 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploring the relationship between response time sequence in scale answering process and severity of insomnia: a machine learning approach
Oct 13, 2023
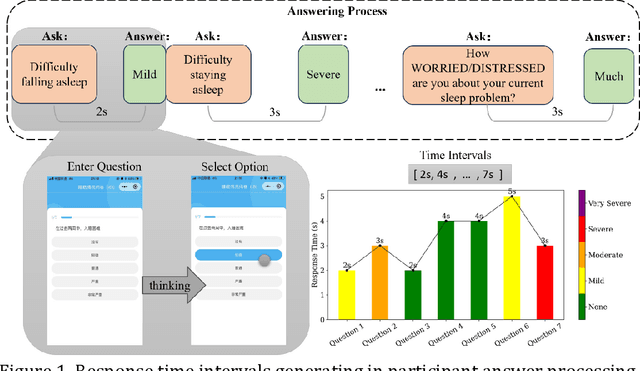
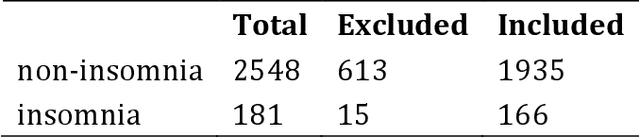
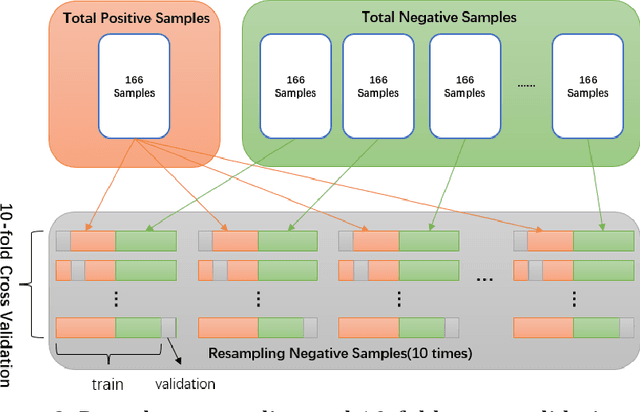
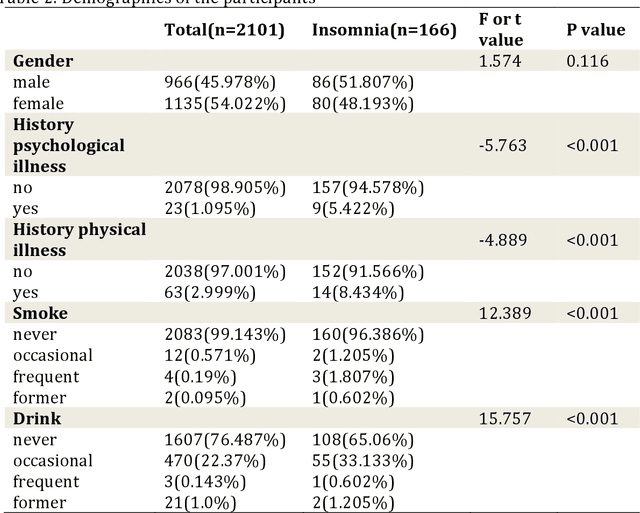
Objectives: The study aims to investigate the relationship between insomnia and response time. Additionally, it aims to develop a machine learning model to predict the presence of insomnia in participants using response time data. Methods: A mobile application was designed to administer scale tests and collect response time data from 2729 participants. The relationship between symptom severity and response time was explored, and a machine learning model was developed to predict the presence of insomnia. Results: The result revealed a statistically significant difference (p<.001) in the total response time between participants with or without insomnia symptoms. A correlation was observed between the severity of specific insomnia aspects and response times at the individual questions level. The machine learning model demonstrated a high predictive accuracy of 0.743 in predicting insomnia symptoms based on response time data. Conclusions: These findings highlight the potential utility of response time data to evaluate cognitive and psychological measures, demonstrating the effectiveness of using response time as a diagnostic tool in the assessment of insomnia.
