaches.
ADAPTER-RL: Adaptation of Any Agent using Reinforcement Learning
Nov 20, 2023Deep Reinforcement Learning (DRL) agents frequently face challenges in adapting to tasks outside their training distribution, including issues with over-fitting, catastrophic forgetting and sample inefficiency. Although the application of adapters has proven effective in supervised learning contexts such as natural language processing and computer vision, their potential within the DRL domain remains largely unexplored. This paper delves into the integration of adapters in reinforcement learning, presenting an innovative adaptation strategy that demonstrates enhanced training efficiency and improvement of the base-agent, experimentally in the nanoRTS environment, a real-time strategy (RTS) game simulation. Our proposed universal approach is not only compatible with pre-trained neural networks but also with rule-based agents, offering a means to integrate human expertise.
Creating Temporally Correlated High-Resolution Power Injection Profiles Using Physics-Aware GAN
Nov 20, 2023Traditional smart meter measurements lack the granularity needed for real-time decision-making. To address this practical problem, we create a generative adversarial networks (GAN) model that enforces temporal consistency on its high-resolution outputs via hard inequality constraints using a convex optimization layer. A unique feature of our GAN model is that it is trained solely on slow timescale aggregated power information obtained from historical smart meter data. The results demonstrate that the model can successfully create minutely interval temporally-correlated instantaneous power injection profiles from 15-minute average power consumption information. This innovative approach, emphasizing inter-neuron constraints, offers a promising avenue for improved high-speed state estimation in distribution systems and enhances the applicability of data-driven solutions for monitoring such systems.
Robustifying Generalizable Implicit Shape Networks with a Tunable Non-Parametric Model
Nov 21, 2023Feedforward generalizable models for implicit shape reconstruction from unoriented point cloud present multiple advantages, including high performance and inference speed. However, they still suffer from generalization issues, ranging from underfitting the input point cloud, to misrepresenting samples outside of the training data distribution, or with toplogies unseen at training. We propose here an efficient mechanism to remedy some of these limitations at test time. We combine the inter-shape data prior of the network with an intra-shape regularization prior of a Nystr\"om Kernel Ridge Regression, that we further adapt by fitting its hyperprameters to the current shape. The resulting shape function defined in a shape specific Reproducing Kernel Hilbert Space benefits from desirable stability and efficiency properties and grants a shape adaptive expressiveness-robustness trade-off. We demonstrate the improvement obtained through our method with respect to baselines and the state-of-the-art using synthetic and real data.
Efficient Interpretable Nonlinear Modeling for Multiple Time Series
