 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Iterative Active-Inactive Obstacle Classification for Time-Optimal Collision Avoidance
Mar 20, 2024
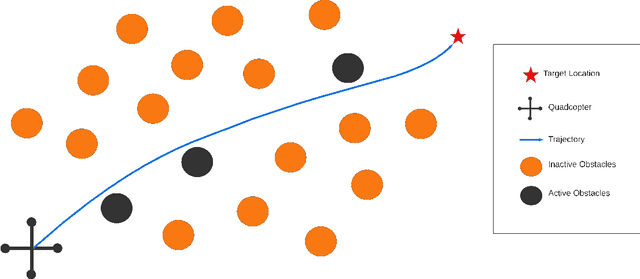
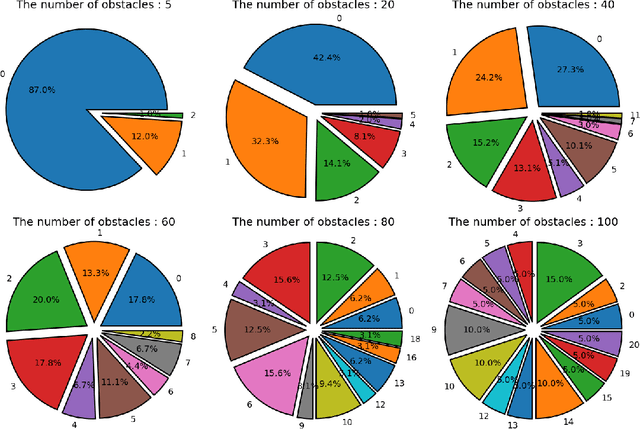
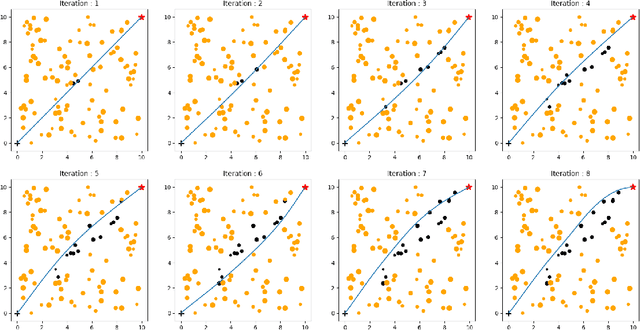
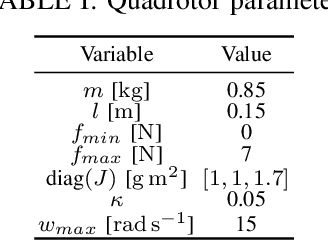
Time-optimal obstacle avoidance is a prevalent problem encountered in various fields, including robotics and autonomous vehicles, where the task involves determining a path for a moving vehicle to reach its goal while navigating around obstacles within its environment. This problem becomes increasingly challenging as the number of obstacles in the environment rises. We propose an iterative active-inactive obstacle approach, which involves identifying a subset of the obstacles as "active", that considers solely the effect of the "active" obstacles on the path of the moving vehicle. The remaining obstacles are considered "inactive" and are not considered in the path planning process. The obstacles are classified as 'active' on the basis of previous findings derived from prior iterations. This approach allows for a more efficient calculation of the optimal path by reducing the number of obstacles that need to be considered. The effectiveness of the proposed method is demonstrated with two different dynamic models using the various number of obstacles. The results show that the proposed method is able to find the optimal path in a timely manner, while also being able to handle a large number of obstacles in the environment and the constraints on the motion of the object.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024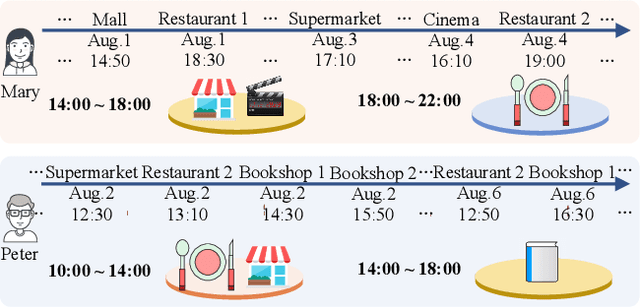
