 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization
Nov 28, 2023
Large language models (LLMs) have demonstrated impressive abilities in various domains while the inference cost is expensive. The state-of-the-art methods use 2-bit quantization for mainstream LLMs. However, challenges still exist: (1) Nonnegligible accuracy loss for 2-bit quantization. Weights are quantized by groups, while the ranges of weights are large in some groups, resulting in large quantization errors and nonnegligible accuracy loss (e.g. >3% for Llama2-7b with 2-bit quantization in GPTQ and Greenbit). (2) Limited accuracy improvement by adding 4-bit weights. Increasing 10% extra average bit more 4-bit weights only leads to <0.5% accuracy improvement on a quantized Llama2-7b. (3) Time-consuming dequantization operations on GPUs. The dequantization operations lead to >50% execution time, hindering the potential of reducing LLM inference cost. To tackle these challenges, we propose the following techniques: (1) We only quantize a small fraction of groups with the larger range using 4-bit with memory alignment consideration on GPUs. (2) We point out that the distribution of the sparse outliers with larger weights is different in 2-bit and 4-bit groups, and only a small fraction of outliers require 16-bit quantization. Such design leads to >0.5% accuracy improvement with <3% average increased bit for Llama2-7b. (3) We design the asynchronous dequantization on GPUs, leading to up to 3.92X speedup. We conduct extensive experiments on different model families and model sizes. We achieve 2.85-bit for each weight and the end-to-end speedup for Llama2-7b is 1.74X over the original model, and we reduce both runtime cost and hardware cost by up to 2.70X and 2.81X with less GPU requirements.
InfoPattern: Unveiling Information Propagation Patterns in Social Media
Nov 27, 2023

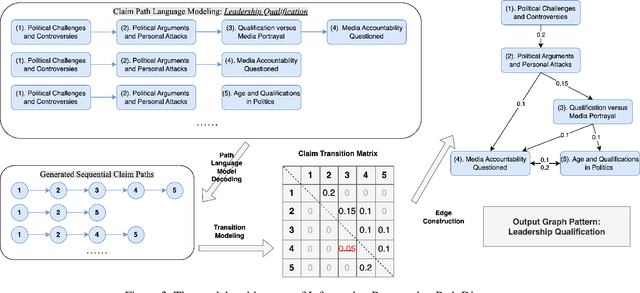
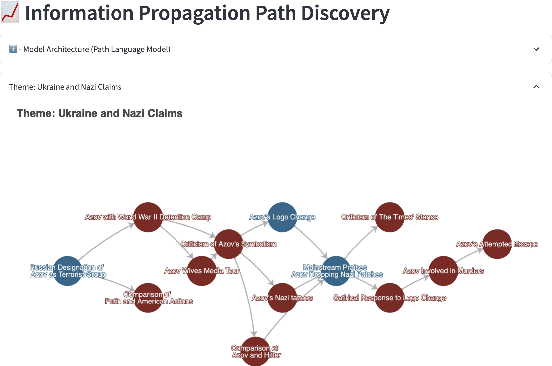
Social media play a significant role in shaping public opinion and influencing ideological communities through information propagation. Our demo InfoPattern centers on the interplay between language and human ideology. The demo (Code: https://github.com/blender-nlp/InfoPattern ) is capable of: (1) red teaming to simulate adversary responses from opposite ideology communities; (2) stance detection to identify the underlying political sentiments in each message; (3) information propagation graph discovery to reveal the evolution of claims across various communities over time. (Live Demo: https://incas.csl.illinois.edu/blender/About )
Scale-Adaptive Feature Aggregation for Efficient Space-Time Video Super-Resolution
Oct 26, 2023The Space-Time Video Super-Resolution (STVSR) task aims to enhance the visual quality of videos, by simultaneously performing video frame interpolation (VFI) and video super-resolution (VSR). However, facing the challenge of the additional temporal dimension and scale inconsistency, most existing STVSR methods are complex and inflexible in dynamically modeling different motion amplitudes. In this work, we find that choosing an appropriate processing scale achieves remarkable benefits in flow-based feature propagation. We propose a novel Scale-Adaptive Feature Aggregation (SAFA) network that adaptively selects sub-networks with different processing scales for individual samples. Experiments on four public STVSR benchmarks demonstrate that SAFA achieves state-of-the-art performance. Our SAFA network outperforms recent state-of-the-art methods such as TMNet and VideoINR by an average improvement of over 0.5dB on PSNR, while requiring less than half the number of parameters and only 1/3 computational costs.
