 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
W-HMR: Human Mesh Recovery in World Space with Weak-supervised Camera Calibration and Orientation Correction
Nov 30, 2023
For a long time, in the field of reconstructing 3D human bodies from monocular images, most methods opted to simplify the task by minimizing the influence of the camera. Using a coarse focal length setting results in the reconstructed bodies not aligning well with distorted images. Ignoring camera rotation leads to an unrealistic reconstructed body pose in world space. Consequently, existing methods' application scenarios are confined to controlled environments. And they struggle to achieve accurate and reasonable reconstruction in world space when confronted with complex and diverse in-the-wild images. To address the above issues, we propose W-HMR, which decouples global body recovery into camera calibration, local body recovery and global body orientation correction. We design the first weak-supervised camera calibration method for body distortion, eliminating dependence on focal length labels and achieving finer mesh-image alignment. We propose a novel orientation correction module to allow the reconstructed human body to remain normal in world space. Decoupling body orientation and body pose enables our model to consider the accuracy in camera coordinate and the reasonableness in world coordinate simultaneously, expanding the range of applications. As a result, W-HMR achieves high-quality reconstruction in dual coordinate systems, particularly in challenging scenes. Codes will be released on https://yw0208.github.io/w-hmr/ after publication.
DeepEn2023: Energy Datasets for Edge Artificial Intelligence
Nov 30, 2023Climate change poses one of the most significant challenges to humanity. As a result of these climatic changes, the frequency of weather, climate, and water-related disasters has multiplied fivefold over the past 50 years, resulting in over 2 million deaths and losses exceeding $3.64 trillion USD. Leveraging AI-powered technologies for sustainable development and combating climate change is a promising avenue. Numerous significant publications are dedicated to using AI to improve renewable energy forecasting, enhance waste management, and monitor environmental changes in real time. However, very few research studies focus on making AI itself environmentally sustainable. This oversight regarding the sustainability of AI within the field might be attributed to a mindset gap and the absence of comprehensive energy datasets. In addition, with the ubiquity of edge AI systems and applications, especially on-device learning, there is a pressing need to measure, analyze, and optimize their environmental sustainability, such as energy efficiency. To this end, in this paper, we propose large-scale energy datasets for edge AI, named DeepEn2023, covering a wide range of kernels, state-of-the-art deep neural network models, and popular edge AI applications. We anticipate that DeepEn2023 will improve transparency in sustainability in on-device deep learning across a range of edge AI systems and applications. For more information, including access to the dataset and code, please visit https://amai-gsu.github.io/DeepEn2023.
PDB-Struct: A Comprehensive Benchmark for Structure-based Protein Design
Nov 30, 2023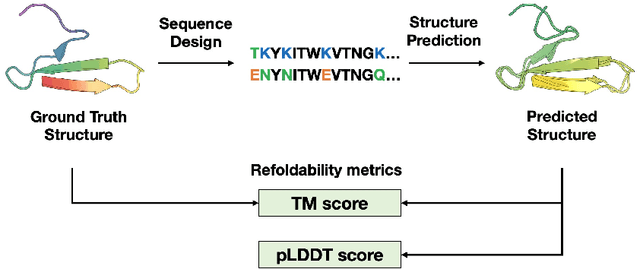



Structure-based protein design has attracted increasing interest, with numerous methods being introduced in recent years. However, a universally accepted method for evaluation has not been established, since the wet-lab validation can be overly time-consuming for the development of new algorithms, and the $\textit{in silico}$ validation with recovery and perplexity metrics is efficient but may not precisely reflect true foldability. To address this gap, we introduce two novel metrics: refoldability-based metric, which leverages high-accuracy protein structure prediction models as a proxy for wet lab experiments, and stability-based metric, which assesses whether models can assign high likelihoods to experimentally stable proteins. We curate datasets from high-quality CATH protein data, high-throughput $\textit{de novo}$ designed proteins, and mega-scale experimental mutagenesis experiments, and in doing so, present the $\textbf{PDB-Struct}$ benchmark that evaluates both recent and previously uncompared protein design methods. Experimental results indicate that ByProt, ProteinMPNN, and ESM-IF perform exceptionally well on our benchmark, while ESM-Design and AF-Design fall short on the refoldability metric. We also show that while some methods exhibit high sequence recovery, they do not perform as well on our new benchmark. Our proposed benchmark paves the way for a fair and comprehensive evaluation of protein design methods in the future. Code is available at https://github.com/WANG-CR/PDB-Struct.