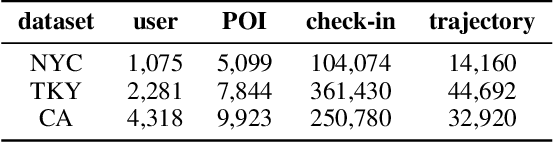
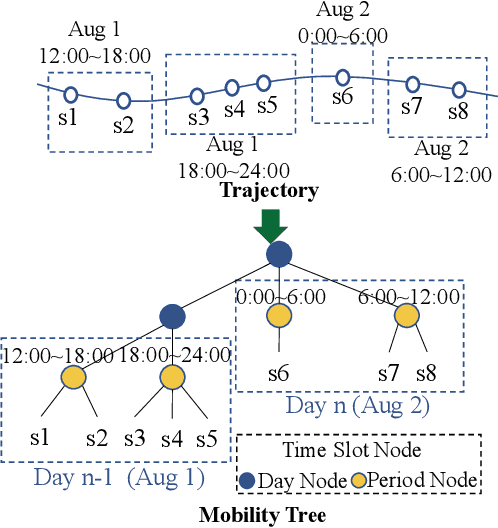
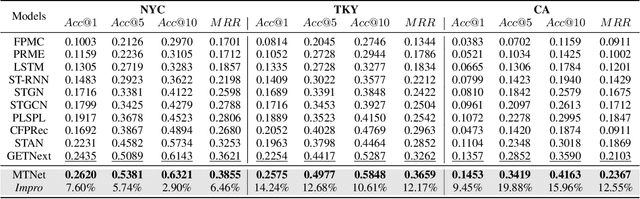
Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
Deep Learning-Based CSI Feedback for RIS-Aided Massive MIMO Systems with Time Correlation
Mar 19, 2024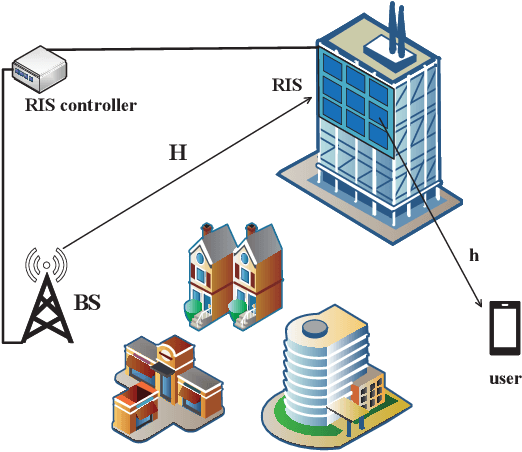
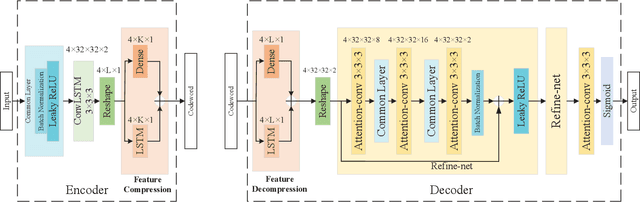
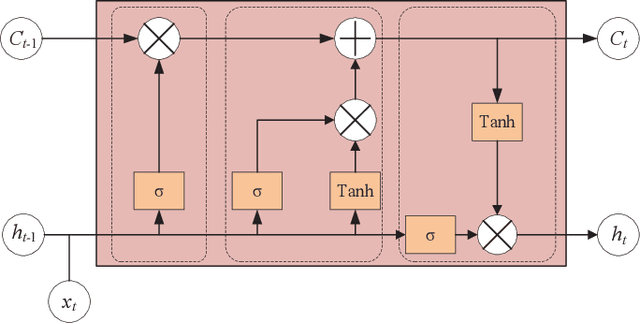
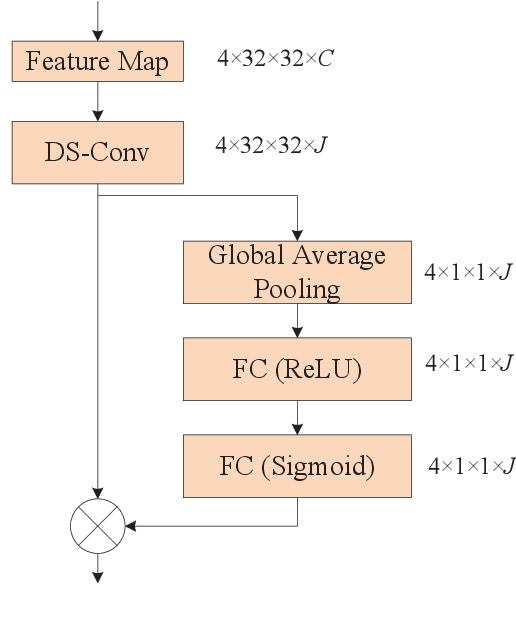
In this paper, we consider an reconfigurable intelligent surface (RIS)-aided frequency division duplex (FDD) massive multiple-input multiple-output (MIMO) downlink system.In the FDD systems, the downlink channel state information (CSI) should be sent to the base station through the feedback link. However, the overhead of CSI feedback occupies substantial uplink bandwidth resources in RIS-aided communication systems. In this work, we propose a deep learning (DL)-based scheme to reduce the overhead of CSI feedback by compressing the cascaded CSI. In the practical RIS-aided communication systems, the cascaded channel at the adjacent slots inevitably has time correlation. We use long short-term memory to learn time correlation, which can help the neural network to improve the recovery quality of the compressed CSI. Moreover, the attention mechanism is introduced to further improve the CSI recovery quality. Simulation results demonstrate that our proposed DLbased scheme can significantly outperform other DL-based methods in terms of the CSI recovery quality
