 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TSDF-Sampling: Efficient Sampling for Neural Surface Field using Truncated Signed Distance Field
Nov 29, 2023
Multi-view neural surface reconstruction has exhibited impressive results. However, a notable limitation is the prohibitively slow inference time when compared to traditional techniques, primarily attributed to the dense sampling, required to maintain the rendering quality. This paper introduces a novel approach that substantially reduces the number of samplings by incorporating the Truncated Signed Distance Field (TSDF) of the scene. While prior works have proposed importance sampling, their dependence on initial uniform samples over the entire space makes them unable to avoid performance degradation when trying to use less number of samples. In contrast, our method leverages the TSDF volume generated only by the trained views, and it proves to provide a reasonable bound on the sampling from upcoming novel views. As a result, we achieve high rendering quality by fully exploiting the continuous neural SDF estimation within the bounds given by the TSDF volume. Notably, our method is the first approach that can be robustly plug-and-play into a diverse array of neural surface field models, as long as they use the volume rendering technique. Our empirical results show an 11-fold increase in inference speed without compromising performance. The result videos are available at our project page: https://tsdf-sampling.github.io/
A Unified Approach for Text- and Image-guided 4D Scene Generation
Nov 29, 2023Large-scale diffusion generative models are greatly simplifying image, video and 3D asset creation from user-provided text prompts and images. However, the challenging problem of text-to-4D dynamic 3D scene generation with diffusion guidance remains largely unexplored. We propose Dream-in-4D, which features a novel two-stage approach for text-to-4D synthesis, leveraging (1) 3D and 2D diffusion guidance to effectively learn a high-quality static 3D asset in the first stage; (2) a deformable neural radiance field that explicitly disentangles the learned static asset from its deformation, preserving quality during motion learning; and (3) a multi-resolution feature grid for the deformation field with a displacement total variation loss to effectively learn motion with video diffusion guidance in the second stage. Through a user preference study, we demonstrate that our approach significantly advances image and motion quality, 3D consistency and text fidelity for text-to-4D generation compared to baseline approaches. Thanks to its motion-disentangled representation, Dream-in-4D can also be easily adapted for controllable generation where appearance is defined by one or multiple images, without the need to modify the motion learning stage. Thus, our method offers, for the first time, a unified approach for text-to-4D, image-to-4D and personalized 4D generation tasks.
Explainable Fraud Detection with Deep Symbolic Classification
Dec 01, 2023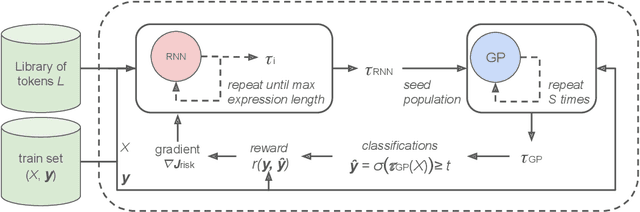

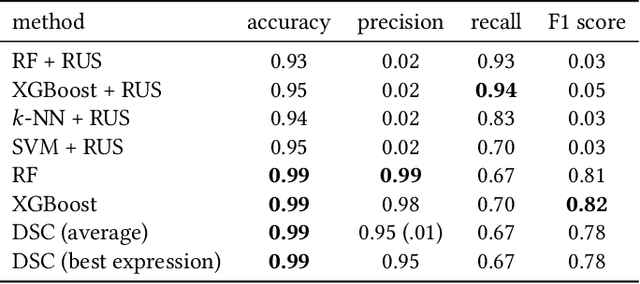
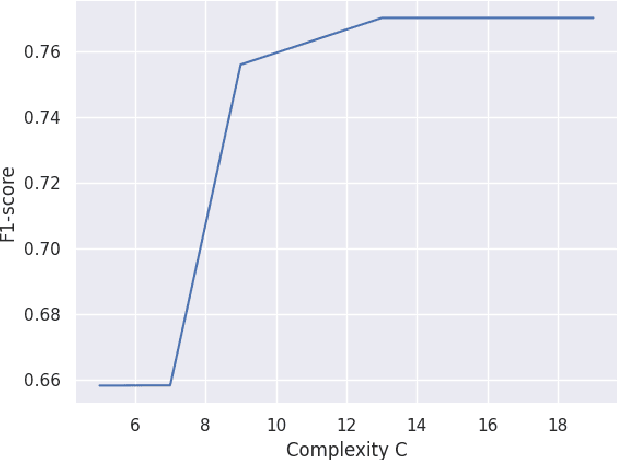
There is a growing demand for explainable, transparent, and data-driven models within the domain of fraud detection. Decisions made by fraud detection models need to be explainable in the event of a customer dispute. Additionally, the decision-making process in the model must be transparent to win the trust of regulators and business stakeholders. At the same time, fraud detection solutions can benefit from data due to the noisy, dynamic nature of fraud and the availability of large historical data sets. Finally, fraud detection is notorious for its class imbalance: there are typically several orders of magnitude more legitimate transactions than fraudulent ones. In this paper, we present Deep Symbolic Classification (DSC), an extension of the Deep Symbolic Regression framework to classification problems. DSC casts classification as a search problem in the space of all analytic functions composed of a vocabulary of variables, constants, and operations and optimizes for an arbitrary evaluation metric directly. The search is guided by a deep neural network trained with reinforcement learning. Because the functions are mathematical expressions that are in closed-form and concise, the model is inherently explainable both at the level of a single classification decision and the model's decision process. Furthermore, the class imbalance problem is successfully addressed by optimizing for metrics that are robust to class imbalance such as the F1 score. This eliminates the need for oversampling and undersampling techniques that plague traditional approaches. Finally, the model allows to explicitly balance between the prediction accuracy and the explainability. An evaluation on the PaySim data set demonstrates competitive predictive performance with state-of-the-art models, while surpassing them in terms of explainability. This establishes DSC as a promising model for fraud detection systems.
