 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Auto-CsiNet: Scenario-customized Automatic Neural Network Architecture Generation for Massive MIMO CSI Feedback
Nov 27, 2023
Deep learning has revolutionized the design of the channel state information (CSI) feedback module in wireless communications. However, designing the optimal neural network (NN) architecture for CSI feedback can be a laborious and time-consuming process. Manual design can be prohibitively expensive for customizing NNs to different scenarios. This paper proposes using neural architecture search (NAS) to automate the generation of scenario-customized CSI feedback NN architectures, thereby maximizing the potential of deep learning in exclusive environments. By employing automated machine learning and gradient-descent-based NAS, an efficient and cost-effective architecture design process is achieved. The proposed approach leverages implicit scene knowledge, integrating it into the scenario customization process in a data-driven manner, and fully exploits the potential of deep learning for each specific scenario. To address the issue of excessive search, early stopping and elastic selection mechanisms are employed, enhancing the efficiency of the proposed scheme. The experimental results demonstrate that the automatically generated architecture, known as Auto-CsiNet, outperforms manually-designed models in both reconstruction performance (achieving approximately a 14% improvement) and complexity (reducing it by approximately 50%). Furthermore, the paper analyzes the impact of the scenario on the NN architecture and its capacity.
InterControl: Generate Human Motion Interactions by Controlling Every Joint
Nov 27, 2023Text-conditioned human motion generation model has achieved great progress by introducing diffusion models and corresponding control signals. However, the interaction between humans are still under explored. To model interactions of arbitrary number of humans, we define interactions as human joint pairs that are either in contact or separated, and leverage {\em Large Language Model (LLM) Planner} to translate interaction descriptions into contact plans. Based on the contact plans, interaction generation could be achieved by spatially controllable motion generation methods by taking joint contacts as spatial conditions. We present a novel approach named InterControl for flexible spatial control of every joint in every person at any time by leveraging motion diffusion model only trained on single-person data. We incorporate a motion controlnet to generate coherent and realistic motions given sparse spatial control signals and a loss guidance module to precisely align any joint to the desired position in a classifier guidance manner via Inverse Kinematics (IK). Extensive experiments on HumanML3D and KIT-ML dataset demonstrate its effectiveness in versatile joint control. We also collect data of joint contact pairs by LLMs to show InterControl's ability in human interaction generation.
Spatial Diarization for Meeting Transcription with Ad-Hoc Acoustic Sensor Networks
Nov 27, 2023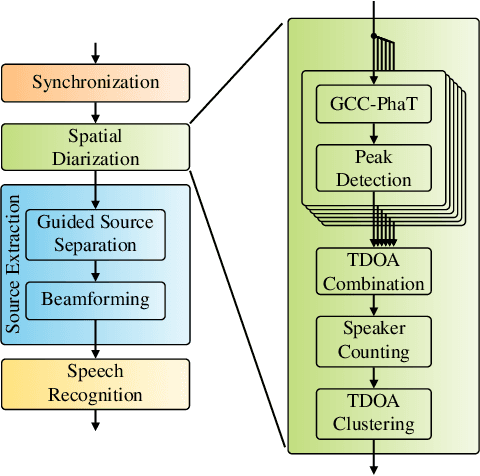
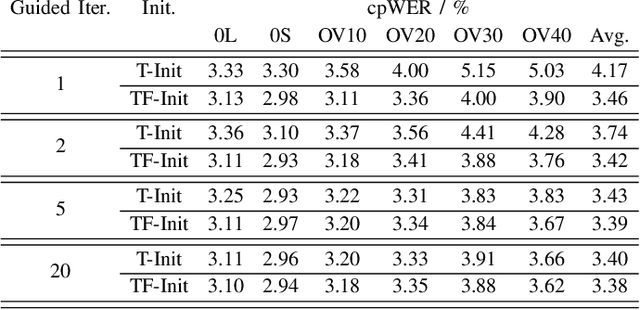
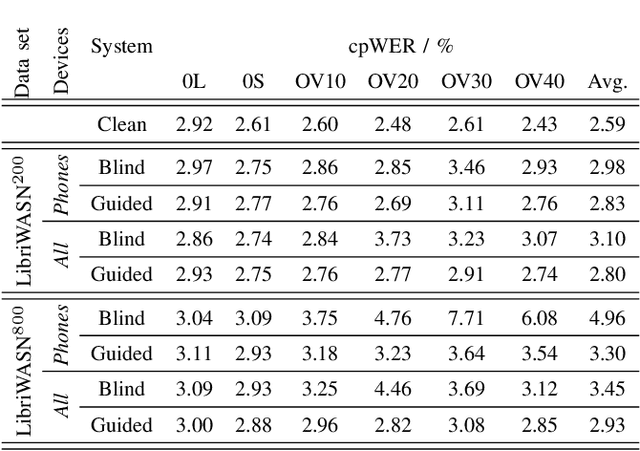
We propose a diarization system, that estimates "who spoke when" based on spatial information, to be used as a front-end of a meeting transcription system running on the signals gathered from an acoustic sensor network (ASN). Although the spatial distribution of the microphones is advantageous, exploiting the spatial diversity for diarization and signal enhancement is challenging, because the microphones' positions are typically unknown, and the recorded signals are initially unsynchronized in general. Here, we approach these issues by first blindly synchronizing the signals and then estimating time differences of arrival (TDOAs). The TDOA information is exploited to estimate the speakers' activity, even in the presence of multiple speakers being simultaneously active. This speaker activity information serves as a guide for a spatial mixture model, on which basis the individual speaker's signals are extracted via beamforming. Finally, the extracted signals are forwarded to a speech recognizer. Additionally, a novel initialization scheme for spatial mixture models based on the TDOA estimates is proposed. Experiments conducted on real recordings from the LibriWASN data set have shown that our proposed system is advantageous compared to a system using a spatial mixture model, which does not make use of external diarization information.