Super Non-singular Decompositions of Polynomials and their Application to Robustly Learning Low-degree PTFs
Mar 31, 2024We study the efficient learnability of low-degree polynomial threshold functions (PTFs) in the presence of a constant fraction of adversarial corruptions. Our main algorithmic result is a polynomial-time PAC learning algorithm for this concept class in the strong contamination model under the Gaussian distribution with error guarantee $O_{d, c}(\text{opt}^{1-c})$, for any desired constant $c>0$, where $\text{opt}$ is the fraction of corruptions. In the strong contamination model, an omniscient adversary can arbitrarily corrupt an $\text{opt}$-fraction of the data points and their labels. This model generalizes the malicious noise model and the adversarial label noise model. Prior to our work, known polynomial-time algorithms in this corruption model (or even in the weaker adversarial label noise model) achieved error $\tilde{O}_d(\text{opt}^{1/(d+1)})$, which deteriorates significantly as a function of the degree $d$. Our algorithm employs an iterative approach inspired by localization techniques previously used in the context of learning linear threshold functions. Specifically, we use a robust perceptron algorithm to compute a good partial classifier and then iterate on the unclassified points. In order to achieve this, we need to take a set defined by a number of polynomial inequalities and partition it into several well-behaved subsets. To this end, we develop new polynomial decomposition techniques that may be of independent interest.