A Bayesian approach for prompt optimization in pre-trained language models
Dec 01, 2023A prompt is a sequence of symbol or tokens, selected from a vocabulary according to some rule, which is prepended/concatenated to a textual query. A key problem is how to select the sequence of tokens: in this paper we formulate it as a combinatorial optimization problem. The high dimensionality of the token space com-pounded by the length of the prompt sequence requires a very efficient solution. In this paper we propose a Bayesian optimization method, executed in a continuous em-bedding of the combinatorial space. In this paper we focus on hard prompt tuning (HPT) which directly searches for discrete tokens to be added to the text input with-out requiring access to the large language model (LLM) and can be used also when LLM is available only as a black-box. This is critically important if LLMs are made available in the Model as a Service (MaaS) manner as in GPT-4. The current manu-script is focused on the optimization of discrete prompts for classification tasks. The discrete prompts give rise to difficult combinatorial optimization problem which easily become intractable given the dimension of the token space in realistic applications. The optimization method considered in this paper is Bayesian optimization (BO) which has become the dominant approach in black-box optimization for its sample efficiency along with its modular structure and versatility. In this paper we use BoTorch, a library for Bayesian optimization research built on top of pyTorch. Albeit preliminary and obtained using a 'vanilla' version of BO, the experiments on RoB-ERTa on six benchmarks, show a good performance across a variety of tasks and enable an analysis of the tradeoff between size of the search space, accuracy and wall clock time.
Meta-Diversity Search in Complex Systems, A Recipe for Artificial Open-Endedness ?
Dec 01, 2023Can we build an artificial system that would be able to generate endless surprises if ran "forever" in Minecraft? While there is not a single path toward solving that grand challenge, this article presents what we believe to be some working ingredients for the endless generation of novel increasingly complex artifacts in Minecraft. Our framework for an open-ended system includes two components: a complex system used to recursively grow and complexify artifacts over time, and a discovery algorithm that leverages the concept of meta-diversity search. Since complex systems have shown to enable the emergence of considerable complexity from set of simple rules, we believe them to be great candidates to generate all sort of artifacts in Minecraft. Yet, the space of possible artifacts that can be generated by these systems is often unknown, challenging to characterize and explore. Therefore automating the long-term discovery of novel and increasingly complex artifacts in these systems is an exciting research field. To approach these challenges, we formulate the problem of meta-diversity search where an artificial "discovery assistant" incrementally learns a diverse set of representations to characterize behaviors and searches to discover diverse patterns within each of them. A successful discovery assistant should continuously seek for novel sources of diversities while being able to quickly specialize the search toward a new unknown type of diversity. To implement those ideas in the Minecraft environment, we simulate an artificial "chemistry" system based on Lenia continuous cellular automaton for generating artifacts, as well as an artificial "discovery assistant" (called Holmes) for the artifact-discovery process. Holmes incrementally learns a hierarchy of modular representations to characterize divergent sources of diversity and uses a goal-based intrinsically-motivated exploration as the diversity search strategy.