A Simple Geometric-Aware Indoor Positioning Interpolation Algorithm Based on Manifold Learning
Nov 27, 2023Interpolation methodologies have been widely used within the domain of indoor positioning systems. However, existing indoor positioning interpolation algorithms exhibit several inherent limitations, including reliance on complex mathematical models, limited flexibility, and relatively low precision. To enhance the accuracy and efficiency of indoor positioning interpolation techniques, this paper proposes a simple yet powerful geometric-aware interpolation algorithm for indoor positioning tasks. The key to our algorithm is to exploit the geometric attributes of the local topological manifold using manifold learning principles. Therefore, instead of constructing complicated mathematical models, the proposed algorithm facilitates the more precise and efficient estimation of points grounded in the local topological manifold. Moreover, our proposed method can be effortlessly integrated into any indoor positioning system, thereby bolstering its adaptability. Through a systematic array of experiments and comprehensive performance analyses conducted on both simulated and real-world datasets, we demonstrate that the proposed algorithm consistently outperforms the most commonly used and representative interpolation approaches regarding interpolation accuracy and efficiency. Furthermore, the experimental results also underscore the substantial practical utility of our method and its potential applicability in real-time indoor positioning scenarios.
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
Nov 21, 2023In this paper, we introduce $\textbf{GS-SLAM}$ that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D re-rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussian in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. The source code will be released soon.
Density Distribution-based Learning Framework for Addressing Online Continual Learning Challenges
Nov 22, 2023In this paper, we address the challenges of online Continual Learning (CL) by introducing a density distribution-based learning framework. CL, especially the Class Incremental Learning, enables adaptation to new test distributions while continuously learning from a single-pass training data stream, which is more in line with the practical application requirements of real-world scenarios. However, existing CL methods often suffer from catastrophic forgetting and higher computing costs due to complex algorithm designs, limiting their practical use. Our proposed framework overcomes these limitations by achieving superior average accuracy and time-space efficiency, bridging the performance gap between CL and classical machine learning. Specifically, we adopt an independent Generative Kernel Density Estimation (GKDE) model for each CL task. During the testing stage, the GKDEs utilize a self-reported max probability density value to determine which one is responsible for predicting incoming test instances. A GKDE-based learning objective can ensure that samples with the same label are grouped together, while dissimilar instances are pushed farther apart. Extensive experiments conducted on multiple CL datasets validate the effectiveness of our proposed framework. Our method outperforms popular CL approaches by a significant margin, while maintaining competitive time-space efficiency, making our framework suitable for real-world applications. Code will be available at https://github.com/xxxx/xxxx.
