 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Segment Anything Model-guided Collaborative Learning Network for Scribble-supervised Polyp Segmentation
Dec 01, 2023
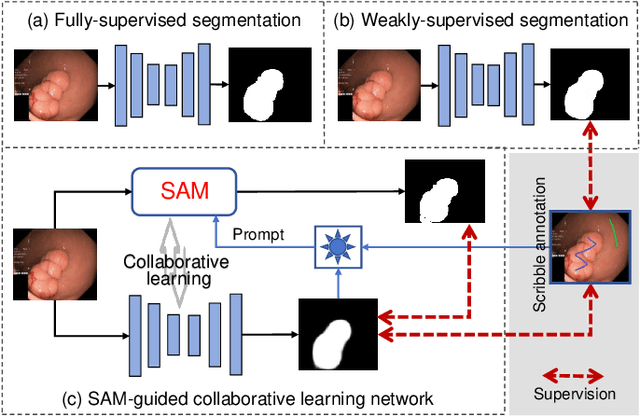
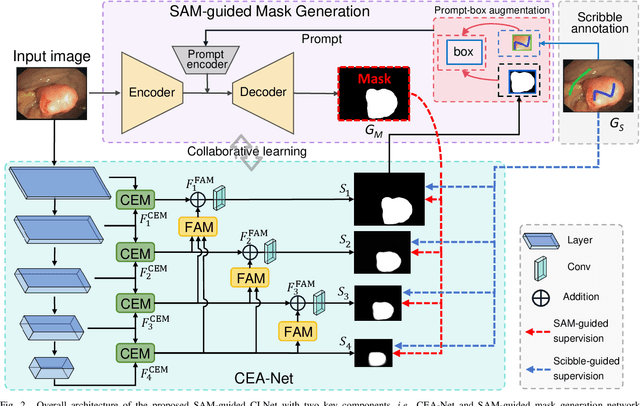
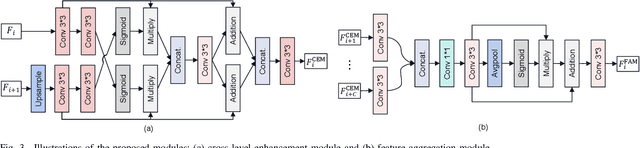
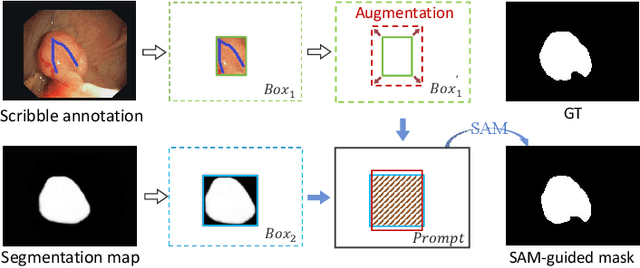
Polyp segmentation plays a vital role in accurately locating polyps at an early stage, which holds significant clinical importance for the prevention of colorectal cancer. Various polyp segmentation methods have been developed using fully-supervised deep learning techniques. However, pixel-wise annotation for polyp images by physicians during the diagnosis is both time-consuming and expensive. Moreover, visual foundation models such as the Segment Anything Model (SAM) have shown remarkable performance. Nevertheless, directly applying SAM to medical segmentation may not produce satisfactory results due to the inherent absence of medical knowledge. In this paper, we propose a novel SAM-guided Collaborative Learning Network (SAM-CLNet) for scribble-supervised polyp segmentation, enabling a collaborative learning process between our segmentation network and SAM to boost the model performance. Specifically, we first propose a Cross-level Enhancement and Aggregation Network (CEA-Net) for weakly-supervised polyp segmentation. Within CEA-Net, we propose a Cross-level Enhancement Module (CEM) that integrates the adjacent features to enhance the representation capabilities of different resolution features. Additionally, a Feature Aggregation Module (FAM) is employed to capture richer features across multiple levels. Moreover, we present a box-augmentation strategy that combines the segmentation maps generated by CEA-Net with scribble annotations to create more precise prompts. These prompts are then fed into SAM, generating segmentation SAM-guided masks, which can provide additional supervision to train CEA-Net effectively. Furthermore, we present an Image-level Filtering Mechanism to filter out unreliable SAM-guided masks. Extensive experimental results show that our SAM-CLNet outperforms state-of-the-art weakly-supervised segmentation methods.
