 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Individualized Dynamic Latent Factor Model with Application to Mobile Health Data
Nov 21, 2023
Mobile health has emerged as a major success in tracking individual health status, due to the popularity and power of smartphones and wearable devices. This has also brought great challenges in handling heterogeneous, multi-resolution data which arise ubiquitously in mobile health due to irregular multivariate measurements collected from individuals. In this paper, we propose an individualized dynamic latent factor model for irregular multi-resolution time series data to interpolate unsampled measurements of time series with low resolution. One major advantage of the proposed method is the capability to integrate multiple irregular time series and multiple subjects by mapping the multi-resolution data to the latent space. In addition, the proposed individualized dynamic latent factor model is applicable to capturing heterogeneous longitudinal information through individualized dynamic latent factors. In theory, we provide the integrated interpolation error bound of the proposed estimator and derive the convergence rate with B-spline approximation methods. Both the simulation studies and the application to smartwatch data demonstrate the superior performance of the proposed method compared to existing methods.
Harnessing the Power of Prompt-based Techniques for Generating School-Level Questions using Large Language Models
Dec 02, 2023Designing high-quality educational questions is a challenging and time-consuming task. In this work, we propose a novel approach that utilizes prompt-based techniques to generate descriptive and reasoning-based questions. However, current question-answering (QA) datasets are inadequate for conducting our experiments on prompt-based question generation (QG) in an educational setting. Therefore, we curate a new QG dataset called EduProbe for school-level subjects, by leveraging the rich content of NCERT textbooks. We carefully annotate this dataset as quadruples of 1) Context: a segment upon which the question is formed; 2) Long Prompt: a long textual cue for the question (i.e., a longer sequence of words or phrases, covering the main theme of the context); 3) Short Prompt: a short textual cue for the question (i.e., a condensed representation of the key information or focus of the context); 4) Question: a deep question that aligns with the context and is coherent with the prompts. We investigate several prompt-based QG methods by fine-tuning pre-trained transformer-based large language models (LLMs), namely PEGASUS, T5, MBART, and BART. Moreover, we explore the performance of two general-purpose pre-trained LLMs such as Text-Davinci-003 and GPT-3.5-Turbo without any further training. By performing automatic evaluation, we show that T5 (with long prompt) outperforms all other models, but still falls short of the human baseline. Under human evaluation criteria, TextDavinci-003 usually shows better results than other models under various prompt settings. Even in the case of human evaluation criteria, QG models mostly fall short of the human baseline. Our code and dataset are available at: https://github.com/my625/PromptQG
A statistical approach to latent dynamic modeling with differential equations
Nov 27, 2023Ordinary differential equations (ODEs) can provide mechanistic models of temporally local changes of processes, where parameters are often informed by external knowledge. While ODEs are popular in systems modeling, they are less established for statistical modeling of longitudinal cohort data, e.g., in a clinical setting. Yet, modeling of local changes could also be attractive for assessing the trajectory of an individual in a cohort in the immediate future given its current status, where ODE parameters could be informed by further characteristics of the individual. However, several hurdles so far limit such use of ODEs, as compared to regression-based function fitting approaches. The potentially higher level of noise in cohort data might be detrimental to ODEs, as the shape of the ODE solution heavily depends on the initial value. In addition, larger numbers of variables multiply such problems and might be difficult to handle for ODEs. To address this, we propose to use each observation in the course of time as the initial value to obtain multiple local ODE solutions and build a combined estimator of the underlying dynamics. Neural networks are used for obtaining a low-dimensional latent space for dynamic modeling from a potentially large number of variables, and for obtaining patient-specific ODE parameters from baseline variables. Simultaneous identification of dynamic models and of a latent space is enabled by recently developed differentiable programming techniques. We illustrate the proposed approach in an application with spinal muscular atrophy patients and a corresponding simulation study. In particular, modeling of local changes in health status at any point in time is contrasted to the interpretation of functions obtained from a global regression. This more generally highlights how different application settings might demand different modeling strategies.
8+8=4: Formalizing Time Units to Handle Symbolic Music Durations
Oct 23, 2023This paper focuses on the nominal durations of musical events (notes and rests) in a symbolic musical score, and on how to conveniently handle these in computer applications. We propose the usage of a temporal unit that is directly related to the graphical symbols in musical scores and pair this with a set of operations that cover typical computations in music applications. We formalize this time unit and the more commonly used approach in a single mathematical framework, as semirings, algebraic structures that enable an abstract description of algorithms/processing pipelines. We then discuss some practical use cases and highlight when our system can improve such pipelines by making them more efficient in terms of data type used and the number of computations.
Fast and Reliable Generation of EHR Time Series via Diffusion Models
Oct 23, 2023Electronic Health Records (EHRs) are rich sources of patient-level data, including laboratory tests, medications, and diagnoses, offering valuable resources for medical data analysis. However, concerns about privacy often restrict access to EHRs, hindering downstream analysis. Researchers have explored various methods for generating privacy-preserving EHR data. In this study, we introduce a new method for generating diverse and realistic synthetic EHR time series data using Denoising Diffusion Probabilistic Models (DDPM). We conducted experiments on six datasets, comparing our proposed method with seven existing methods. Our results demonstrate that our approach significantly outperforms all existing methods in terms of data utility while requiring less training effort. Our approach also enhances downstream medical data analysis by providing diverse and realistic synthetic EHR data.