Sep 29, 2023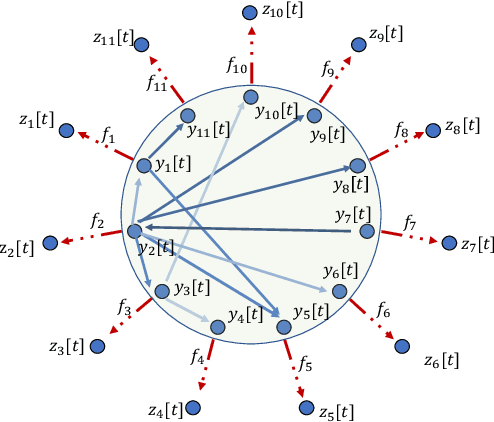
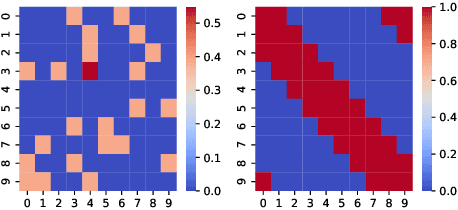
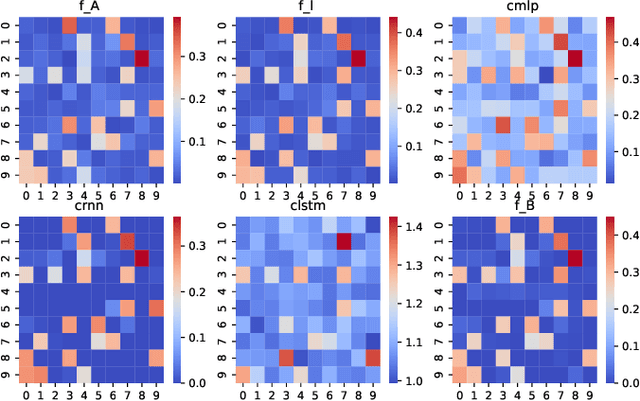
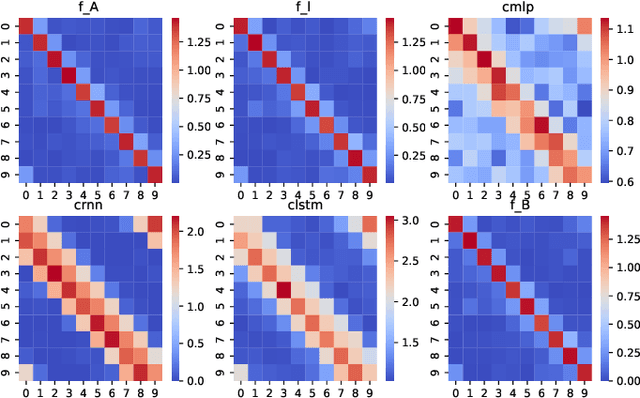
Predictive linear and nonlinear models based on kernel machines or deep neural networks have been used to discover dependencies among time series. This paper proposes an efficient nonlinear modeling approach for multiple time series, with a complexity comparable to linear vector autoregressive (VAR) models while still incorporating nonlinear interactions among different time-series variables. The modeling assumption is that the set of time series is generated in two steps: first, a linear VAR process in a latent space, and second, a set of invertible and Lipschitz continuous nonlinear mappings that are applied per sensor, that is, a component-wise mapping from each latent variable to a variable in the measurement space. The VAR coefficient identification provides a topology representation of the dependencies among the aforementioned variables. The proposed approach models each component-wise nonlinearity using an invertible neural network and imposes sparsity on the VAR coefficients to reflect the parsimonious dependencies usually found in real applications. To efficiently solve the formulated optimization problems, a custom algorithm is devised combining proximal gradient descent, stochastic primal-dual updates, and projection to enforce the corresponding constraints. Experimental results on both synthetic and real data sets show that the proposed algorithm improves the identification of the support of the VAR coefficients in a parsimonious manner while also improving the time-series prediction, as compared to the current state-of-the-art methods.
Message Propagation Through Time: An Algorithm for Sequence Dependency Retention in Time Series Modeling
Sep 28, 2023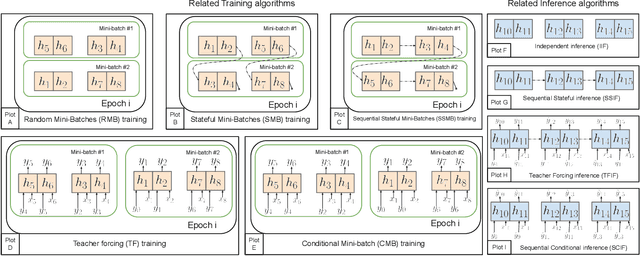
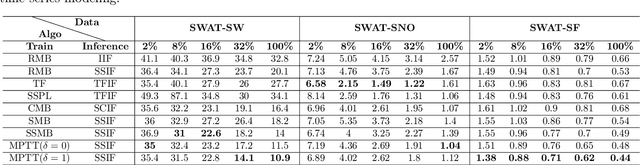
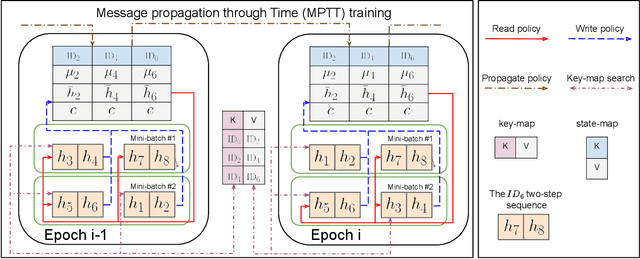

Time series modeling, a crucial area in science, often encounters challenges when training Machine Learning (ML) models like Recurrent Neural Networks (RNNs) using the conventional mini-batch training strategy that assumes independent and identically distributed (IID) samples and initializes RNNs with zero hidden states. The IID assumption ignores temporal dependencies among samples, resulting in poor performance. This paper proposes the Message Propagation Through Time (MPTT) algorithm to effectively incorporate long temporal dependencies while preserving faster training times relative to the stateful solutions. MPTT utilizes two memory modules to asynchronously manage initial hidden states for RNNs, fostering seamless information exchange between samples and allowing diverse mini-batches throughout epochs. MPTT further implements three policies to filter outdated and preserve essential information in the hidden states to generate informative initial hidden states for RNNs, facilitating robust training. Experimental results demonstrate that MPTT outperforms seven strategies on four climate datasets with varying levels of temporal dependencies.
