 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-vectorized numerical integration for systems of ODEs
Oct 12, 2023
Stiff systems of ordinary differential equations (ODEs) and sparse training data are common in scientific problems. This paper describes efficient, implicit, vectorized methods for integrating stiff systems of ordinary differential equations through time and calculating parameter gradients with the adjoint method. The main innovation is to vectorize the problem both over the number of independent times series and over a batch or "chunk" of sequential time steps, effectively vectorizing the assembly of the implicit system of ODEs. The block-bidiagonal structure of the linearized implicit system for the backward Euler method allows for further vectorization using parallel cyclic reduction (PCR). Vectorizing over both axes of the input data provides a higher bandwidth of calculations to the computing device, allowing even problems with comparatively sparse data to fully utilize modern GPUs and achieving speed ups of greater than 100x, compared to standard, sequential time integration. We demonstrate the advantages of implicit, vectorized time integration with several example problems, drawn from both analytical stiff and non-stiff ODE models as well as neural ODE models. We also describe and provide a freely available open-source implementation of the methods developed here.
Let the LLMs Talk: Simulating Human-to-Human Conversational QA via Zero-Shot LLM-to-LLM Interactions
Dec 05, 2023Conversational question-answering (CQA) systems aim to create interactive search systems that effectively retrieve information by interacting with users. To replicate human-to-human conversations, existing work uses human annotators to play the roles of the questioner (student) and the answerer (teacher). Despite its effectiveness, challenges exist as human annotation is time-consuming, inconsistent, and not scalable. To address this issue and investigate the applicability of large language models (LLMs) in CQA simulation, we propose a simulation framework that employs zero-shot learner LLMs for simulating teacher-student interactions. Our framework involves two LLMs interacting on a specific topic, with the first LLM acting as a student, generating questions to explore a given search topic. The second LLM plays the role of a teacher by answering questions and is equipped with additional information, including a text on the given topic. We implement both the student and teacher by zero-shot prompting the GPT-4 model. To assess the effectiveness of LLMs in simulating CQA interactions and understand the disparities between LLM- and human-generated conversations, we evaluate the simulated data from various perspectives. We begin by evaluating the teacher's performance through both automatic and human assessment. Next, we evaluate the performance of the student, analyzing and comparing the disparities between questions generated by the LLM and those generated by humans. Furthermore, we conduct extensive analyses to thoroughly examine the LLM performance by benchmarking state-of-the-art reading comprehension models on both datasets. Our results reveal that the teacher LLM generates lengthier answers that tend to be more accurate and complete. The student LLM generates more diverse questions, covering more aspects of a given topic.
Convergence Rates for Stochastic Approximation: Biased Noise with Unbounded Variance, and Applications
Dec 05, 2023The Stochastic Approximation (SA) algorithm introduced by Robbins and Monro in 1951 has been a standard method for solving equations of the form $\mathbf{f}({\boldsymbol {\theta}}) = \mathbf{0}$, when only noisy measurements of $\mathbf{f}(\cdot)$ are available. If $\mathbf{f}({\boldsymbol {\theta}}) = \nabla J({\boldsymbol {\theta}})$ for some function $J(\cdot)$, then SA can also be used to find a stationary point of $J(\cdot)$. In much of the literature, it is assumed that the error term ${\boldsymbol {xi}}_{t+1}$ has zero conditional mean, and that its conditional variance is bounded as a function of $t$ (though not necessarily with respect to ${\boldsymbol {\theta}}_t$). Also, for the most part, the emphasis has been on ``synchronous'' SA, whereby, at each time $t$, \textit{every} component of ${\boldsymbol {\theta}}_t$ is updated. Over the years, SA has been applied to a variety of areas, out of which two are the focus in this paper: Convex and nonconvex optimization, and Reinforcement Learning (RL). As it turns out, in these applications, the above-mentioned assumptions do not always hold. In zero-order methods, the error neither has zero mean nor bounded conditional variance. In the present paper, we extend SA theory to encompass errors with nonzero conditional mean and/or unbounded conditional variance, and also asynchronous SA. In addition, we derive estimates for the rate of convergence of the algorithm. Then we apply the new results to problems in nonconvex optimization, and to Markovian SA, a recently emerging area in RL. We prove that SA converges in these situations, and compute the ``optimal step size sequences'' to maximize the estimated rate of convergence.