Adversarial Diffusion Distillation
Nov 28, 2023We introduce Adversarial Diffusion Distillation (ADD), a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1-4 steps while maintaining high image quality. We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps. Our analyses show that our model clearly outperforms existing few-step methods (GANs, Latent Consistency Models) in a single step and reaches the performance of state-of-the-art diffusion models (SDXL) in only four steps. ADD is the first method to unlock single-step, real-time image synthesis with foundation models. Code and weights available under https://github.com/Stability-AI/generative-models and https://huggingface.co/stabilityai/ .
Optimisation-Based Multi-Modal Semantic Image Editing
Nov 28, 2023Image editing affords increased control over the aesthetics and content of generated images. Pre-existing works focus predominantly on text-based instructions to achieve desired image modifications, which limit edit precision and accuracy. In this work, we propose an inference-time editing optimisation, designed to extend beyond textual edits to accommodate multiple editing instruction types (e.g. spatial layout-based; pose, scribbles, edge maps). We propose to disentangle the editing task into two competing subtasks: successful local image modifications and global content consistency preservation, where subtasks are guided through two dedicated loss functions. By allowing to adjust the influence of each loss function, we build a flexible editing solution that can be adjusted to user preferences. We evaluate our method using text, pose and scribble edit conditions, and highlight our ability to achieve complex edits, through both qualitative and quantitative experiments.
Imputation using training labels and classification via label imputation
Nov 28, 2023Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
Robust Diffusion GAN using Semi-Unbalanced Optimal Transport
Nov 28, 2023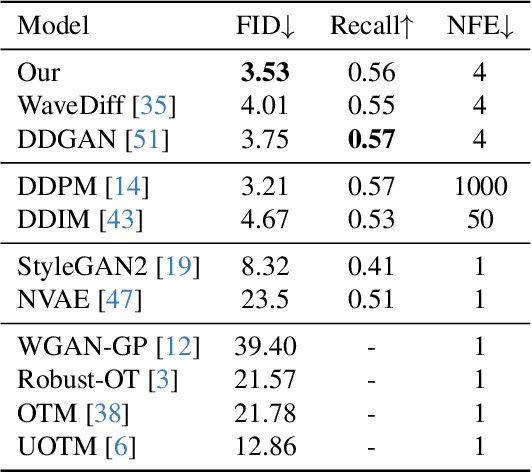

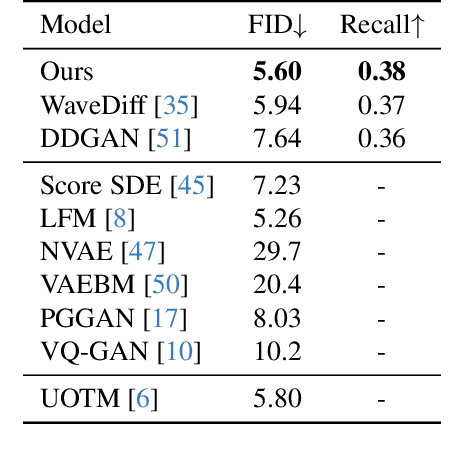
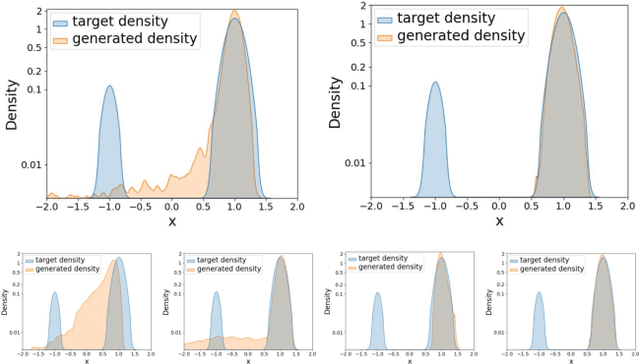
Diffusion models, a type of generative model, have demonstrated great potential for synthesizing highly detailed images. By integrating with GAN, advanced diffusion models like DDGAN \citep{xiao2022DDGAN} could approach real-time performance for expansive practical applications. While DDGAN has effectively addressed the challenges of generative modeling, namely producing high-quality samples, covering different data modes, and achieving faster sampling, it remains susceptible to performance drops caused by datasets that are corrupted with outlier samples. This work introduces a robust training technique based on semi-unbalanced optimal transport to mitigate the impact of outliers effectively. Through comprehensive evaluations, we demonstrate that our robust diffusion GAN (RDGAN) outperforms vanilla DDGAN in terms of the aforementioned generative modeling criteria, i.e., image quality, mode coverage of distribution, and inference speed, and exhibits improved robustness when dealing with both clean and corrupted datasets.
Symmetry-regularized neural ordinary differential equations
Nov 28, 2023Neural Ordinary Differential Equations (Neural ODEs) is a class of deep neural network models that interpret the hidden state dynamics of neural networks as an ordinary differential equation, thereby capable of capturing system dynamics in a continuous time framework. In this work, I integrate symmetry regularization into Neural ODEs. In particular, I use continuous Lie symmetry of ODEs and PDEs associated with the model to derive conservation laws and add them to the loss function, making it physics-informed. This incorporation of inherent structural properties into the loss function could significantly improve robustness and stability of the model during training. To illustrate this method, I employ a toy model that utilizes a cosine rate of change in the hidden state, showcasing the process of identifying Lie symmetries, deriving conservation laws, and constructing a new loss function.