 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion
Nov 27, 2023
Recent advances in generative AI have unveiled significant potential for the creation of 3D content. However, current methods either apply a pre-trained 2D diffusion model with the time-consuming score distillation sampling (SDS), or a direct 3D diffusion model trained on limited 3D data losing generation diversity. In this work, we approach the problem by employing a multi-view 2.5D diffusion fine-tuned from a pre-trained 2D diffusion model. The multi-view 2.5D diffusion directly models the structural distribution of 3D data, while still maintaining the strong generalization ability of the original 2D diffusion model, filling the gap between 2D diffusion-based and direct 3D diffusion-based methods for 3D content generation. During inference, multi-view normal maps are generated using the 2.5D diffusion, and a novel differentiable rasterization scheme is introduced to fuse the almost consistent multi-view normal maps into a consistent 3D model. We further design a normal-conditioned multi-view image generation module for fast appearance generation given the 3D geometry. Our method is a one-pass diffusion process and does not require any SDS optimization as post-processing. We demonstrate through extensive experiments that, our direct 2.5D generation with the specially-designed fusion scheme can achieve diverse, mode-seeking-free, and high-fidelity 3D content generation in only 10 seconds. Project page: https://nju-3dv.github.io/projects/direct25.
Rethinking Privacy in Machine Learning Pipelines from an Information Flow Control Perspective
Nov 27, 2023Modern machine learning systems use models trained on ever-growing corpora. Typically, metadata such as ownership, access control, or licensing information is ignored during training. Instead, to mitigate privacy risks, we rely on generic techniques such as dataset sanitization and differentially private model training, with inherent privacy/utility trade-offs that hurt model performance. Moreover, these techniques have limitations in scenarios where sensitive information is shared across multiple participants and fine-grained access control is required. By ignoring metadata, we therefore miss an opportunity to better address security, privacy, and confidentiality challenges. In this paper, we take an information flow control perspective to describe machine learning systems, which allows us to leverage metadata such as access control policies and define clear-cut privacy and confidentiality guarantees with interpretable information flows. Under this perspective, we contrast two different approaches to achieve user-level non-interference: 1) fine-tuning per-user models, and 2) retrieval augmented models that access user-specific datasets at inference time. We compare these two approaches to a trivially non-interfering zero-shot baseline using a public model and to a baseline that fine-tunes this model on the whole corpus. We evaluate trained models on two datasets of scientific articles and demonstrate that retrieval augmented architectures deliver the best utility, scalability, and flexibility while satisfying strict non-interference guarantees.
Machine-learning parameter tracking with partial state observation
Nov 15, 2023Complex and nonlinear dynamical systems often involve parameters that change with time, accurate tracking of which is essential to tasks such as state estimation, prediction, and control. Existing machine-learning methods require full state observation of the underlying system and tacitly assume adiabatic changes in the parameter. Formulating an inverse problem and exploiting reservoir computing, we develop a model-free and fully data-driven framework to accurately track time-varying parameters from partial state observation in real time. In particular, with training data from a subset of the dynamical variables of the system for a small number of known parameter values, the framework is able to accurately predict the parameter variations in time. Low- and high-dimensional, Markovian and non-Markovian nonlinear dynamical systems are used to demonstrate the power of the machine-learning based parameter-tracking framework. Pertinent issues affecting the tracking performance are addressed.
FLAIR: A Conditional Diffusion Framework with Applications to Face Video Restoration
Nov 26, 2023Face video restoration (FVR) is a challenging but important problem where one seeks to recover a perceptually realistic face videos from a low-quality input. While diffusion probabilistic models (DPMs) have been shown to achieve remarkable performance for face image restoration, they often fail to preserve temporally coherent, high-quality videos, compromising the fidelity of reconstructed faces. We present a new conditional diffusion framework called FLAIR for FVR. FLAIR ensures temporal consistency across frames in a computationally efficient fashion by converting a traditional image DPM into a video DPM. The proposed conversion uses a recurrent video refinement layer and a temporal self-attention at different scales. FLAIR also uses a conditional iterative refinement process to balance the perceptual and distortion quality during inference. This process consists of two key components: a data-consistency module that analytically ensures that the generated video precisely matches its degraded observation and a coarse-to-fine image enhancement module specifically for facial regions. Our extensive experiments show superiority of FLAIR over the current state-of-the-art (SOTA) for video super-resolution, deblurring, JPEG restoration, and space-time frame interpolation on two high-quality face video datasets.