Analysis of Weather and Time Features in Machine Learning-aided ERCOT Load Forecasting
Oct 13, 2023Accurate load forecasting is critical for efficient and reliable operations of the electric power system. A large part of electricity consumption is affected by weather conditions, making weather information an important determinant of electricity usage. Personal appliances and industry equipment also contribute significantly to electricity demand with temporal patterns, making time a useful factor to consider in load forecasting. This work develops several machine learning (ML) models that take various time and weather information as part of the input features to predict the short-term system-wide total load. Ablation studies were also performed to investigate and compare the impacts of different weather factors on the prediction accuracy. Actual load and historical weather data for the same region were processed and then used to train the ML models. It is interesting to observe that using all available features, each of which may be correlated to the load, is unlikely to achieve the best forecasting performance; features with redundancy may even decrease the inference capabilities of ML models. This indicates the importance of feature selection for ML models. Overall, case studies demonstrated the effectiveness of ML models trained with different weather and time input features for ERCOT load forecasting.
Real-time Batched Distance Computation for Time-Optimal Safe Path Tracking
Sep 21, 2023In human-robot collaboration, there has been a trade-off relationship between the speed of collaborative robots and the safety of human workers. In our previous paper, we introduced a time-optimal path tracking algorithm designed to maximize speed while ensuring safety for human workers. This algorithm runs in real-time and provides the safe and fastest control input for every cycle with respect to ISO standards. However, true optimality has not been achieved due to inaccurate distance computation resulting from conservative model simplification. To attain true optimality, we require a method that can compute distances 1. at many robot configurations to examine along a trajectory 2. in real-time for online robot control 3. as precisely as possible for optimal control. In this paper, we propose a batched, fast and precise distance checking method based on precomputed link-local SDFs. Our method can check distances for 500 waypoints along a trajectory within less than 1 millisecond using a GPU at runtime, making it suited for time-critical robotic control. Additionally, a neural approximation has been proposed to accelerate preprocessing by a factor of 2. Finally, we experimentally demonstrate that our method can navigate a 6-DoF robot earlier than a geometric-primitives-based distance checker in a dynamic and collaborative environment.
Semi-Supervised End-To-End Contrastive Learning For Time Series Classification
Oct 13, 2023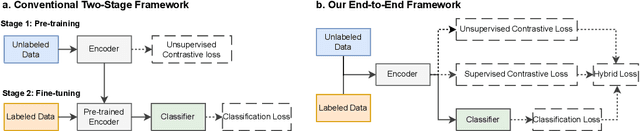
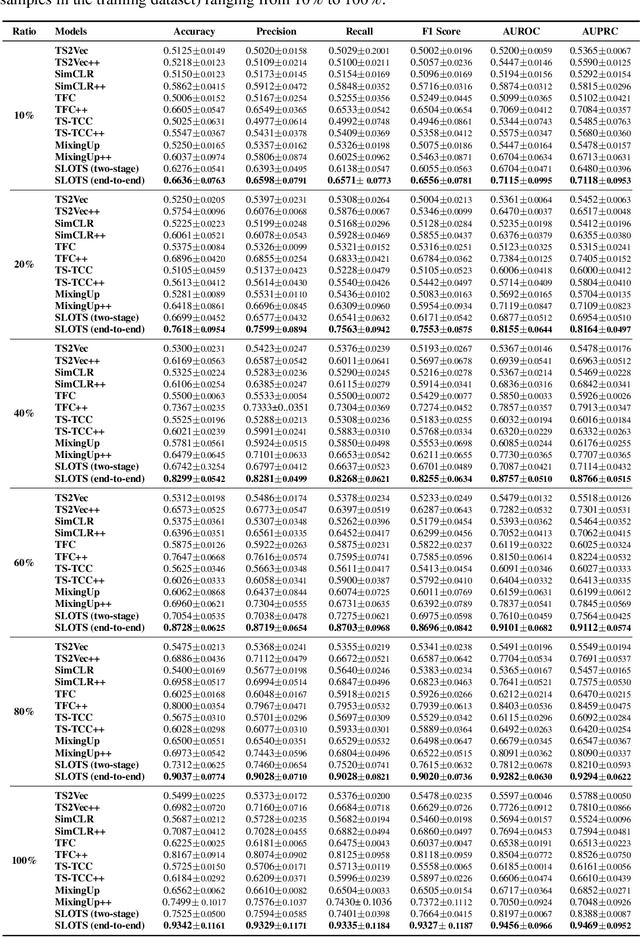
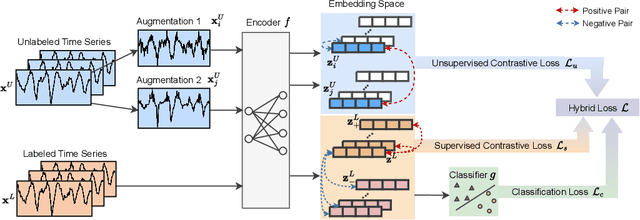
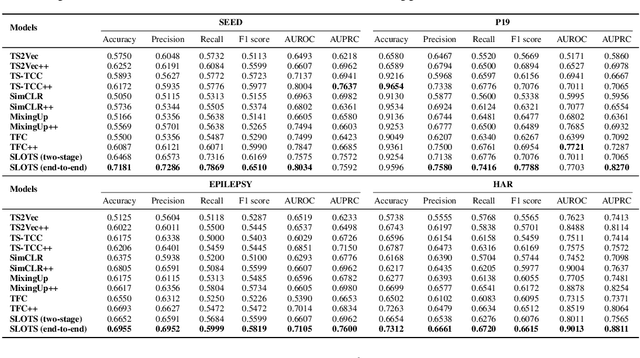
