 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross Entropy in Deep Learning of Classifiers Is Unnecessary -- ISBE Error is All You Need
Nov 27, 2023
In deep learning classifiers, the cost function usually takes the form of a combination of SoftMax and CrossEntropy functions. The SoftMax unit transforms the scores predicted by the model network into assessments of the degree (probabilities) of an object's membership to a given class. On the other hand, CrossEntropy measures the divergence of this prediction from the distribution of target scores. This work introduces the ISBE functionality, justifying the thesis about the redundancy of cross entropy computation in deep learning of classifiers. Not only can we omit the calculation of entropy, but also, during back-propagation, there is no need to direct the error to the normalization unit for its backward transformation. Instead, the error is sent directly to the model's network. Using examples of perceptron and convolutional networks as classifiers of images from the MNIST collection, it is observed for ISBE that results are not degraded with SoftMax only, but also with other activation functions such as Sigmoid, Tanh, or their hard variants HardSigmoid and HardTanh. Moreover, up to three percent of time is saved within the total time of forward and backward stages. The article is addressed mainly to programmers and students interested in deep model learning. For example, it illustrates in code snippets possible ways to implement ISBE units, but also formally proves that the softmax trick only applies to the class of softmax functions with relocations.
Leveraging Multiple Teachers for Test-Time Adaptation of Language-Guided Classifiers
Nov 13, 2023Recent approaches have explored language-guided classifiers capable of classifying examples from novel tasks when provided with task-specific natural language explanations, instructions or prompts (Sanh et al., 2022; R. Menon et al., 2022). While these classifiers can generalize in zero-shot settings, their task performance often varies substantially between different language explanations in unpredictable ways (Lu et al., 2022; Gonen et al., 2022). Also, current approaches fail to leverage unlabeled examples that may be available in many scenarios. Here, we introduce TALC, a framework that uses data programming to adapt a language-guided classifier for a new task during inference when provided with explanations from multiple teachers and unlabeled test examples. Our results show that TALC consistently outperforms a competitive baseline from prior work by an impressive 9.3% (relative improvement). Further, we demonstrate the robustness of TALC to variations in the quality and quantity of provided explanations, highlighting its potential in scenarios where learning from multiple teachers or a crowd is involved. Our code is available at: https://github.com/WeiKangda/TALC.git.
The Sliding Regret in Stochastic Bandits: Discriminating Index and Randomized Policies
Nov 30, 2023This paper studies the one-shot behavior of no-regret algorithms for stochastic bandits. Although many algorithms are known to be asymptotically optimal with respect to the expected regret, over a single run, their pseudo-regret seems to follow one of two tendencies: it is either smooth or bumpy. To measure this tendency, we introduce a new notion: the sliding regret, that measures the worst pseudo-regret over a time-window of fixed length sliding to infinity. We show that randomized methods (e.g. Thompson Sampling and MED) have optimal sliding regret, while index policies, although possibly asymptotically optimal for the expected regret, have the worst possible sliding regret under regularity conditions on their index (e.g. UCB, UCB-V, KL-UCB, MOSS, IMED etc.). We further analyze the average bumpiness of the pseudo-regret of index policies via the regret of exploration, that we show to be suboptimal as well.
VIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
Nov 30, 2023Diffusion models have achieved significant success in image and video generation. This motivates a growing interest in video editing tasks, where videos are edited according to provided text descriptions. However, most existing approaches only focus on video editing for short clips and rely on time-consuming tuning or inference. We are the first to propose Video Instruction Diffusion (VIDiff), a unified foundation model designed for a wide range of video tasks. These tasks encompass both understanding tasks (such as language-guided video object segmentation) and generative tasks (video editing and enhancement). Our model can edit and translate the desired results within seconds based on user instructions. Moreover, we design an iterative auto-regressive method to ensure consistency in editing and enhancing long videos. We provide convincing generative results for diverse input videos and written instructions, both qualitatively and quantitatively. More examples can be found at our website https://ChenHsing.github.io/VIDiff.