PyNeRF: Pyramidal Neural Radiance Fields
Nov 30, 2023Neural Radiance Fields (NeRFs) can be dramatically accelerated by spatial grid representations. However, they do not explicitly reason about scale and so introduce aliasing artifacts when reconstructing scenes captured at different camera distances. Mip-NeRF and its extensions propose scale-aware renderers that project volumetric frustums rather than point samples but such approaches rely on positional encodings that are not readily compatible with grid methods. We propose a simple modification to grid-based models by training model heads at different spatial grid resolutions. At render time, we simply use coarser grids to render samples that cover larger volumes. Our method can be easily applied to existing accelerated NeRF methods and significantly improves rendering quality (reducing error rates by 20-90% across synthetic and unbounded real-world scenes) while incurring minimal performance overhead (as each model head is quick to evaluate). Compared to Mip-NeRF, we reduce error rates by 20% while training over 60x faster.
Barwise Music Structure Analysis with the Correlation Block-Matching Segmentation Algorithm
Nov 30, 2023Music Structure Analysis (MSA) is a Music Information Retrieval task consisting of representing a song in a simplified, organized manner by breaking it down into sections typically corresponding to ``chorus'', ``verse'', ``solo'', etc. In this work, we extend an MSA algorithm called the Correlation Block-Matching (CBM) algorithm introduced by (Marmoret et al., 2020, 2022b). The CBM algorithm is a dynamic programming algorithm that segments self-similarity matrices, which are a standard description used in MSA and in numerous other applications. In this work, self-similarity matrices are computed from the feature representation of an audio signal and time is sampled at the bar-scale. This study examines three different standard similarity functions for the computation of self-similarity matrices. Results show that, in optimal conditions, the proposed algorithm achieves a level of performance which is competitive with supervised state-of-the-art methods while only requiring knowledge of bar positions. In addition, the algorithm is made open-source and is highly customizable.
* 19 pages, 13 figures, 11 tables, 1 algorithm, published in Transactions of the International Society for Music Information Retrieval
ZeST-NeRF: Using temporal aggregation for Zero-Shot Temporal NeRFs
Nov 30, 2023In the field of media production, video editing techniques play a pivotal role. Recent approaches have had great success at performing novel view image synthesis of static scenes. But adding temporal information adds an extra layer of complexity. Previous models have focused on implicitly representing static and dynamic scenes using NeRF. These models achieve impressive results but are costly at training and inference time. They overfit an MLP to describe the scene implicitly as a function of position. This paper proposes ZeST-NeRF, a new approach that can produce temporal NeRFs for new scenes without retraining. We can accurately reconstruct novel views using multi-view synthesis techniques and scene flow-field estimation, trained only with unrelated scenes. We demonstrate how existing state-of-the-art approaches from a range of fields cannot adequately solve this new task and demonstrate the efficacy of our solution. The resulting network improves quantitatively by 15% and produces significantly better visual results.
Initializing Models with Larger Ones
Nov 30, 2023Weight initialization plays an important role in neural network training. Widely used initialization methods are proposed and evaluated for networks that are trained from scratch. However, the growing number of pretrained models now offers new opportunities for tackling this classical problem of weight initialization. In this work, we introduce weight selection, a method for initializing smaller models by selecting a subset of weights from a pretrained larger model. This enables the transfer of knowledge from pretrained weights to smaller models. Our experiments demonstrate that weight selection can significantly enhance the performance of small models and reduce their training time. Notably, it can also be used together with knowledge distillation. Weight selection offers a new approach to leverage the power of pretrained models in resource-constrained settings, and we hope it can be a useful tool for training small models in the large-model era. Code is available at https://github.com/OscarXZQ/weight-selection.
Learning for Semantic Knowledge Base-Guided Online Feature Transmission in Dynamic Channels
Nov 30, 2023With the proliferation of edge computing, efficient AI inference on edge devices has become essential for intelligent applications such as autonomous vehicles and VR/AR. In this context, we address the problem of efficient remote object recognition by optimizing feature transmission between mobile devices and edge servers. We propose an online optimization framework to address the challenge of dynamic channel conditions and device mobility in an end-to-end communication system. Our approach builds upon existing methods by leveraging a semantic knowledge base to drive multi-level feature transmission, accounting for temporal factors and dynamic elements throughout the transmission process. To solve the online optimization problem, we design a novel soft actor-critic-based deep reinforcement learning system with a carefully designed reward function for real-time decision-making, overcoming the optimization difficulty of the NP-hard problem and achieving the minimization of semantic loss while respecting latency constraints. Numerical results showcase the superiority of our approach compared to traditional greedy methods under various system setups.