Calibration of Time-Series Forecasting Transformers: Detecting and Adapting Context-Driven Distribution Shift
Oct 23, 2023Recent years have witnessed the success of introducing Transformers to time series forecasting. From a data generation perspective, we illustrate that existing Transformers are susceptible to distribution shifts driven by temporal contexts, whether observed or unobserved. Such context-driven distribution shift (CDS) introduces biases in predictions within specific contexts and poses challenges for conventional training paradigm. In this paper, we introduce a universal calibration methodology for the detection and adaptation of CDS with a trained Transformer model. To this end, we propose a novel CDS detector, termed the "residual-based CDS detector" or "Reconditionor", which quantifies the model's vulnerability to CDS by evaluating the mutual information between prediction residuals and their corresponding contexts. A high Reconditionor score indicates a severe susceptibility, thereby necessitating model adaptation. In this circumstance, we put forth a straightforward yet potent adapter framework for model calibration, termed the "sample-level contextualized adapter" or "SOLID". This framework involves the curation of a contextually similar dataset to the provided test sample and the subsequent fine-tuning of the model's prediction layer with a limited number of steps. Our theoretical analysis demonstrates that this adaptation strategy is able to achieve an optimal equilibrium between bias and variance. Notably, our proposed Reconditionor and SOLID are model-agnostic and readily adaptable to a wide range of Transformers. Extensive experiments show that SOLID consistently enhances the performance of current SOTA Transformers on real-world datasets, especially on cases with substantial CDS detected by the proposed Reconditionor, thus validate the effectiveness of the calibration approach.
CHAMP: Efficient Annotation and Consolidation of Cluster Hierarchies
Nov 19, 2023Various NLP tasks require a complex hierarchical structure over nodes, where each node is a cluster of items. Examples include generating entailment graphs, hierarchical cross-document coreference resolution, annotating event and subevent relations, etc. To enable efficient annotation of such hierarchical structures, we release CHAMP, an open source tool allowing to incrementally construct both clusters and hierarchy simultaneously over any type of texts. This incremental approach significantly reduces annotation time compared to the common pairwise annotation approach and also guarantees maintaining transitivity at the cluster and hierarchy levels. Furthermore, CHAMP includes a consolidation mode, where an adjudicator can easily compare multiple cluster hierarchy annotations and resolve disagreements.
Differentiable and accelerated spherical harmonic and Wigner transforms
Nov 24, 2023Many areas of science and engineering encounter data defined on spherical manifolds. Modelling and analysis of spherical data often necessitates spherical harmonic transforms, at high degrees, and increasingly requires efficient computation of gradients for machine learning or other differentiable programming tasks. We develop novel algorithmic structures for accelerated and differentiable computation of generalised Fourier transforms on the sphere $\mathbb{S}^2$ and rotation group $\text{SO}(3)$, i.e. spherical harmonic and Wigner transforms, respectively. We present a recursive algorithm for the calculation of Wigner $d$-functions that is both stable to high harmonic degrees and extremely parallelisable. By tightly coupling this with separable spherical transforms, we obtain algorithms that exhibit an extremely parallelisable structure that is well-suited for the high throughput computing of modern hardware accelerators (e.g. GPUs). We also develop a hybrid automatic and manual differentiation approach so that gradients can be computed efficiently. Our algorithms are implemented within the JAX differentiable programming framework in the S2FFT software code. Numerous samplings of the sphere are supported, including equiangular and HEALPix sampling. Computational errors are at the order of machine precision for spherical samplings that admit a sampling theorem. When benchmarked against alternative C codes we observe up to a 400-fold acceleration. Furthermore, when distributing over multiple GPUs we achieve very close to optimal linear scaling with increasing number of GPUs due to the highly parallelised and balanced nature of our algorithms. Provided access to sufficiently many GPUs our transforms thus exhibit an unprecedented effective linear time complexity.