HyperAttention: Long-context Attention in Near-Linear Time
Oct 11, 2023We present an approximate attention mechanism named HyperAttention to address the computational challenges posed by the growing complexity of long contexts used in Large Language Models (LLMs). Recent work suggests that in the worst-case scenario, quadratic time is necessary unless the entries of the attention matrix are bounded or the matrix has low stable rank. We introduce two parameters which measure: (1) the max column norm in the normalized attention matrix, and (2) the ratio of row norms in the unnormalized attention matrix after detecting and removing large entries. We use these fine-grained parameters to capture the hardness of the problem. Despite previous lower bounds, we are able to achieve a linear time sampling algorithm even when the matrix has unbounded entries or a large stable rank, provided the above parameters are small. HyperAttention features a modular design that easily accommodates integration of other fast low-level implementations, particularly FlashAttention. Empirically, employing Locality Sensitive Hashing (LSH) to identify large entries, HyperAttention outperforms existing methods, giving significant speed improvements compared to state-of-the-art solutions like FlashAttention. We validate the empirical performance of HyperAttention on a variety of different long-context length datasets. For example, HyperAttention makes the inference time of ChatGLM2 50\% faster on 32k context length while perplexity increases from 5.6 to 6.3. On larger context length, e.g., 131k, with causal masking, HyperAttention offers 5-fold speedup on a single attention layer.
Toward a Foundation Model for Time Series Data
Oct 05, 2023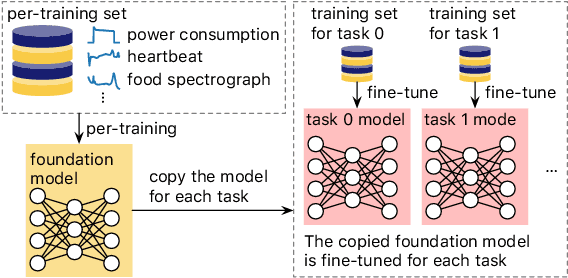
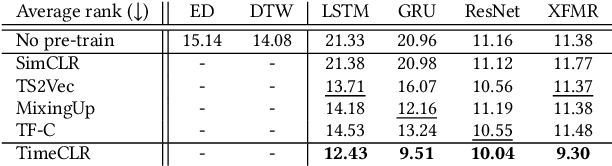
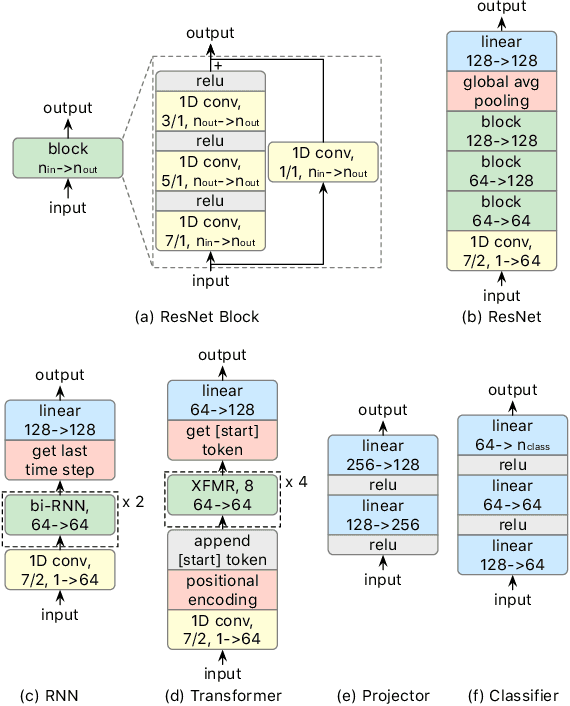
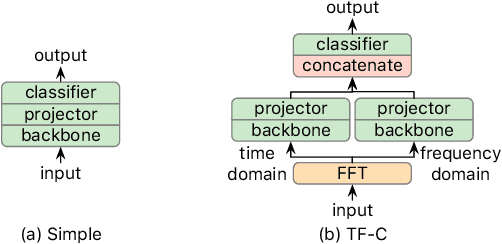
A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.
