 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable AI in Diagnosing and Anticipating Leukemia Using Transfer Learning Method
Dec 01, 2023
This research paper focuses on Acute Lymphoblastic Leukemia (ALL), a form of blood cancer prevalent in children and teenagers, characterized by the rapid proliferation of immature white blood cells (WBCs). These atypical cells can overwhelm healthy cells, leading to severe health consequences. Early and accurate detection of ALL is vital for effective treatment and improving survival rates. Traditional diagnostic methods are time-consuming, costly, and prone to errors. The paper proposes an automated detection approach using computer-aided diagnostic (CAD) models, leveraging deep learning techniques to enhance the accuracy and efficiency of leukemia diagnosis. The study utilizes various transfer learning models like ResNet101V2, VGG19, InceptionV3, and InceptionResNetV2 for classifying ALL. The methodology includes using the Local Interpretable Model-Agnostic Explanations (LIME) for ensuring the validity and reliability of the AI system's predictions. This approach is critical for overcoming the "black box" nature of AI, where decisions made by models are often opaque and unaccountable. The paper highlights that the proposed method using the InceptionV3 model achieved an impressive 98.38% accuracy, outperforming other tested models. The results, verified by the LIME algorithm, showcase the potential of this method in accurately identifying ALL, providing a valuable tool for medical practitioners. The research underscores the impact of explainable artificial intelligence (XAI) in medical diagnostics, paving the way for more transparent and trustworthy AI applications in healthcare.
Temperature Balancing, Layer-wise Weight Analysis, and Neural Network Training
Dec 01, 2023Regularization in modern machine learning is crucial, and it can take various forms in algorithmic design: training set, model family, error function, regularization terms, and optimizations. In particular, the learning rate, which can be interpreted as a temperature-like parameter within the statistical mechanics of learning, plays a crucial role in neural network training. Indeed, many widely adopted training strategies basically just define the decay of the learning rate over time. This process can be interpreted as decreasing a temperature, using either a global learning rate (for the entire model) or a learning rate that varies for each parameter. This paper proposes TempBalance, a straightforward yet effective layer-wise learning rate method. TempBalance is based on Heavy-Tailed Self-Regularization (HT-SR) Theory, an approach which characterizes the implicit self-regularization of different layers in trained models. We demonstrate the efficacy of using HT-SR-motivated metrics to guide the scheduling and balancing of temperature across all network layers during model training, resulting in improved performance during testing. We implement TempBalance on CIFAR10, CIFAR100, SVHN, and TinyImageNet datasets using ResNets, VGGs, and WideResNets with various depths and widths. Our results show that TempBalance significantly outperforms ordinary SGD and carefully-tuned spectral norm regularization. We also show that TempBalance outperforms a number of state-of-the-art optimizers and learning rate schedulers.