Real-Time Neural BRDF with Spherically Distributed Primitives
Oct 12, 2023We propose a novel compact and efficient neural BRDF offering highly versatile material representation, yet with very-light memory and neural computation consumption towards achieving real-time rendering. The results in Figure 1, rendered at full HD resolution on a current desktop machine, show that our system achieves real-time rendering with a wide variety of appearances, which is approached by the following two designs. On the one hand, noting that bidirectional reflectance is distributed in a very sparse high-dimensional subspace, we propose to project the BRDF into two low-dimensional components, i.e., two hemisphere feature-grids for incoming and outgoing directions, respectively. On the other hand, learnable neural reflectance primitives are distributed on our highly-tailored spherical surface grid, which offer informative features for each component and alleviate the conventional heavy feature learning network to a much smaller one, leading to very fast evaluation. These primitives are centrally stored in a codebook and can be shared across multiple grids and even across materials, based on the low-cost indices stored in material-specific spherical surface grids. Our neural BRDF, which is agnostic to the material, provides a unified framework that can represent a variety of materials in consistent manner. Comprehensive experimental results on measured BRDF compression, Monte Carlo simulated BRDF acceleration, and extension to spatially varying effect demonstrate the superior quality and generalizability achieved by the proposed scheme.
Projecting infinite time series graphs to finite marginal graphs using number theory
Oct 09, 2023In recent years, a growing number of method and application works have adapted and applied the causal-graphical-model framework to time series data. Many of these works employ time-resolved causal graphs that extend infinitely into the past and future and whose edges are repetitive in time, thereby reflecting the assumption of stationary causal relationships. However, most results and algorithms from the causal-graphical-model framework are not designed for infinite graphs. In this work, we develop a method for projecting infinite time series graphs with repetitive edges to marginal graphical models on a finite time window. These finite marginal graphs provide the answers to $m$-separation queries with respect to the infinite graph, a task that was previously unresolved. Moreover, we argue that these marginal graphs are useful for causal discovery and causal effect estimation in time series, effectively enabling to apply results developed for finite graphs to the infinite graphs. The projection procedure relies on finding common ancestors in the to-be-projected graph and is, by itself, not new. However, the projection procedure has not yet been algorithmically implemented for time series graphs since in these infinite graphs there can be infinite sets of paths that might give rise to common ancestors. We solve the search over these possibly infinite sets of paths by an intriguing combination of path-finding techniques for finite directed graphs and solution theory for linear Diophantine equations. By providing an algorithm that carries out the projection, our paper makes an important step towards a theoretically-grounded and method-agnostic generalization of a range of causal inference methods and results to time series.