Negotiating with LLMS: Prompt Hacks, Skill Gaps, and Reasoning Deficits
Nov 26, 2023Large language models LLMs like ChatGPT have reached the 100 Mio user barrier in record time and might increasingly enter all areas of our life leading to a diverse set of interactions between those Artificial Intelligence models and humans. While many studies have discussed governance and regulations deductively from first-order principles, few studies provide an inductive, data-driven lens based on observing dialogues between humans and LLMs especially when it comes to non-collaborative, competitive situations that have the potential to pose a serious threat to people. In this work, we conduct a user study engaging over 40 individuals across all age groups in price negotiations with an LLM. We explore how people interact with an LLM, investigating differences in negotiation outcomes and strategies. Furthermore, we highlight shortcomings of LLMs with respect to their reasoning capabilities and, in turn, susceptiveness to prompt hacking, which intends to manipulate the LLM to make agreements that are against its instructions or beyond any rationality. We also show that the negotiated prices humans manage to achieve span a broad range, which points to a literacy gap in effectively interacting with LLMs.
From OTFS to DD-ISAC: Integrating Sensing and Communications in the Delay Doppler Domain
Nov 26, 2023Next-generation vehicular networks are expected to provide the capability of robust environmental sensing in addition to reliable communications to meet intelligence requirements. A promising solution is the integrated sensing and communication (ISAC) technology, which performs both functionalities using the same spectrum and hardware resources. Most existing works on ISAC consider the Orthogonal Frequency Division Multiplexing (OFDM) waveform. Nevertheless, vehicle motion introduces Doppler shift, which breaks the subcarrier orthogonality and leads to performance degradation. The recently proposed Orthogonal Time Frequency Space (OTFS) modulation, which exploits various advantages of Delay Doppler (DD) channels, has been shown to support reliable communication in high-mobility scenarios. Moreover, the DD waveform can directly interact with radar sensing parameters, which are actually delay and Doppler shifts. This paper investigates the advantages of applying the DD communication waveform to ISAC. Specifically, we first provide a comprehensive overview of implementing DD communications, based on which several advantages of DD-ISAC over OFDM-based ISAC are revealed, including transceiver designs and the ambiguity function. Furthermore, a detailed performance comparison are presented, where the target detection probability and the mean squared error (MSE) performance are also studied. Finally, some challenges and opportunities of DD-ISAC are also provided.