DGMem: Learning Visual Navigation Policy without Any Labels by Dynamic Graph Memory
Nov 30, 2023In recent years, learning-based approaches have demonstrated significant promise in addressing intricate navigation tasks. Traditional methods for training deep neural network navigation policies rely on meticulously designed reward functions or extensive teleoperation datasets as navigation demonstrations. However, the former is often confined to simulated environments, and the latter demands substantial human labor, making it a time-consuming process. Our vision is for robots to autonomously learn navigation skills and adapt their behaviors to environmental changes without any human intervention. In this work, we discuss the self-supervised navigation problem and present Dynamic Graph Memory (DGMem), which facilitates training only with on-board observations. With the help of DGMem, agents can actively explore their surroundings, autonomously acquiring a comprehensive navigation policy in a data-efficient manner without external feedback. Our method is evaluated in photorealistic 3D indoor scenes, and empirical studies demonstrate the effectiveness of DGMem.
PAUNet: Precipitation Attention-based U-Net for rain prediction from satellite radiance data
Nov 30, 2023This paper introduces Precipitation Attention-based U-Net (PAUNet), a deep learning architecture for predicting precipitation from satellite radiance data, addressing the challenges of the Weather4cast 2023 competition. PAUNet is a variant of U-Net and Res-Net, designed to effectively capture the large-scale contextual information of multi-band satellite images in visible, water vapor, and infrared bands through encoder convolutional layers with center cropping and attention mechanisms. We built upon the Focal Precipitation Loss including an exponential component (e-FPL), which further enhanced the importance across different precipitation categories, particularly medium and heavy rain. Trained on a substantial dataset from various European regions, PAUNet demonstrates notable accuracy with a higher Critical Success Index (CSI) score than the baseline model in predicting rainfall over multiple time slots. PAUNet's architecture and training methodology showcase improvements in precipitation forecasting, crucial for sectors like emergency services and retail and supply chain management.
Cross-correlation image analysis for real-time particle tracking
Oct 12, 2023Accurately measuring translations between images is essential in many fields, including biology, medicine, geography, and physics. Existing methods, including the popular FFT-based cross-correlation, are not suitable for real-time analysis, which is especially vital in feedback control systems. To fill this gap, we introduce a new algorithm which approaches shot-noise limited displacement detection and a GPU-based implementation for real-time image analysis.
A Hybrid Frame Structure Design of OTFS for Multi-tasks Communications
Nov 21, 2023Orthogonal time frequency space (OTFS) is a promising waveform in high mobility scenarios for it fully exploits the time-frequency diversity using a discrete Fourier transform (DFT) based two dimensional spreading. However, it trades off the processing latency for performance and may not fulfill the stringent latency requirements in some services. This fact motivates us to design a hybrid frame structure where the OTFS and Orthogonal Frequency Division Multiplexing (OFDM) are orthogonally multiplexed in the time domain, which can adapt to both diversity-preferred and latency-preferred tasks. As we identify that this orthogonality is disrupted after channel coupling, we provide practical algorithms to mitigate the inter symbol interference between (ISI) the OTFS and OFDM, and the numerical results ensure the effectiveness of the hybrid frame structure.