Time-Variant Overlap-Add in Partitions
Sep 30, 2023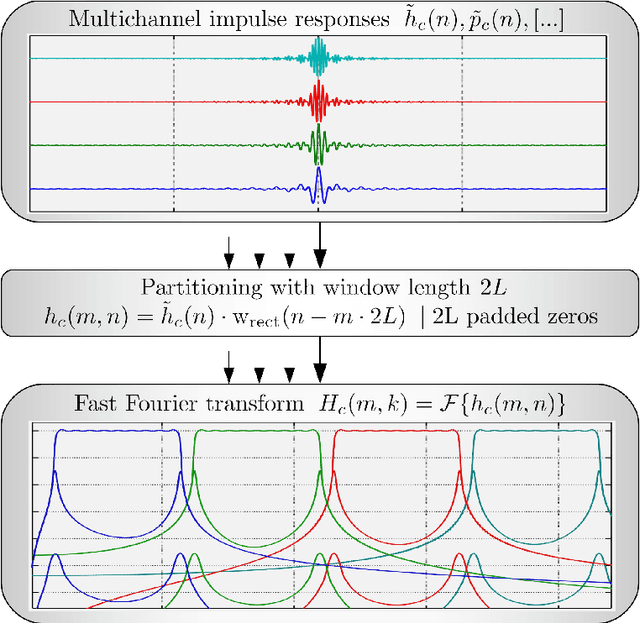
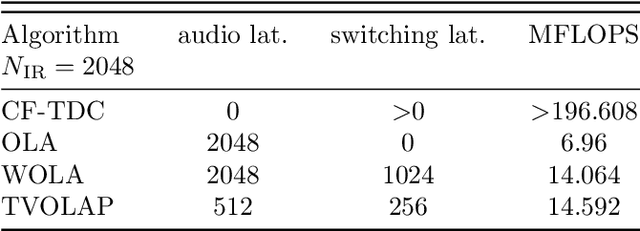
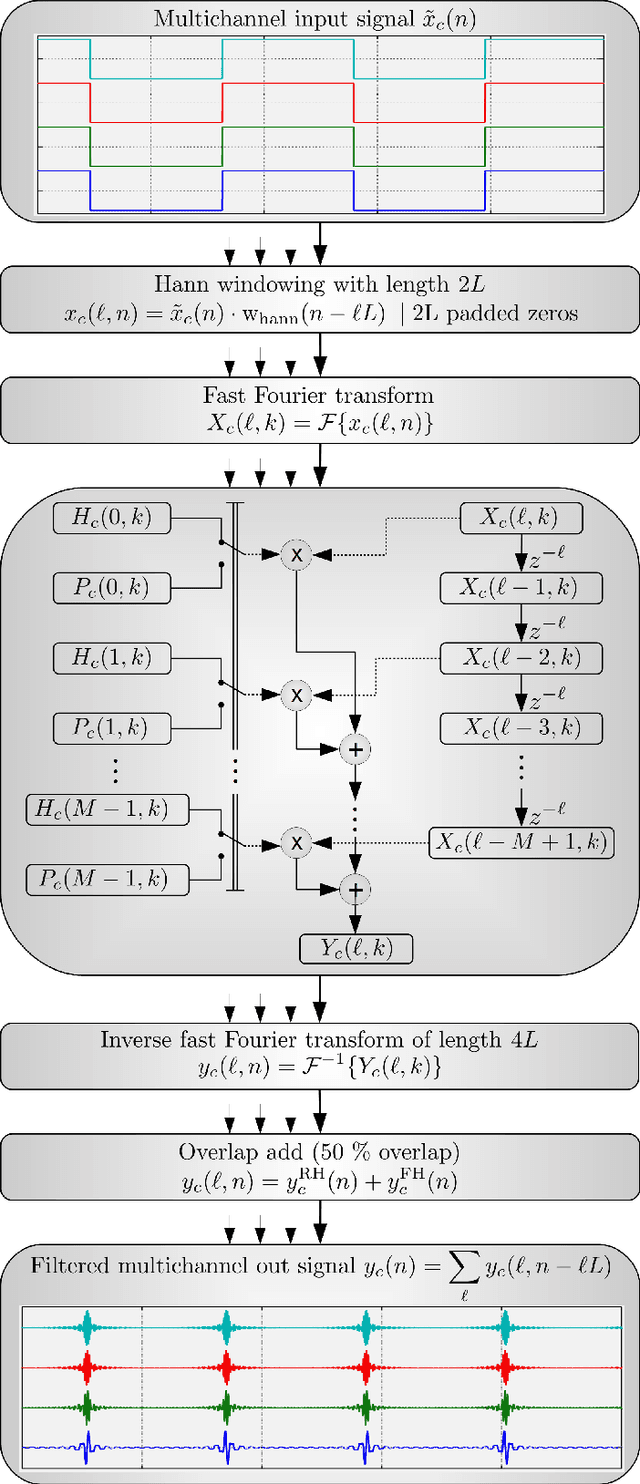

Virtual and augmented realities are increasingly popular tools in many domains such as architecture, production, training and education, (psycho)therapy, gaming, and others. For a convincing rendering of sound in virtual and augmented environments, audio signals must be convolved in real-time with impulse responses that change from one moment in time to another. Key requirements for the implementation of such time-variant real-time convolution algorithms are short latencies, moderate computational cost and memory footprint, and no perceptible switching artifacts. In this engineering report, we introduce a partitioned convolution algorithm that is able to quickly switch between impulse responses without introducing perceptible artifacts, while maintaining a constant computational load and low memory usage. Implementations in several popular programming languages are freely available via GitHub.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
SplitNeRF: Split Sum Approximation Neural Field for Joint Geometry, Illumination, and Material Estimation
Nov 28, 2023We present a novel approach for digitizing real-world objects by estimating their geometry, material properties, and environmental lighting from a set of posed images with fixed lighting. Our method incorporates into Neural Radiance Field (NeRF) pipelines the split sum approximation used with image-based lighting for real-time physical-based rendering. We propose modeling the scene's lighting with a single scene-specific MLP representing pre-integrated image-based lighting at arbitrary resolutions. We achieve accurate modeling of pre-integrated lighting by exploiting a novel regularizer based on efficient Monte Carlo sampling. Additionally, we propose a new method of supervising self-occlusion predictions by exploiting a similar regularizer based on Monte Carlo sampling. Experimental results demonstrate the efficiency and effectiveness of our approach in estimating scene geometry, material properties, and lighting. Our method is capable of attaining state-of-the-art relighting quality after only ${\sim}1$ hour of training in a single NVIDIA A100 GPU.
GeoScaler: Geometry and Rendering-Aware Downsampling of 3D Mesh Textures
Nov 28, 2023High-resolution texture maps are necessary for representing real-world objects accurately with 3D meshes. The large sizes of textures can bottleneck the real-time rendering of high-quality virtual 3D scenes on devices having low computational budgets and limited memory. Downsampling the texture maps directly addresses the issue, albeit at the cost of visual fidelity. Traditionally, downsampling of texture maps is performed using methods like bicubic interpolation and the Lanczos algorithm. These methods ignore the geometric layout of the mesh and its UV