Modality-aware Transformer for Time series Forecasting
Oct 02, 2023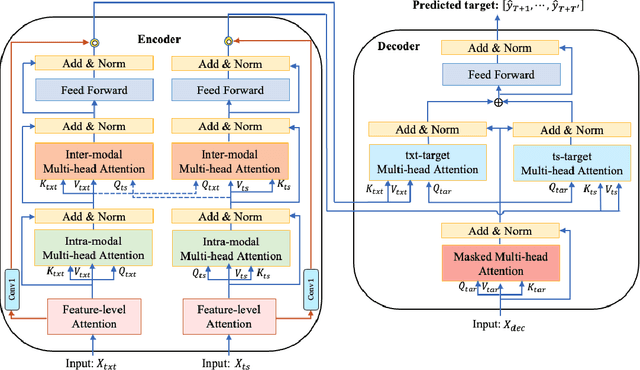

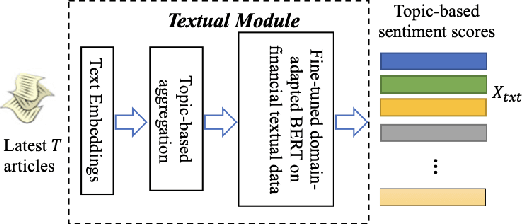
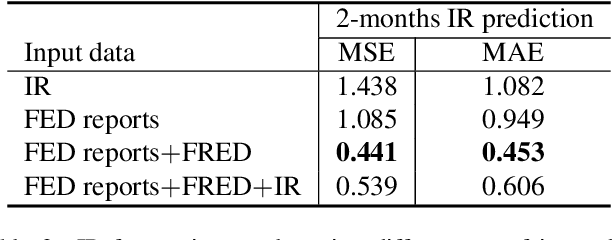
Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
S$^3$-TTA: Scale-Style Selection for Test-Time Augmentation in Biomedical Image Segmentation
Oct 25, 2023Deep-learning models have been successful in biomedical image segmentation. To generalize for real-world deployment, test-time augmentation (TTA) methods are often used to transform the test image into different versions that are hopefully closer to the training domain. Unfortunately, due to the vast diversity of instance scale and image styles, many augmented test images produce undesirable results, thus lowering the overall performance. This work proposes a new TTA framework, S$^3$-TTA, which selects the suitable image scale and style for each test image based on a transformation consistency metric. In addition, S$^3$-TTA constructs an end-to-end augmentation-segmentation joint-training pipeline to ensure a task-oriented augmentation. On public benchmarks for cell and lung segmentation, S$^3$-TTA demonstrates improvements over the prior art by 3.4% and 1.3%, respectively, by simply augmenting the input data in testing phase.
Graph Neural Ordinary Differential Equations-based method for Collaborative Filtering
Nov 21, 2023Graph Convolution Networks (GCNs) are widely considered state-of-the-art for collaborative filtering. Although several GCN-based methods have been proposed and achieved state-of-the-art performance in various tasks, they can be computationally expensive and time-consuming to train if too many layers are created. However, since the linear GCN model can be interpreted as a differential equation, it is possible to transfer it to an ODE problem. This inspired us to address the computational limitations of GCN-based models by designing a simple and efficient NODE-based model that can skip some GCN layers to reach the final state, thus avoiding the need to create many layers. In this work, we propose a Graph Neural Ordinary Differential Equation-based method for Collaborative Filtering (GODE-CF). This method estimates the final embedding by utilizing the information captured by one or two GCN layers. To validate our approach, we conducted experiments on multiple datasets. The results demonstrate that our model outperforms competitive baselines, including GCN-based models and other state-of-the-art CF methods. Notably, our proposed GODE-CF model has several advantages over traditional GCN-based models. It is simple, efficient, and has a fast training time, making it a practical choice for real-world situations.
Real-Time Neural BRDF with Spherically Distributed Primitives
Oct 12, 2023We propose a novel compact and efficient neural BRDF offering highly versatile material representation, yet with very-light memory and neural computation consumption towards achieving real-time rendering. The results in Figure 1, rendered at full HD resolution on a current desktop machine, show that our system achieves real-time rendering with a wide variety of appearances, which is approached by the following two designs. On the one hand, noting that bidirectional reflectance is distributed in a very sparse high-dimensional subspace, we propose to project the BRDF into two low-dimensional components, i.e., two hemisphere feature-grids for incoming and outgoing directions, respectively. On the other hand, learnable neural reflectance primitives are distributed on our highly-tailored spherical surface grid, which offer informative features for each component and alleviate the conventional heavy feature learning network to a much smaller one, leading to very fast evaluation. These primitives are centrally stored in a codebook and can be shared across multiple grids and even across materials, based on the low-cost indices stored in material-specific spherical surface grids. Our neural BRDF, which is agnostic to the material, provides a unified framework that can represent a variety of materials in consistent manner. Comprehensive experimental results on measured BRDF compression, Monte Carlo simulated BRDF acceleration, and extension to spatially varying effect demonstrate the superior quality and generalizability achieved by the proposed scheme.