A-JEPA: Joint-Embedding Predictive Architecture Can Listen
Nov 28, 2023This paper presents that the masked-modeling principle driving the success of large foundational vision models can be effectively applied to audio by making predictions in a latent space. We introduce Audio-based Joint-Embedding Predictive Architecture (A-JEPA), a simple extension method for self-supervised learning from the audio spectrum. Following the design of I-JEPA, our A-JEPA encodes visible audio spectrogram patches with a curriculum masking strategy via context encoder, and predicts the representations of regions sampled at well-designed locations. The target representations of those regions are extracted by the exponential moving average of context encoder, \emph{i.e.}, target encoder, on the whole spectrogram. We find it beneficial to transfer random block masking into time-frequency aware masking in a curriculum manner, considering the complexity of highly correlated in local time and frequency in audio spectrograms. To enhance contextual semantic understanding and robustness, we fine-tune the encoder with a regularized masking on target datasets, instead of input dropping or zero. Empirically, when built with Vision Transformers structure, we find A-JEPA to be highly scalable and sets new state-of-the-art performance on multiple audio and speech classification tasks, outperforming other recent models that use externally supervised pre-training.
Multi-Scale Sub-Band Constant-Q Transform Discriminator for High-Fidelity Vocoder
Nov 25, 2023Generative Adversarial Network (GAN) based vocoders are superior in inference speed and synthesis quality when reconstructing an audible waveform from an acoustic representation. This study focuses on improving the discriminator to promote GAN-based vocoders. Most existing time-frequency-representation-based discriminators are rooted in Short-Time Fourier Transform (STFT), whose time-frequency resolution in a spectrogram is fixed, making it incompatible with signals like singing voices that require flexible attention for different frequency bands. Motivated by that, our study utilizes the Constant-Q Transform (CQT), which owns dynamic resolution among frequencies, contributing to a better modeling ability in pitch accuracy and harmonic tracking. Specifically, we propose a Multi-Scale Sub-Band CQT (MS-SB-CQT) Discriminator, which operates on the CQT spectrogram at multiple scales and performs sub-band processing according to different octaves. Experiments conducted on both speech and singing voices confirm the effectiveness of our proposed method. Moreover, we also verified that the CQT-based and the STFT-based discriminators could be complementary under joint training. Specifically, enhanced by the proposed MS-SB-CQT and the existing MS-STFT Discriminators, the MOS of HiFi-GAN can be boosted from 3.27 to 3.87 for seen singers and from 3.40 to 3.78 for unseen singers.
R$^2$NMPC: A Real-Time Reduced Robustified Nonlinear Model Predictive Control with Ellipsoidal Uncertainty Sets for Autonomous Vehicle Motion Control
Nov 10, 2023In this paper, we present a novel Reduced Robustified NMPC (R$^2$NMPC) algorithm that has the same complexity as an equivalent nominal NMPC while enhancing it with robustified constraints based on the dynamics of ellipsoidal uncertainty sets. This promises both a closed-loop- and constraint satisfaction performance equivalent to common Robustified NMPC approaches, while drastically reducing the computational complexity. The main idea lies in approximating the ellipsoidal uncertainty sets propagation over the prediction horizon with the system dynamics' sensitivities inferred from the last optimal control problem (OCP) solution, and similarly for the gradients to robustify the constraints. Thus, we do not require the decision variables related to the uncertainty propagation within the OCP, rendering it computationally tractable. Next, we illustrate the real-time control capabilities of our algorithm in handling a complex, high-dimensional, and highly nonlinear system, namely the trajectory following of an autonomous passenger vehicle modeled with a dynamic nonlinear single-track model. Our experimental findings, alongside a comparative assessment against other Robust NMPC approaches, affirm the robustness of our method in effectively tracking an optimal racetrack trajectory while satisfying the nonlinear constraints. This performance is achieved while fully utilizing the vehicle's interface limits, even at high speeds of up to 37.5m/s, and successfully managing state estimation disturbances. Remarkably, our approach maintains a mean solving frequency of 144Hz.