parametrization and also do not account for the rendering process used to obtain the final visualization that the users will experience. Towards filling these gaps, we introduce GeoScaler, which is a method of downsampling texture maps of 3D meshes while incorporating geometric cues, and by maximizing the visual fidelity of the rendered views of the textured meshes. We show that the textures generated by GeoScaler deliver significantly better quality rendered images compared to those generated by traditional downsampling methods
CompenHR: Efficient Full Compensation for High-resolution Projector
Nov 28, 2023Full projector compensation is a practical task of projector-camera systems. It aims to find a projector input image, named compensation image, such that when projected it cancels the geometric and photometric distortions due to the physical environment and hardware. State-of-the-art methods use deep learning to address this problem and show promising performance for low-resolution setups. However, directly applying deep learning to high-resolution setups is impractical due to the long training time and high memory cost. To address this issue, this paper proposes a practical full compensation solution. Firstly, we design an attention-based grid refinement network to improve geometric correction quality. Secondly, we integrate a novel sampling scheme into an end-to-end compensation network to alleviate computation and introduce attention blocks to preserve key features. Finally, we construct a benchmark dataset for high-resolution projector full compensation. In experiments, our method demonstrates clear advantages in both efficiency and quality.
Understanding Practices around Computational News Discovery Tools in the Domain of Science Journalism
Nov 28, 2023Science and technology journalists today face challenges in finding newsworthy leads due to increased workloads, reduced resources, and expanding scientific publishing ecosystems. Given this context, we explore computational methods to aid these journalists' news discovery in terms of time-efficiency and agency. In particular, we prototyped three computational information subsidies into an interactive tool that we used as a probe to better understand how such a tool may offer utility or more broadly shape the practices of professional science journalists. Our findings highlight central considerations around science journalists' agency, context, and responsibilities that such tools can influence and could account for in design. Based on this, we suggest design opportunities for greater and longer-term user agency; incorporating contextual, personal and collaborative notions of newsworthiness; and leveraging flexible interfaces and generative models. Overall, our findings contribute a richer view of the sociotechnical system around computational news discovery tools, and suggest ways to improve such tools to better support the practices of science journalists.