GLEMOS: Benchmark for Instantaneous Graph Learning Model Selection
Apr 02, 2024The choice of a graph learning (GL) model (i.e., a GL algorithm and its hyperparameter settings) has a significant impact on the performance of downstream tasks. However, selecting the right GL model becomes increasingly difficult and time consuming as more and more GL models are developed. Accordingly, it is of great significance and practical value to equip users of GL with the ability to perform a near-instantaneous selection of an effective GL model without manual intervention. Despite the recent attempts to tackle this important problem, there has been no comprehensive benchmark environment to evaluate the performance of GL model selection methods. To bridge this gap, we present GLEMOS in this work, a comprehensive benchmark for instantaneous GL model selection that makes the following contributions. (i) GLEMOS provides extensive benchmark data for fundamental GL tasks, i.e., link prediction and node classification, including the performances of 366 models on 457 graphs on these tasks. (ii) GLEMOS designs multiple evaluation settings, and assesses how effectively representative model selection techniques perform in these different settings. (iii) GLEMOS is designed to be easily extended with new models, new graphs, and new performance records. (iv) Based on the experimental results, we discuss the limitations of existing approaches and highlight future research directions. To promote research on this significant problem, we make the benchmark data and code publicly available at https://github.com/facebookresearch/glemos.
Towards Robust 3D Pose Transfer with Adversarial Learning
Apr 02, 20243D pose transfer that aims to transfer the desired pose to a target mesh is one of the most challenging 3D generation tasks. Previous attempts rely on well-defined parametric human models or skeletal joints as driving pose sources. However, to obtain those clean pose sources, cumbersome but necessary pre-processing pipelines are inevitable, hindering implementations of the real-time applications. This work is driven by the intuition that the robustness of the model can be enhanced by introducing adversarial samples into the training, leading to a more invulnerable model to the noisy inputs, which even can be further extended to directly handling the real-world data like raw point clouds/scans without intermediate processing. Furthermore, we propose a novel 3D pose Masked Autoencoder (3D-PoseMAE), a customized MAE that effectively learns 3D extrinsic presentations (i.e., pose). 3D-PoseMAE facilitates learning from the aspect of extrinsic attributes by simultaneously generating adversarial samples that perturb the model and learning the arbitrary raw noisy poses via a multi-scale masking strategy. Both qualitative and quantitative studies show that the transferred meshes given by our network result in much better quality. Besides, we demonstrate the strong generalizability of our method on various poses, different domains, and even raw scans. Experimental results also show meaningful insights that the intermediate adversarial samples generated in the training can successfully attack the existing pose transfer models.
EventSleep: Sleep Activity Recognition with Event Cameras
Apr 02, 2024Event cameras are a promising technology for activity recognition in dark environments due to their unique properties. However, real event camera datasets under low-lighting conditions are still scarce, which also limits the number of approaches to solve these kind of problems, hindering the potential of this technology in many applications. We present EventSleep, a new dataset and methodology to address this gap and study the suitability of event cameras for a very relevant medical application: sleep monitoring for sleep disorders analysis. The dataset contains synchronized event and infrared recordings emulating common movements that happen during the sleep, resulting in a new challenging and unique dataset for activity recognition in dark environments. Our novel pipeline is able to achieve high accuracy under these challenging conditions and incorporates a Bayesian approach (Laplace ensembles) to increase the robustness in the predictions, which is fundamental for medical applications. Our work is the first application of Bayesian neural networks for event cameras, the first use of Laplace ensembles in a realistic problem, and also demonstrates for the first time the potential of event cameras in a new application domain: to enhance current sleep evaluation procedures. Our activity recognition results highlight the potential of event cameras under dark conditions, and its capacity and robustness for sleep activity recognition, and open problems as the adaptation of event data pre-processing techniques to dark environments.