Hashmarks: Privacy-Preserving Benchmarks for High-Stakes AI Evaluation
Dec 01, 2023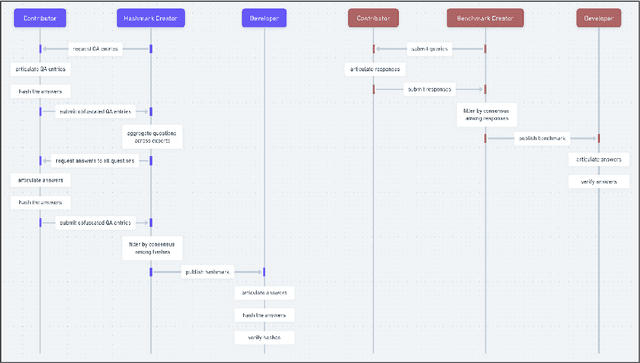
There is a growing need to gain insight into language model capabilities that relate to sensitive topics, such as bioterrorism or cyberwarfare. However, traditional open source benchmarks are not fit for the task, due to the associated practice of publishing the correct answers in human-readable form. At the same time, enforcing mandatory closed-quarters evaluations might stifle development and erode trust. In this context, we propose hashmarking, a protocol for evaluating language models in the open without having to disclose the correct answers. In its simplest form, a hashmark is a benchmark whose reference solutions have been cryptographically hashed prior to publication. Following an overview of the proposed evaluation protocol, we go on to assess its resilience against traditional attack vectors (e.g. rainbow table attacks), as well as against failure modes unique to increasingly capable generative models.
Structured Two-Stage True-Time-Delay Array Codebook Design for Multi-User Data Communication
Oct 31, 2023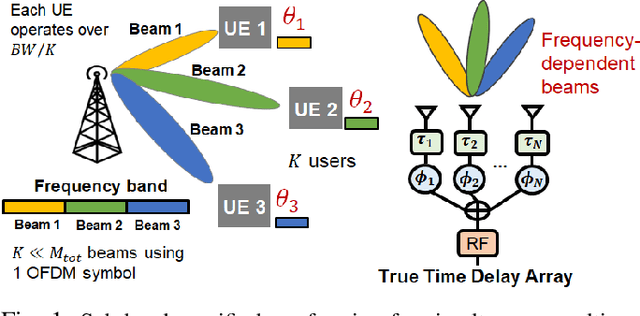
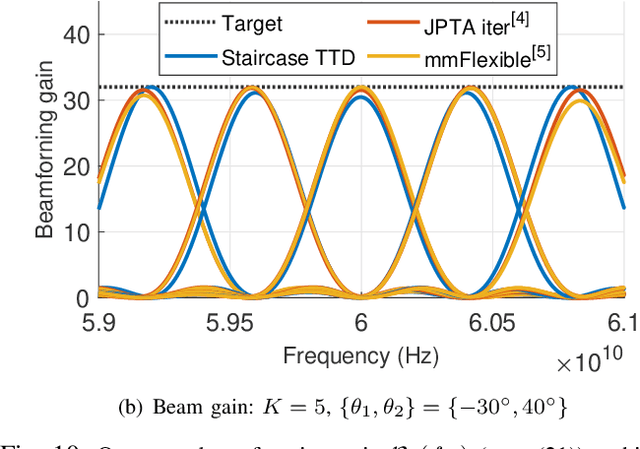
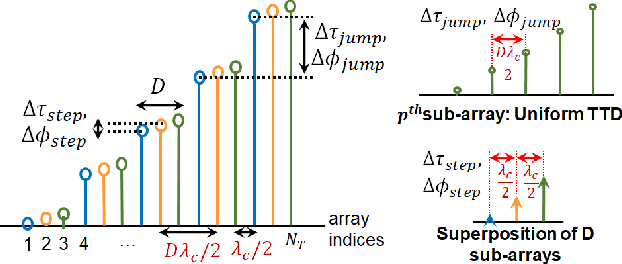
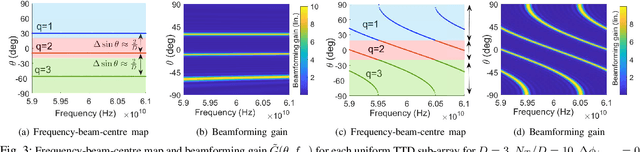
Wideband millimeter-wave and terahertz (THz) systems can facilitate simultaneous data communication with multiple spatially separated users. It is desirable to orthogonalize users across sub-bands by deploying frequency-dependent beams with a sub-band-specific spatial response. True-Time-Delay (TTD) antenna arrays are a promising wideband architecture to implement sub-band-specific dispersion of beams across space using a single radio frequency (RF) chain. This paper proposes a structured design of analog TTD codebooks to generate beams that exhibit quantized sub-band-to-angle mapping. We introduce a structured Staircase TTD codebook and analyze the frequency-spatial behaviour of the resulting beam patterns. We develop the closed-form two-stage design of the proposed codebook to achieve the desired sub-band-specific beams and evaluate their performance in multi-user communication networks.