Marine$\mathcal{X}$: Design and Implementation of Unmanned Surface Vessel for Vision Guided Navigation
Nov 28, 2023
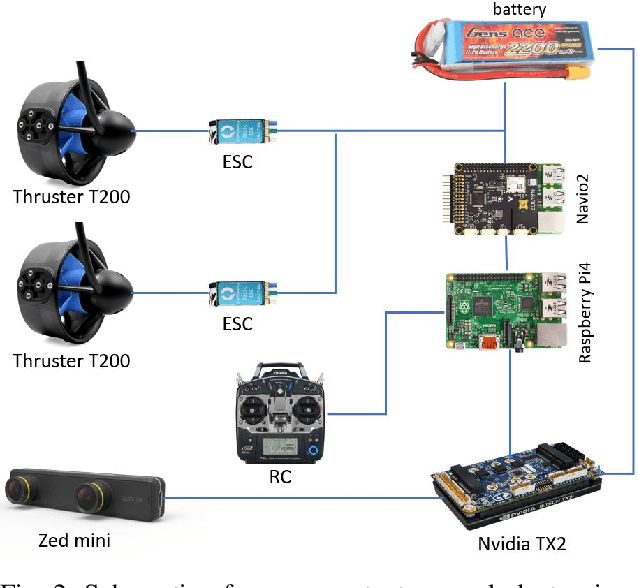
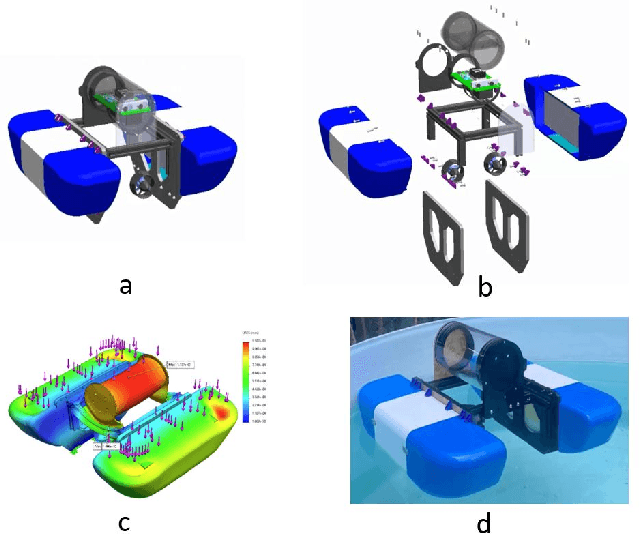
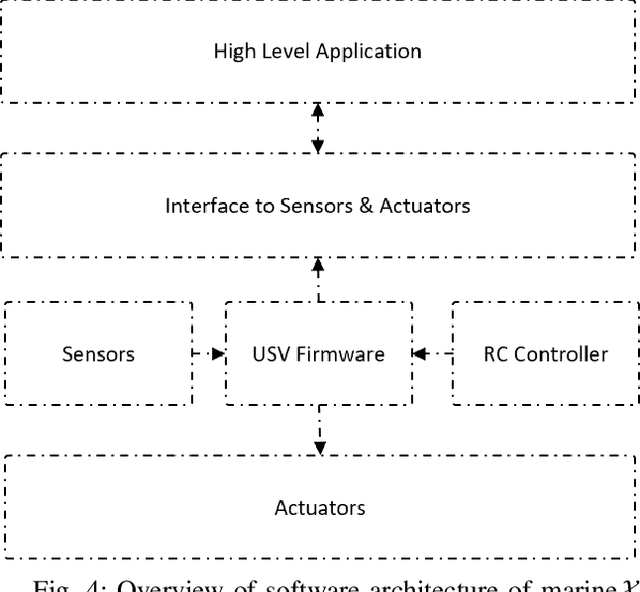
Marine robots, particularly Unmanned Surface Vessels (USVs), have gained considerable attention for their diverse applications in maritime tasks, including search and rescue, environmental monitoring, and maritime security. This paper presents the design and implementation of a USV named marine$\mathcal{X}$. The hardware components of marine$\mathcal{X}$ are meticulously developed to ensure robustness, efficiency, and adaptability to varying environmental conditions. Furthermore, the integration of a vision-based object tracking algorithm empowers marine$\mathcal{X}$ to autonomously track and monitor specific objects on the water surface. The control system utilizes PID control, enabling precise navigation of marine$\mathcal{X}$ while maintaining a desired course and distance to the target object. To assess the performance of marine$\mathcal{X}$, comprehensive testing is conducted, encompassing simulation, trials in the marine pool, and real-world tests in the open sea. The successful outcomes of these tests demonstrate the USV's capabilities in achieving real-time object tracking, showcasing its potential for various applications in maritime operations.
* accepted in ICAR