Tube-NeRF: Efficient Imitation Learning of Visuomotor Policies from MPC using Tube-Guided Data Augmentation and NeRFs
Nov 23, 2023Imitation learning (IL) can train computationally-efficient sensorimotor policies from a resource-intensive Model Predictive Controller (MPC), but it often requires many samples, leading to long training times or limited robustness. To address these issues, we combine IL with a variant of robust MPC that accounts for process and sensing uncertainties, and we design a data augmentation (DA) strategy that enables efficient learning of vision-based policies. The proposed DA method, named Tube-NeRF, leverages Neural Radiance Fields (NeRFs) to generate novel synthetic images, and uses properties of the robust MPC (the tube) to select relevant views and to efficiently compute the corresponding actions. We tailor our approach to the task of localization and trajectory tracking on a multirotor, by learning a visuomotor policy that generates control actions using images from the onboard camera as only source of horizontal position. Our evaluations numerically demonstrate learning of a robust visuomotor policy with an 80-fold increase in demonstration efficiency and a 50% reduction in training time over current IL methods. Additionally, our policies successfully transfer to a real multirotor, achieving accurate localization and low tracking errors despite large disturbances, with an onboard inference time of only 1.5 ms.
MINTY: Rule-based Models that Minimize the Need for Imputing Features with Missing Values
Nov 23, 2023Rule models are often preferred in prediction tasks with tabular inputs as they can be easily interpreted using natural language and provide predictive performance on par with more complex models. However, most rule models' predictions are undefined or ambiguous when some inputs are missing, forcing users to rely on statistical imputation models or heuristics like zero imputation, undermining the interpretability of the models. In this work, we propose fitting concise yet precise rule models that learn to avoid relying on features with missing values and, therefore, limit their reliance on imputation at test time. We develop MINTY, a method that learns rules in the form of disjunctions between variables that act as replacements for each other when one or more is missing. This results in a sparse linear rule model, regularized to have small dependence on features with missing values, that allows a trade-off between goodness of fit, interpretability, and robustness to missing values at test time. We demonstrate the value of MINTY in experiments using synthetic and real-world data sets and find its predictive performance comparable or favorable to baselines, with smaller reliance on features with missing values.
Optimal Power Flow in Highly Renewable Power System Based on Attention Neural Networks
Nov 23, 2023The Optimal Power Flow (OPF) problem is pivotal for power system operations, guiding generator output and power distribution to meet demand at minimized costs, while adhering to physical and engineering constraints. The integration of renewable energy sources, like wind and solar, however, poses challenges due to their inherent variability. This variability, driven largely by changing weather conditions, demands frequent recalibrations of power settings, thus necessitating recurrent OPF resolutions. This task is daunting using traditional numerical methods, particularly for extensive power systems. In this work, we present a cutting-edge, physics-informed machine learning methodology, trained using imitation learning and historical European weather datasets. Our approach directly correlates electricity demand and weather patterns with power dispatch and generation, circumventing the iterative requirements of traditional OPF solvers. This offers a more expedient solution apt for real-time applications. Rigorous evaluations on aggregated European power systems validate our method's superiority over existing data-driven techniques in OPF solving. By presenting a quick, robust, and efficient solution, this research sets a new standard in real-time OPF resolution, paving the way for more resilient power systems in the era of renewable energy.