Time series classification is a critical task in various domains, such as finance, healthcare, and sensor data analysis. Unsupervised contrastive learning has garnered significant interest in learning effective representations from time series data with limited labels. The prevalent approach in existing contrastive learning methods consists of two separate stages: pre-training the encoder on unlabeled datasets and fine-tuning the well-trained model on a small-scale labeled dataset. However, such two-stage approaches suffer from several shortcomings, such as the inability of unsupervised pre-training contrastive loss to directly affect downstream fine-tuning classifiers, and the lack of exploiting the classification loss which is guided by valuable ground truth. In this paper, we propose an end-to-end model called SLOTS (Semi-supervised Learning fOr Time clasSification). SLOTS receives semi-labeled datasets, comprising a large number of unlabeled samples and a small proportion of labeled samples, and maps them to an embedding space through an encoder. We calculate not only the unsupervised contrastive loss but also measure the supervised contrastive loss on the samples with ground truth. The learned embeddings are fed into a classifier, and the classification loss is calculated using the available true labels. The unsupervised, supervised contrastive losses and classification loss are jointly used to optimize the encoder and classifier. We evaluate SLOTS by comparing it with ten state-of-the-art methods across five datasets. The results demonstrate that SLOTS is a simple yet effective framework. When compared to the two-stage framework, our end-to-end SLOTS utilizes the same input data, consumes a similar computational cost, but delivers significantly improved performance. We release code and datasets at https://anonymous.4open.science/r/SLOTS-242E.
Missing Value Imputation for Multi-attribute Sensor Data Streams via Message Propagation (Extended Version)
Nov 14, 2023Sensor data streams occur widely in various real-time applications in the context of the Internet of Things (IoT). However, sensor data streams feature missing values due to factors such as sensor failures, communication errors, or depleted batteries. Missing values can compromise the quality of real-time analytics tasks and downstream applications. Existing imputation methods either make strong assumptions about streams or have low efficiency. In this study, we aim to accurately and efficiently impute missing values in data streams that satisfy only general characteristics in order to benefit real-time applications more widely. First, we propose a message propagation imputation network (MPIN) that is able to recover the missing values of data instances in a time window. We give a theoretical analysis of why MPIN is effective. Second, we present a continuous imputation framework that consists of data update and model update mechanisms to enable MPIN to perform continuous imputation both effectively and efficiently. Extensive experiments on multiple real datasets show that MPIN can outperform the existing data imputers by wide margins and that the continuous imputation framework is efficient and accurate.