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Oct 10, 2023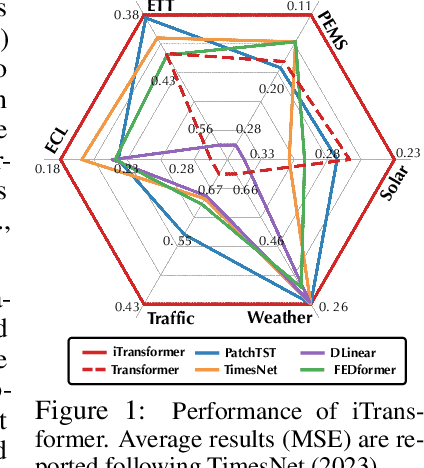
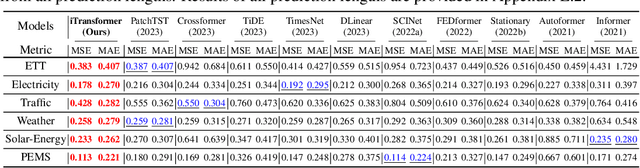
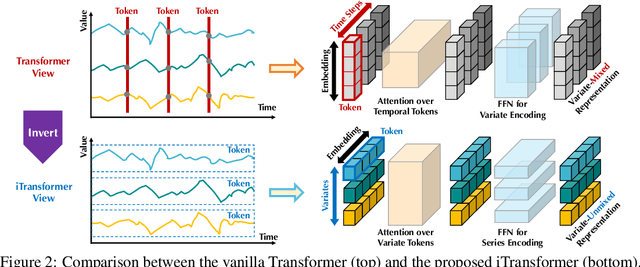
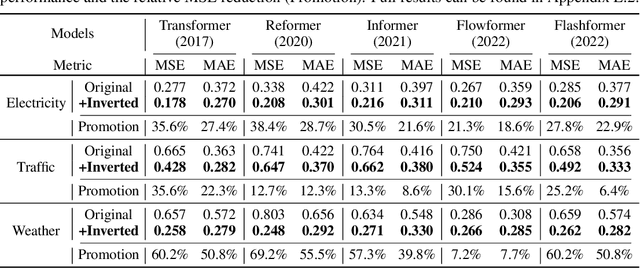
The recent boom of linear forecasting models questions the ongoing passion for architectural modifications of Transformer-based forecasters. These forecasters leverage Transformers to model the global dependencies over temporal tokens of time series, with each token formed by multiple variates of the same timestamp. However, Transformer is challenged in forecasting series with larger lookback windows due to performance degradation and computation explosion. Besides, the unified embedding for each temporal token fuses multiple variates with potentially unaligned timestamps and distinct physical measurements, which may fail in learning variate-centric representations and result in meaningless attention maps. In this work, we reflect on the competent duties of Transformer components and repurpose the Transformer architecture without any adaptation on the basic components. We propose iTransformer that simply inverts the duties of the attention mechanism and the feed-forward network. Specifically, the time points of individual series are embedded into variate tokens which are utilized by the attention mechanism to capture multivariate correlations; meanwhile, the feed-forward network is applied for each variate token to learn nonlinear representations. The iTransformer model achieves consistent state-of-the-art on several real-world datasets, which further empowers the Transformer family with promoted performance, generalization ability across different variates, and better utilization of arbitrary lookback windows, making it a nice alternative as the fundamental backbone of time series forecasting.
Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos
Nov 29, 2023We propose a novel benchmark for cross-view knowledge transfer of dense video captioning, adapting models from web instructional videos with exocentric views to an egocentric view. While dense video captioning (predicting time segments and their captions) is primarily studied with exocentric videos (e.g., YouCook2), benchmarks with egocentric videos are restricted due to data scarcity. To overcome the limited video availability, transferring knowledge from abundant exocentric web videos is demanded as a practical approach. However, learning the correspondence between exocentric and egocentric views is difficult due to their dynamic view changes. The web videos contain mixed views focusing on either human body actions or close-up hand-object interactions, while the egocentric view is constantly shifting as the camera wearer moves. This necessitates the in-depth study of cross-view transfer under complex view changes. In this work, we first create a real-life egocentric dataset (EgoYC2) whose captions are shared with YouCook2, enabling transfer learning between these datasets assuming their ground-truth is accessible. To bridge the view gaps, we propose a view-invariant learning method using adversarial training in both the pre-training and fine-tuning stages. While the pre-training is designed to learn invariant features against the mixed views in the web videos, the view-invariant fine-tuning further mitigates the view gaps between both datasets. We validate our proposed method by studying how effectively it overcomes the view change problem and efficiently transfers the knowledge to the egocentric domain. Our benchmark pushes the study of the cross-view transfer into a new task domain of dense video captioning and will envision methodologies to describe egocentric videos in natural language.