Data-Driven Risk Modeling for Infrastructure Projects Using Artificial Intelligence Techniques
Nov 23, 2023Managing project risk is a key part of the successful implementation of any large project and is widely recognized as a best practice for public agencies to deliver infrastructures. The conventional method of identifying and evaluating project risks involves getting input from subject matter experts at risk workshops in the early phases of a project. As a project moves through its life cycle, these identified risks and their assessments evolve. Some risks are realized to become issues, some are mitigated, and some are retired as no longer important. Despite the value provided by conventional expert-based approaches, several challenges remain due to the time-consuming and expensive processes involved. Moreover, limited is known about how risks evolve from ex-ante to ex-post over time. How well does the project team identify and evaluate risks in the initial phase compared to what happens during project execution? Using historical data and artificial intelligence techniques, this study addressed these limitations by introducing a data-driven framework to identify risks automatically and to examine the quality of early risk registers and risk assessments. Risk registers from more than 70 U.S. major transportation projects form the input dataset.
Advancing Test-Time Adaptation for Acoustic Foundation Models in Open-World Shifts
Oct 14, 2023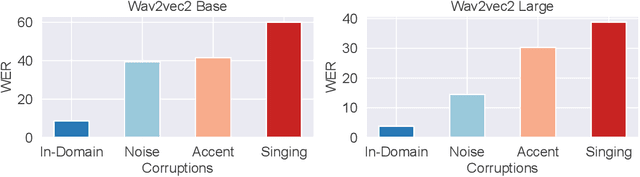
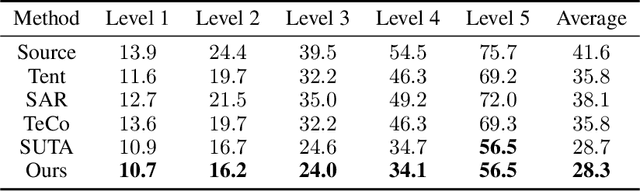
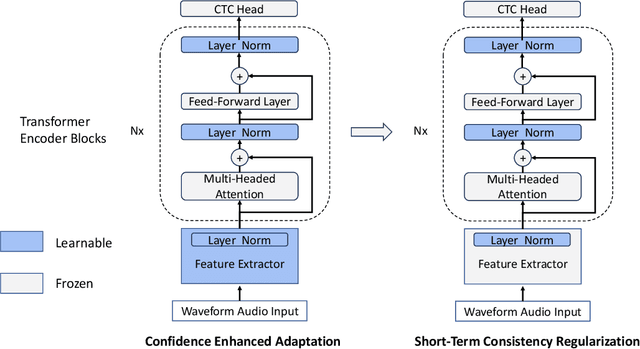
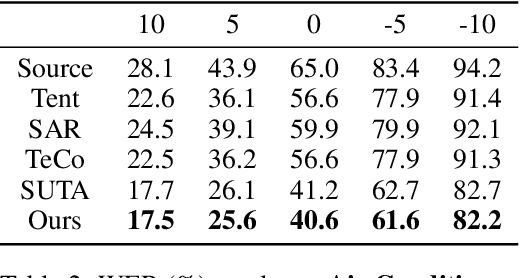
Test-Time Adaptation (TTA) is a critical paradigm for tackling distribution shifts during inference, especially in visual recognition tasks. However, while acoustic models face similar challenges due to distribution shifts in test-time speech, TTA techniques specifically designed for acoustic modeling in the context of open-world data shifts remain scarce. This gap is further exacerbated when considering the unique characteristics of acoustic foundation models: 1) they are primarily built on transformer architectures with layer normalization and 2) they deal with test-time speech data of varying lengths in a non-stationary manner. These aspects make the direct application of vision-focused TTA methods, which are mostly reliant on batch normalization and assume independent samples, infeasible. In this paper, we delve into TTA for pre-trained acoustic models facing open-world data shifts. We find that noisy, high-entropy speech frames, often non-silent, carry key semantic content. Traditional TTA methods might inadvertently filter out this information using potentially flawed heuristics. In response, we introduce a heuristic-free, learning-based adaptation enriched by confidence enhancement. Noting that speech signals' short-term consistency, we also apply consistency regularization during test-time optimization. Our experiments on synthetic and real-world datasets affirm our method's superiority over existing baselines.