Point Projection Mapping System for Tracking, Registering, Labeling and Validating Optical Tissue Measurements
Nov 22, 2023Validation of newly developed optical tissue sensing techniques for tumor detection during cancer surgery requires an accurate correlation with histological results. Additionally, such accurate correlation facilitates precise data labeling for developing high-performance machine-learning tissue classification models. In this paper, a newly developed Point Projection Mapping system will be introduced, which allows non-destructive tracking of the measurement locations on tissue specimens. Additionally, a framework for accurate registration, validation, and labeling with histopathology results is proposed and validated on a case study. The proposed framework provides a more robust and accurate method for tracking and validation of optical tissue sensing techniques, which saves time and resources compared to conventional techniques available.
BERT-PIN: A BERT-based Framework for Recovering Missing Data Segments in Time-series Load Profiles
Oct 26, 2023Inspired by the success of the Transformer model in natural language processing and computer vision, this paper introduces BERT-PIN, a Bidirectional Encoder Representations from Transformers (BERT) powered Profile Inpainting Network. BERT-PIN recovers multiple missing data segments (MDSs) using load and temperature time-series profiles as inputs. To adopt a standard Transformer model structure for profile inpainting, we segment the load and temperature profiles into line segments, treating each segment as a word and the entire profile as a sentence. We incorporate a top candidates selection process in