Creator Context for Tweet Recommendation
Nov 29, 2023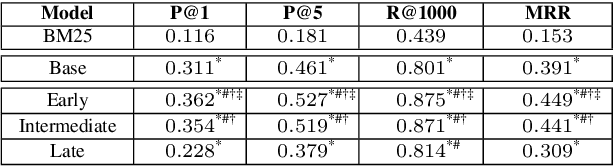

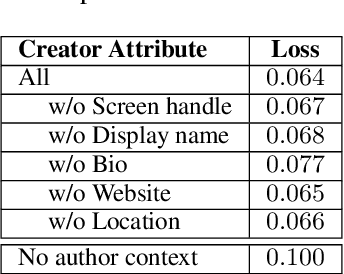
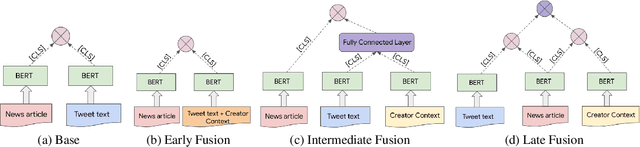
When discussing a tweet, people usually not only refer to the content it delivers, but also to the person behind the tweet. In other words, grounding the interpretation of the tweet in the context of its creator plays an important role in deciphering the true intent and the importance of the tweet. In this paper, we attempt to answer the question of how creator context should be used to advance tweet understanding. Specifically, we investigate the usefulness of different types of creator context, and examine different model structures for incorporating creator context in tweet modeling. We evaluate our tweet understanding models on a practical use case -- recommending relevant tweets to news articles. This use case already exists in popular news apps, and can also serve as a useful assistive tool for journalists. We discover that creator context is essential for tweet understanding, and can improve application metrics by a large margin. However, we also observe that not all creator contexts are equal. Creator context can be time sensitive and noisy. Careful creator context selection and deliberate model structure design play an important role in creator context effectiveness.
Algorithmic Persuasion Through Simulation: Information Design in the Age of Generative AI
Nov 29, 2023How can an informed sender persuade a receiver, having only limited information about the receiver's beliefs? Motivated by research showing generative AI can simulate economic agents, we initiate the study of information design with an oracle. We assume the sender can learn more about the receiver by querying this oracle, e.g., by simulating the receiver's behavior. Aside from AI motivations such as general-purpose Large Language Models (LLMs) and problem-specific machine learning models, alternate motivations include customer surveys and querying a small pool of live users. Specifically, we study Bayesian Persuasion where the sender has a second-order prior over the receiver's beliefs. After a fixed number of queries to an oracle to refine this prior, the sender commits to an information structure. Upon receiving the message, the receiver takes a payoff-relevant action maximizing her expected utility given her posterior beliefs. We design polynomial-time querying algorithms that optimize the sender's expected utility in this Bayesian Persuasion game. As a technical contribution, we show that queries form partitions of the space of receiver beliefs that can be used to quantify the sender's knowledge.
Near-Field Wideband Secure Communications: An Analog Beamfocusing Approach
Nov 29, 2023In the rapidly advancing landscape of 6G, characterized by ultra-high-speed wideband transmission in millimeter-wave and terahertz bands, our paper addresses the pivotal task of enhancing physical layer security (PLS) within near-field wideband communications. We introduce true-time delayer (TTD)-incorporated analog beamfocusing techniques designed to address the interplay between near-field propagation and wideband beamsplit, an uncharted domain in existing literature. Our approach to maximizing secrecy rates involves formulating an optimization problem for joint power allocation and analog beamformer design, employing a two-stage process encompassing a semi-digital solution and analog approximation. This problem is efficiently solved through a combination of alternating optimization, fractional programming, and block successive upper-bound minimization techniques. Additionally, we present a low-complexity beamsplit-aware beamfocusing strategy, capitalizing on geometric insights from near-field wideband propagation, which can also serve as a robust initial value for the optimization-based approach. Numerical results substantiate the efficacy of the proposed methods, clearly demonstrating their superiority over TTD-free approaches in fortifying wideband PLS, as well as the advantageous secrecy energy efficiency achieved by leveraging low-cost analog devices.
HyperAttention: Long-context Attention in Near-Linear Time
Oct 11, 2023We present an approximate attention mechanism named HyperAttention to address the computational challenges posed by the growing complexity of long contexts used in Large Language Models (LLMs). Recent work suggests that in the worst-case scenario, quadratic time is necessary unless the entries of the attention matrix are bounded or the matrix has low stable rank. We introduce two parameters which measure: (1) the max column norm in the normalized attention matrix, and (2) the ratio of row norms in the unnormalized attention matrix after detecting and removing large entries. We use these fine-grained parameters to capture the hardness of the problem. Despite previous lower bounds, we are able to achieve a linear time sampling algorithm even when the matrix has unbounded entries or a large stable rank, provided the above parameters are small. HyperAttention features a modular design that easily accommodates integration of other fast low-level implementations, particularly FlashAttention. Empirically, employing Locality Sensitive Hashing (LSH) to identify large entries, HyperAttention outperforms existing methods, giving significant speed improvements compared to state-of-the-art solutions like FlashAttention. We validate the empirical performance of HyperAttention on a variety of different long-context length datasets. For example, HyperAttention makes the inference time of ChatGLM2 50\% faster on 32k context length while perplexity increases from 5.6 to 6.3. On larger context length, e.g., 131k, with causal masking, HyperAttention offers 5-fold speedup on a single attention layer.