Simulation-Based Inference of Surface Accumulation and Basal Melt Rates of an Antarctic Ice Shelf from Isochronal Layers
Dec 03, 2023The ice shelves buttressing the Antarctic ice sheet determine the rate of ice-discharge into the surrounding oceans. The geometry of ice shelves, and hence their buttressing strength, is determined by ice flow as well as by the local surface accumulation and basal melt rates, governed by atmospheric and oceanic conditions. Contemporary methods resolve one of these rates, but typically not both. Moreover, there is little information of how they changed in time. We present a new method to simultaneously infer the surface accumulation and basal melt rates averaged over decadal and centennial timescales. We infer the spatial dependence of these rates along flow line transects using internal stratigraphy observed by radars, using a kinematic forward model of internal stratigraphy. We solve the inverse problem using simulation-based inference (SBI). SBI performs Bayesian inference by training neural networks on simulations of the forward model to approximate the posterior distribution, allowing us to also quantify uncertainties over the inferred parameters. We demonstrate the validity of our method on a synthetic example, and apply it to Ekstr\"om Ice Shelf, Antarctica, for which newly acquired radar measurements are available. We obtain posterior distributions of surface accumulation and basal melt averaging over 42, 84, 146, and 188 years before 2022. Our results suggest stable atmospheric and oceanographic conditions over this period in this catchment of Antarctica. Use of observed internal stratigraphy can separate the effects of surface accumulation and basal melt, allowing them to be interpreted in a historical context of the last centuries and beyond.
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023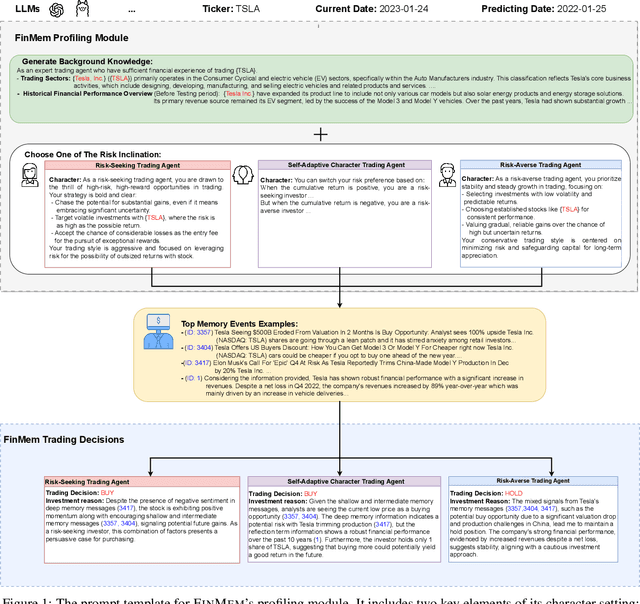
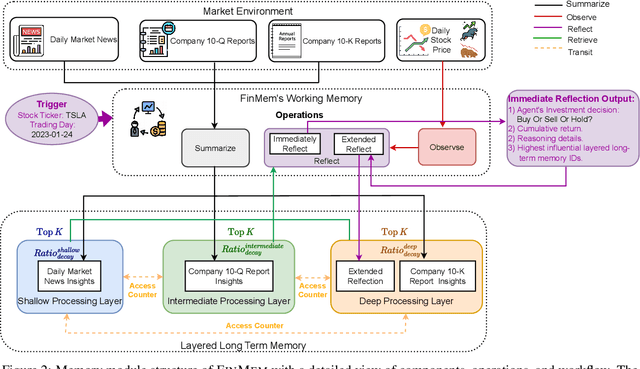
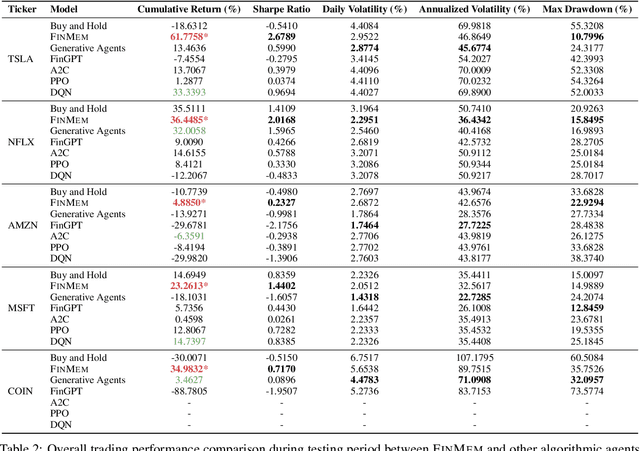

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.