Decision Tree Psychological Risk Assessment in Currency Trading
Dec 01, 2023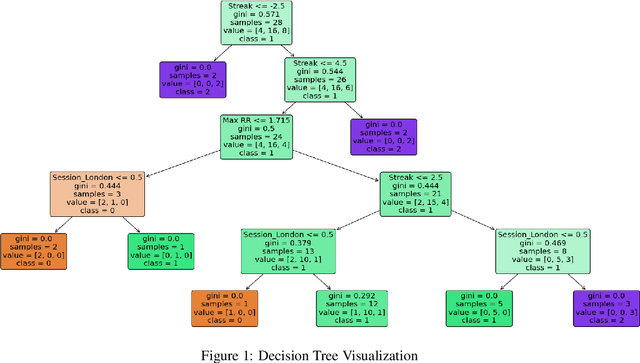
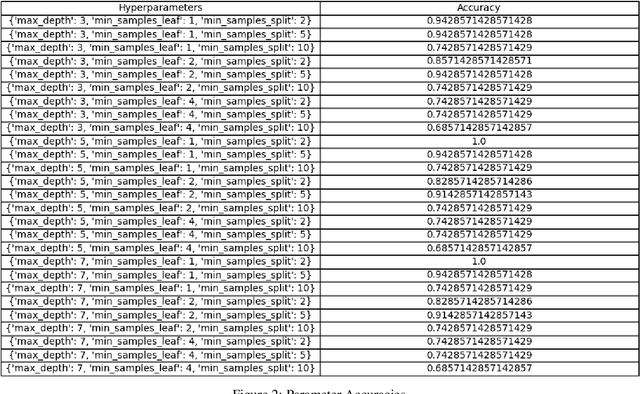
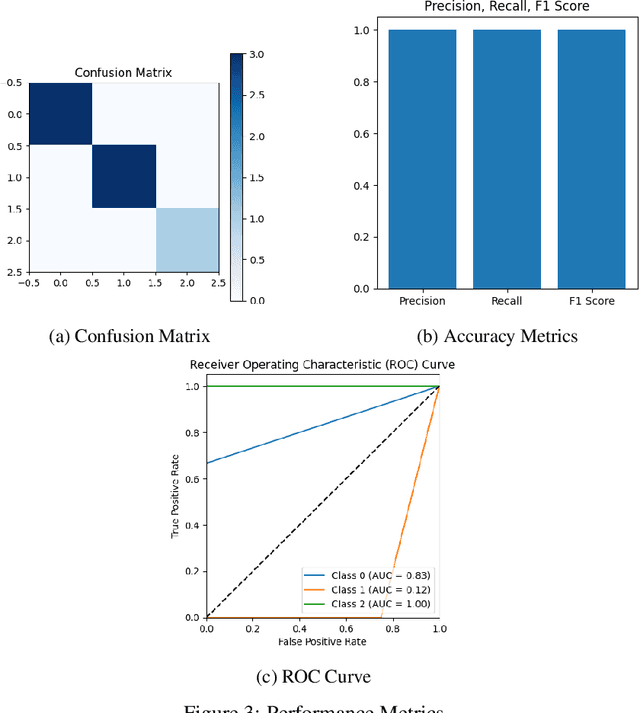
This research paper focuses on the integration of Artificial Intelligence (AI) into the currency trading landscape, positing the development of personalized AI models, essentially functioning as intelligent personal assistants tailored to the idiosyncrasies of individual traders. The paper posits that AI models are capable of identifying nuanced patterns within the trader's historical data, facilitating a more accurate and insightful assessment of psychological risk dynamics in currency trading. The PRI is a dynamic metric that experiences fluctuations in response to market conditions that foster psychological fragility among traders. By employing sophisticated techniques, a classifying decision tree is crafted, enabling clearer decision-making boundaries within the tree structure. By incorporating the user's chronological trade entries, the model becomes adept at identifying critical junctures when psychological risks are heightened. The real-time nature of the calculations enhances the model's utility as a proactive tool, offering timely alerts to traders about impending moments of psychological risks. The implications of this research extend beyond the confines of currency trading, reaching into the realms of other industries where the judicious application of personalized modeling emerges as an efficient and strategic approach. This paper positions itself at the intersection of cutting-edge technology and the intricate nuances of human psychology, offering a transformative paradigm for decision making support in dynamic and high-pressure environments.
Appearance Codes using Joint Embedding Learning of Multiple Modalities
Nov 19, 2023The use of appearance codes in recent work on generative modeling has enabled novel view renders with variable appearance and illumination, such as day-time and night-time renders of a scene. A major limitation of this technique is the need to re-train new appearance codes for every scene on inference, so in this work we address this problem proposing a framework that learns a joint embedding space for the appearance and structure of the scene by enforcing a contrastive loss constraint between different modalities. We apply our framework to a simple Variational Auto-Encoder model on the RADIATE dataset \cite{sheeny2021radiate} and qualitatively demonstrate that we can generate new renders of night-time photos using day-time appearance codes without additional optimization iterations. Additionally, we compare our model to a baseline VAE that uses the standard per-image appearance code technique and show that our approach achieves generations of similar quality without learning appearance codes for any unseen images on inference.
Allpass impulse response modelling
Nov 24, 2023This document defines a method for FIR system modelling which is very trivial as it only depends on phase introduction and removal (allpass filters). As magnitude is not altered, the processing is numerically stable. It is limited to phase alteration which maintains the time domain magnitude to force a system within its linear limits.