CosAvatar: Consistent and Animatable Portrait Video Tuning with Text Prompt
Nov 30, 2023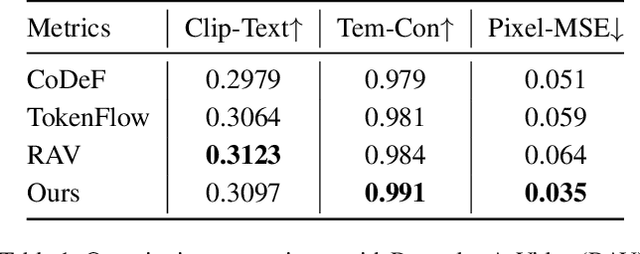
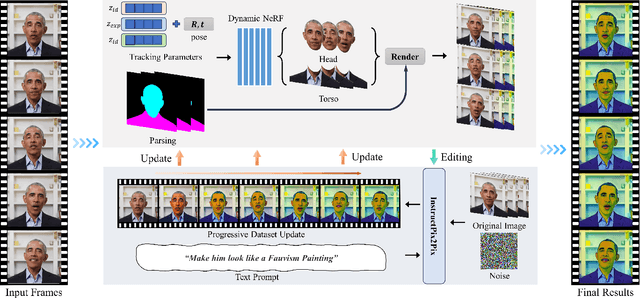
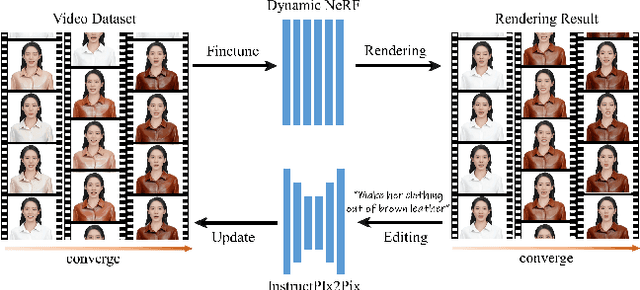

Recently, text-guided digital portrait editing has attracted more and more attentions. However, existing methods still struggle to maintain consistency across time, expression, and view or require specific data prerequisites. To solve these challenging problems, we propose CosAvatar, a high-quality and user-friendly framework for portrait tuning. With only monocular video and text instructions as input, we can produce animatable portraits with both temporal and 3D consistency. Different from methods that directly edit in the 2D domain, we employ a dynamic NeRF-based 3D portrait representation to model both the head and torso. We alternate between editing the video frames' dataset and updating the underlying 3D portrait until the edited frames reach 3D consistency. Additionally, we integrate the semantic portrait priors to enhance the edited results, allowing precise modifications in specified semantic areas. Extensive results demonstrate that our proposed method can not only accurately edit portrait styles or local attributes based on text instructions but also support expressive animation driven by a source video.
S-T CRF: Spatial-Temporal Conditional Random Field for Human Trajectory Prediction
Nov 30, 2023Trajectory prediction is of significant importance in computer vision. Accurate pedestrian trajectory prediction benefits autonomous vehicles and robots in planning their motion. Pedestrians' trajectories are greatly influenced by their intentions. Prior studies having introduced various deep learning methods only pay attention to the spatial and temporal information of trajectory, overlooking the explicit intention information. In this study, we introduce a novel model, termed the \textbf{S-T CRF}: \textbf{S}patial-\textbf{T}emporal \textbf{C}onditional \textbf{R}andom \textbf{F}ield, which judiciously incorporates intention information besides spatial and temporal information of trajectory. This model uses a Conditional Random Field (CRF) to generate a representation of future intentions, greatly improving the prediction of subsequent trajectories when combined with spatial-temporal representation. Furthermore, the study innovatively devises a space CRF loss and a time CRF loss, meticulously designed to enhance interaction constraints and temporal dynamics, respectively. Extensive experimental evaluations on dataset ETH/UCY and SDD demonstrate that the proposed method surpasses existing baseline approaches.