Learning Multi-graph Structure for Temporal Knowledge Graph Reasoning
Dec 04, 2023Temporal Knowledge Graph (TKG) reasoning that forecasts future events based on historical snapshots distributed over timestamps is denoted as extrapolation and has gained significant attention. Owing to its extreme versatility and variation in spatial and temporal correlations, TKG reasoning presents a challenging task, demanding efficient capture of concurrent structures and evolutional interactions among facts. While existing methods have made strides in this direction, they still fall short of harnessing the diverse forms of intrinsic expressive semantics of TKGs, which encompass entity correlations across multiple timestamps and periodicity of temporal information. This limitation constrains their ability to thoroughly reflect historical dependencies and future trends. In response to these drawbacks, this paper proposes an innovative reasoning approach that focuses on Learning Multi-graph Structure (LMS). Concretely, it comprises three distinct modules concentrating on multiple aspects of graph structure knowledge within TKGs, including concurrent and evolutional patterns along timestamps, query-specific correlations across timestamps, and semantic dependencies of timestamps, which capture TKG features from various perspectives. Besides, LMS incorporates an adaptive gate for merging entity representations both along and across timestamps effectively. Moreover, it integrates timestamp semantics into graph attention calculations and time-aware decoders, in order to impose temporal constraints on events and narrow down prediction scopes with historical statistics. Extensive experimental results on five event-based benchmark datasets demonstrate that LMS outperforms state-of-the-art extrapolation models, indicating the superiority of modeling a multi-graph perspective for TKG reasoning.
Unleashing the Potential of Large Language Model: Zero-shot VQA for Flood Disaster Scenario
Dec 04, 2023Visual question answering (VQA) is a fundamental and essential AI task, and VQA-based disaster scenario understanding is a hot research topic. For instance, we can ask questions about a disaster image by the VQA model and the answer can help identify whether anyone or anything is affected by the disaster. However, previous VQA models for disaster damage assessment have some shortcomings, such as limited candidate answer space, monotonous question types, and limited answering capability of existing models. In this paper, we propose a zero-shot VQA model named Zero-shot VQA for Flood Disaster Damage Assessment (ZFDDA). It is a VQA model for damage assessment without pre-training. Also, with flood disaster as the main research object, we build a Freestyle Flood Disaster Image Question Answering dataset (FFD-IQA) to evaluate our VQA model. This new dataset expands the question types to include free-form, multiple-choice, and yes-no questions. At the same time, we expand the size of the previous dataset to contain a total of 2,058 images and 22,422 question-meta ground truth pairs. Most importantly, our model uses well-designed chain of thought (CoT) demonstrations to unlock the potential of the large language model, allowing zero-shot VQA to show better performance in disaster scenarios. The experimental results show that the accuracy in answering complex questions is greatly improved with CoT prompts. Our study provides a research basis for subsequent research of VQA for other disaster scenarios.