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Apr 02, 2024Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
Real-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024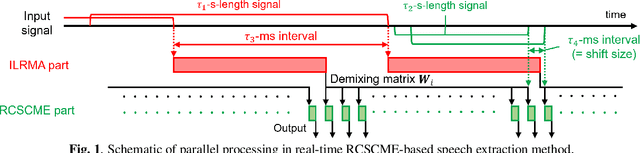
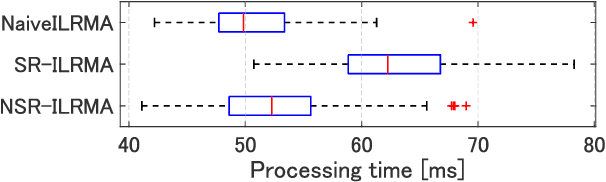
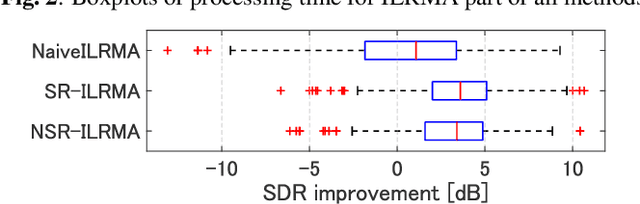
Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
CASPER: Causality-Aware Spatiotemporal Graph Neural Networks for Spatiotemporal Time Series Imputation
Mar 18, 2024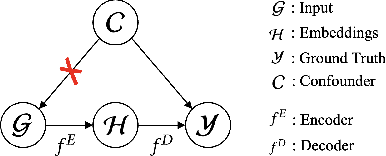
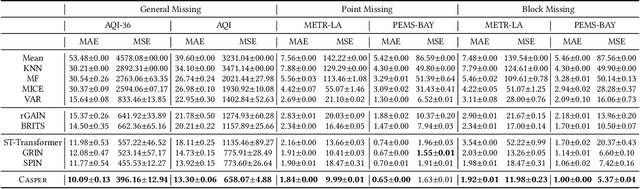
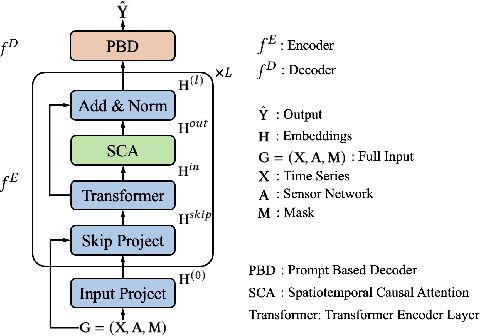
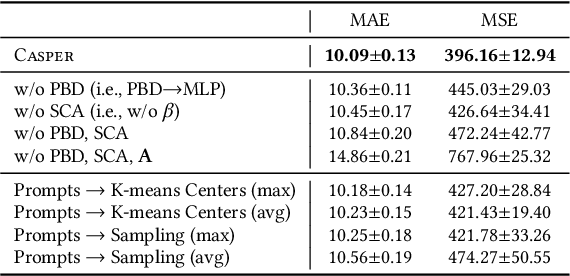
Spatiotemporal time series is the foundation of understanding human activities and their impacts, which is usually collected via monitoring sensors placed at different locations. The collected data usually contains missing values due to various failures, which have significant impact on data analysis. To impute the missing values, a lot of methods have been introduced. When recovering a specific data point, most existing methods tend to take into consideration all the information relevant to that point regardless of whether they have a cause-and-effect relationship. During data collection, it is inevitable that some unknown confounders are included, e.g., background noise in time series and non-causal shortcut edges in the constructed sensor network. These confounders could open backdoor paths between the input and output, in other words, they establish non-causal correlations between the input and output. Over-exploiting these non-causal correlations could result in overfitting and make the model vulnerable to noises. In this paper, we first revisit spatiotemporal time series imputation from a causal perspective, which shows the causal relationships among the input, output, embeddings and confounders. Next, we show how to block the confounders via the frontdoor adjustment. Based on the results of the frontdoor adjustment, we introduce a novel Causality-Aware SPatiotEmpoRal graph neural network (CASPER), which contains a novel Spatiotemporal Causal Attention (SCA) and a Prompt Based Decoder (PBD). PBD could reduce the impact of confounders and SCA could discover the sparse causal relationships among embeddings. Theoretical analysis reveals that SCA discovers causal relationships based on the values of gradients. We evaluate Casper on three real-world datasets, and the experimental results show that Casper outperforms the baselines and effectively discovers causal relationships.