Real-time 6-DoF Pose Estimation by an Event-based Camera using Active LED Markers
Oct 25, 2023

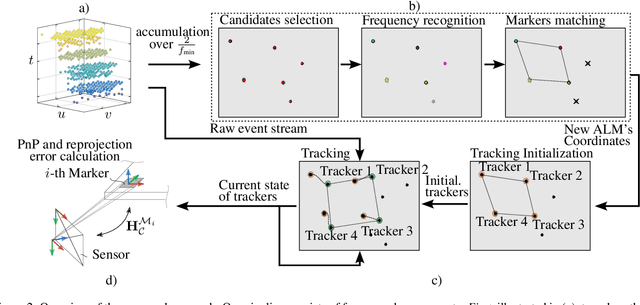

Real-time applications for autonomous operations depend largely on fast and robust vision-based localization systems. Since image processing tasks require processing large amounts of data, the computational resources often limit the performance of other processes. To overcome this limitation, traditional marker-based localization systems are widely used since they are easy to integrate and achieve reliable accuracy. However, classical marker-based localization systems significantly depend on standard cameras with low frame rates, which often lack accuracy due to motion blur. In contrast, event-based cameras provide high temporal resolution and a high dynamic range, which can be utilized for fast localization tasks, even under challenging visual conditions. This paper proposes a simple but effective event-based pose estimation system using active LED markers (ALM) for fast and accurate pose estimation. The proposed algorithm is able to operate in real time with a latency below \SI{0.5}{\milli\second} while maintaining output rates of \SI{3}{\kilo \hertz}. Experimental results in static and dynamic scenarios are presented to demonstrate the performance of the proposed approach in terms of computational speed and absolute accuracy, using the OptiTrack system as the basis for measurement.
LasTGL: An Industrial Framework for Large-Scale Temporal Graph Learning
Nov 30, 2023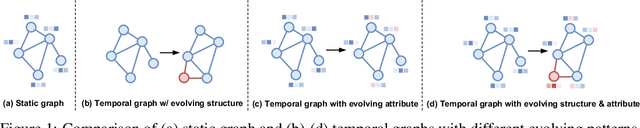


Over the past few years, graph neural networks (GNNs) have become powerful and practical tools for learning on (static) graph-structure data. However, many real-world applications, such as social networks and e-commerce, involve temporal graphs where nodes and edges are dynamically evolving. Temporal graph neural networks (TGNNs) have progressively emerged as an extension of GNNs to address time-evolving graphs and have gradually become a trending research topic in both academics and industry. Advancing research and application in such an emerging field necessitates the development of new tools to compose TGNN models and unify their different schemes for dealing with temporal graphs. In this work, we introduce LasTGL, an industrial framework that integrates unified and extensible implementations of common temporal graph learning algorithms for various advanced tasks. The purpose of LasTGL is to provide the essential building blocks for solving temporal graph learning tasks, focusing on the guiding principles of user-friendliness and quick prototyping on which PyTorch is based. In particular, LasTGL provides comprehensive temporal graph datasets, TGNN models and utilities along with well-documented tutorials, making it suitable for both absolute beginners and expert deep learning practitioners alike.
MotionEditor: Editing Video Motion via Content-Aware Diffusion
Nov 30, 2023Existing diffusion-based video editing models have made gorgeous advances for editing attributes of a source video over time but struggle to manipulate the motion information while preserving the original protagonist's appearance and background. To address this, we propose MotionEditor, a diffusion model for video motion editing. MotionEditor incorporates a novel content-aware motion adapter into ControlNet to capture temporal motion correspondence. While ControlNet enables direct generation based on skeleton poses, it encounters challenges when modifying the source motion in the inverted noise due to contradictory signals between the noise (source) and the condition (reference). Our adapter complements ControlNet by involving source content to transfer adapted control signals seamlessly. Further, we build up a two-branch architecture (a reconstruction branch and an editing branch) with a high-fidelity attention injection mechanism facilitating branch interaction. This mechanism enables the editing branch to query the key and value from the reconstruction branch in a decoupled manner, making the editing branch retain the original background and protagonist appearance. We also propose a skeleton alignment algorithm to address the discrepancies in pose size and position. Experiments demonstrate the promising motion editing ability of MotionEditor, both qualitatively and quantitatively.
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
Spectrum Sharing in Low-Earth Orbit Satellite Systems under an Interference Protection Constraint
Nov 30, 2023This work investigates the in-band coexistence between two dense low-earth orbit (LEO) satellite communication systems by analyzing two preeminent large-scale constellations, namely Starlink and Kuiper, both which have been granted non-exclusive rights to operate at 20 GHz. Through extensive simulation of Starlink and Kuiper based on their public filings, we examine downlink performance of both systems when Kuiper is obliged to protect Starlink by not inflicting prohibitive interference onto its ground users. We show that Kuiper is capable of reliably satisfying a strict protection constraint at virtually all times by strategically selecting which overhead satellites are used to serve its ground users. In fact, while protecting Starlink users in this way, our results show that Kuiper can remarkably also deliver near-maximal downlink SINR to its own ground users, revealing a feasible route to fruitful coexistence of both systems. For instance, as the constellations orbit the globe, we show that Kuiper is always capable of keeping its inflicted interference at least 12 dB below noise and in doing so sacrifices only about 1 dB in SINR over 80% of the time.