BERT-PIN, enabling it to produce a sequence of probability distributions, based on which users can generate multiple plausible imputed data sets, each reflecting different confidence levels. We develop and evaluate BERT-PIN using real-world dataset for two applications: multiple MDSs recovery and demand response baseline estimation. Simulation results show that BERT-PIN outperforms the existing methods in accuracy while is capable of restoring multiple MDSs within a longer window. BERT-PIN, served as a pre-trained model, can be fine-tuned for conducting many downstream tasks, such as classification and super resolution.
Gaussian processes based data augmentation and expected signature for time series classification
Oct 16, 2023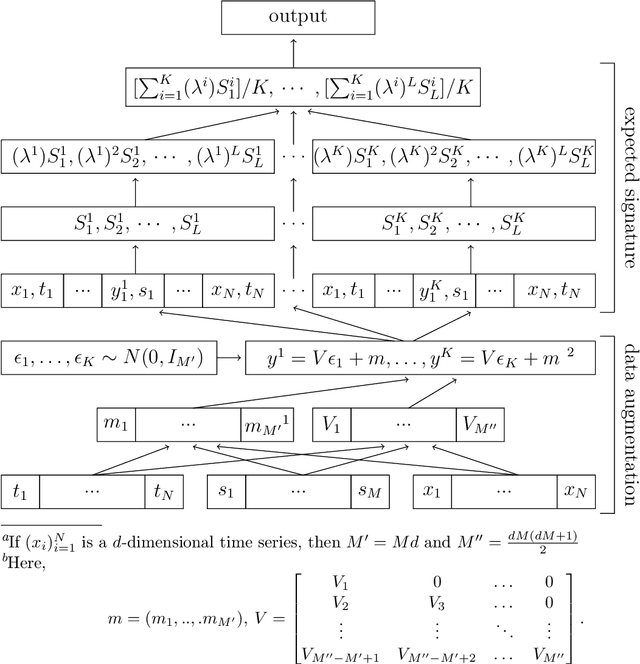
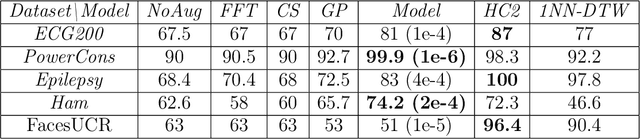
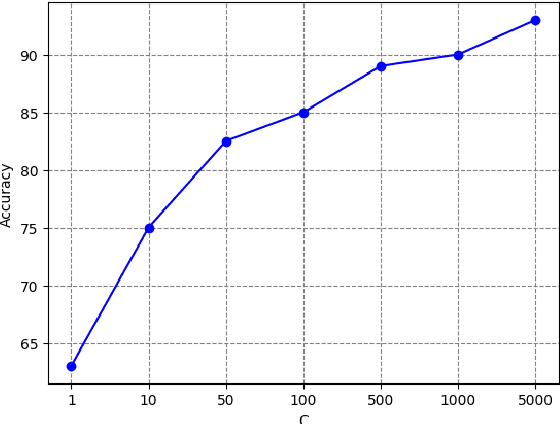
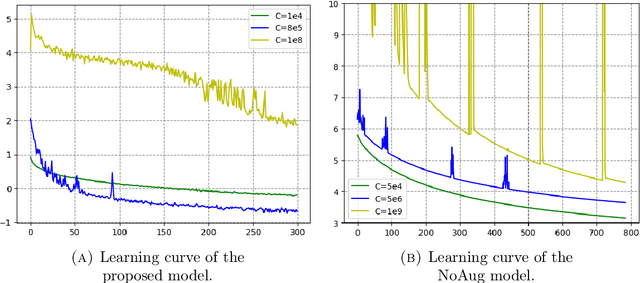
The signature is a fundamental object that describes paths (that is, continuous functions from an interval to a Euclidean space). Likewise, the expected signature provides a statistical description of the law of stochastic processes. We propose a feature extraction model for time series built upon the expected signature. This is computed through a Gaussian processes based data augmentation. One of the main features is that an optimal feature extraction is learnt through the supervised task that uses the model.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Nov 27, 2023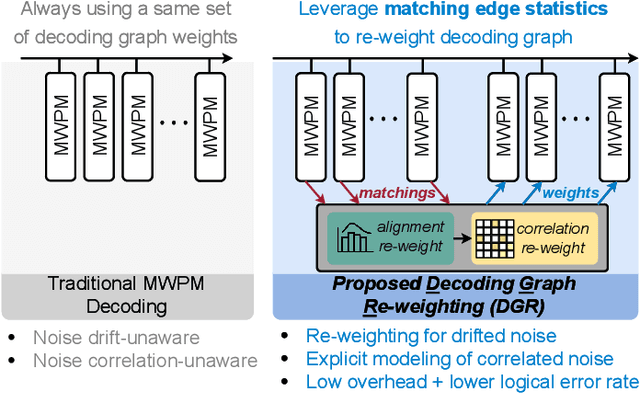
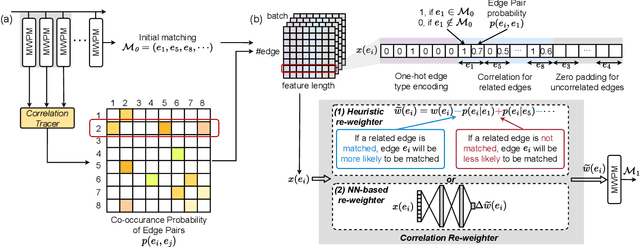
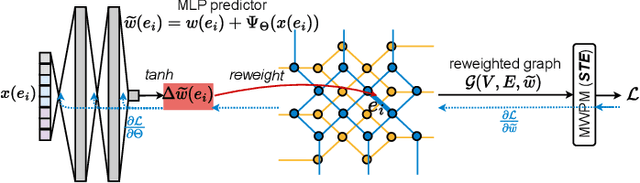
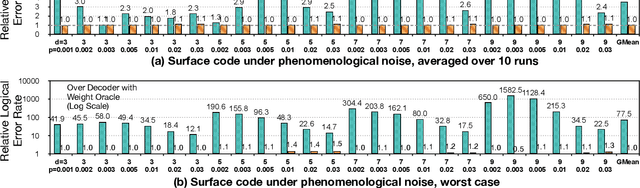
Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.