Extraction of n = 0 pick-up by locked mode detectors based on neural networks in J-TEXT
Nov 23, 2023Measurement of locked mode (LM) is important for the physical research of Magnetohydrodynamic (MHD) instabilities and plasma disruption. The n = 0 pick-up need to be extracted and subtracted to calculate the amplitude and phase of the LM. A new method to extract this pick-up has been developed by predicting the n = 0 pick-up brn=0 by the LM detectors based on Neural Networks (NNs) in J-TEXT. An approach called Power Multiple Time Scale (PMTS) has been developed with outstanding regressing effect in multiple frequency ranges. Three models have been progressed based on PMTS NNs. PMTS could fit the brn=0 on the LM detectors with little errors both in time domain and frequency domain. The n>0 pick-up brn>0 generated by resonant magnetic perturbations (RMPs) can be obtained after subtracting the extracted brn=0. This new method uses only one LM instead of 4 LM detectors to extract brn=0. Therefore, the distribution of the LM detectors can also be optimized based on this new method.
Digital Twin-Native AI-Driven Service Architecture for Industrial Networks
Nov 24, 2023The dramatic increase in the connectivity demand results in an excessive amount of Internet of Things (IoT) sensors. To meet the management needs of these large-scale networks, such as accurate monitoring and learning capabilities, Digital Twin (DT) is the key enabler. However, current attempts regarding DT implementations remain insufficient due to the perpetual connectivity requirements of IoT networks. Furthermore, the sensor data streaming in IoT networks cause higher processing time than traditional methods. In addition to these, the current intelligent mechanisms cannot perform well due to the spatiotemporal changes in the implemented IoT network scenario. To handle these challenges, we propose a DT-native AI-driven service architecture in support of the concept of IoT networks. Within the proposed DT-native architecture, we implement a TCP-based data flow pipeline and a Reinforcement Learning (RL)-based learner model. We apply the proposed architecture to one of the broad concepts of IoT networks, the Internet of Vehicles (IoV). We measure the efficiency of our proposed architecture and note ~30% processing time-saving thanks to the TCP-based data flow pipeline. Moreover, we test the performance of the learner model by applying several learning rate combinations for actor and critic networks and highlight the most successive model.
Toward a Foundation Model for Time Series Data
Oct 05, 2023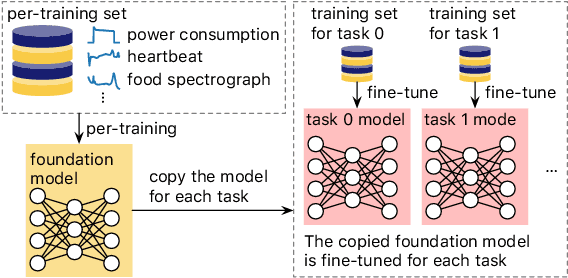
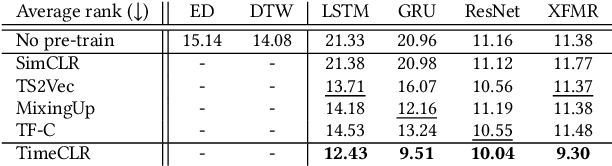
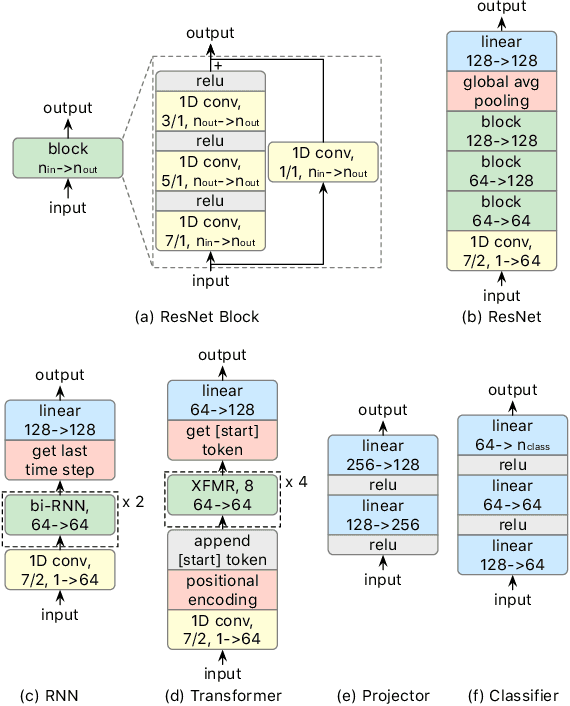
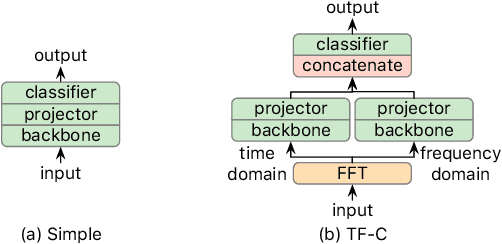
A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.