 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implicit-explicit Integrated Representations for Multi-view Video Compression
Nov 29, 2023



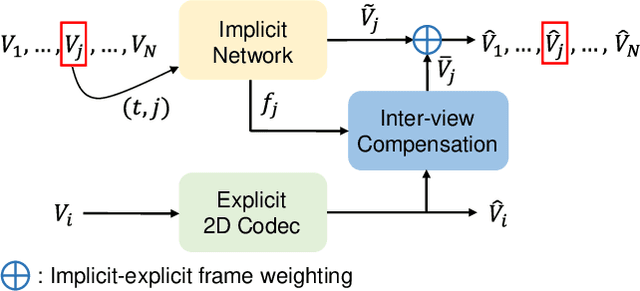
With the increasing consumption of 3D displays and virtual reality, multi-view video has become a promising format. However, its high resolution and multi-camera shooting result in a substantial increase in data volume, making storage and transmission a challenging task. To tackle these difficulties, we propose an implicit-explicit integrated representation for multi-view video compression. Specifically, we first use the explicit representation-based 2D video codec to encode one of the source views. Subsequently, we propose employing the implicit neural representation (INR)-based codec to encode the remaining views. The implicit codec takes the time and view index of multi-view video as coordinate inputs and generates the corresponding implicit reconstruction frames.To enhance the compressibility, we introduce a multi-level feature grid embedding and a fully convolutional architecture into the implicit codec. These components facilitate coordinate-feature and feature-RGB mapping, respectively. To further enhance the reconstruction quality from the INR codec, we leverage the high-quality reconstructed frames from the explicit codec to achieve inter-view compensation. Finally, the compensated results are fused with the implicit reconstructions from the INR to obtain the final reconstructed frames. Our proposed framework combines the strengths of both implicit neural representation and explicit 2D codec. Extensive experiments conducted on public datasets demonstrate that the proposed framework can achieve comparable or even superior performance to the latest multi-view video compression standard MIV and other INR-based schemes in terms of view compression and scene modeling.
HyperAttention: Long-context Attention in Near-Linear Time
Oct 11, 2023We present an approximate attention mechanism named HyperAttention to address the computational challenges posed by the growing complexity of long contexts used in Large Language Models (LLMs). Recent work suggests that in the worst-case scenario, quadratic time is necessary unless the entries of the attention matrix are bounded or the matrix has low stable rank. We introduce two parameters which measure: (1) the max column norm in the normalized attention matrix, and (2) the ratio of row norms in the unnormalized attention matrix after detecting and removing large entries. We use these fine-grained parameters to capture the hardness of the problem. Despite previous lower bounds, we are able to achieve a linear time sampling algorithm even when the matrix has unbounded entries or a large stable rank, provided the above parameters are small. HyperAttention features a modular design that easily accommodates integration of other fast low-level implementations, particularly FlashAttention. Empirically, employing Locality Sensitive Hashing (LSH) to identify large entries, HyperAttention outperforms existing methods, giving significant speed improvements compared to state-of-the-art solutions like FlashAttention. We validate the empirical performance of HyperAttention on a variety of different long-context length datasets. For example, HyperAttention makes the inference time of ChatGLM2 50\% faster on 32k context length while perplexity increases from 5.6 to 6.3. On larger context length, e.g., 131k, with causal masking, HyperAttention offers 5-fold speedup on a single attention layer.
Koopman Learning with Episodic Memory
Nov 21, 2023Koopman operator theory, a data-driven dynamical systems framework, has found significant success in learning models from complex, real-world data sets, enabling state-of-the-art prediction and control. The greater interpretability and lower computational costs of these models, compared to traditional machine learning methodologies, make Koopman learning an especially appealing approach. Despite this, little work has been performed on endowing Koopman learning with the ability to learn from its own mistakes. To address this, we equip Koopman methods - developed for predicting non-stationary time-series - with an episodic memory mechanism, enabling global recall of (or attention to) periods in time where similar dynamics previously occurred. We find that a basic implementation of Koopman learning with episodic memory leads to significant improvements in prediction on synthetic and real-world data. Our framework has considerable potential for expansion, allowing for future advances, and opens exciting new directions for Koopman learning.
HPCNeuroNet: Advancing Neuromorphic Audio Signal Processing with Transformer-Enhanced Spiking Neural Networks
Nov 21, 2023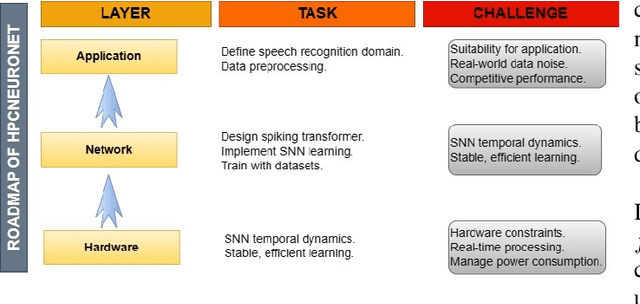
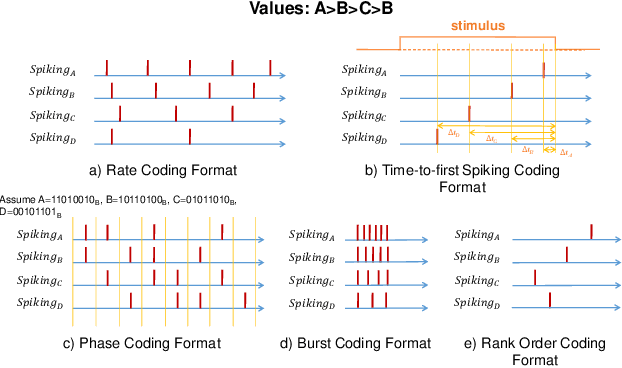
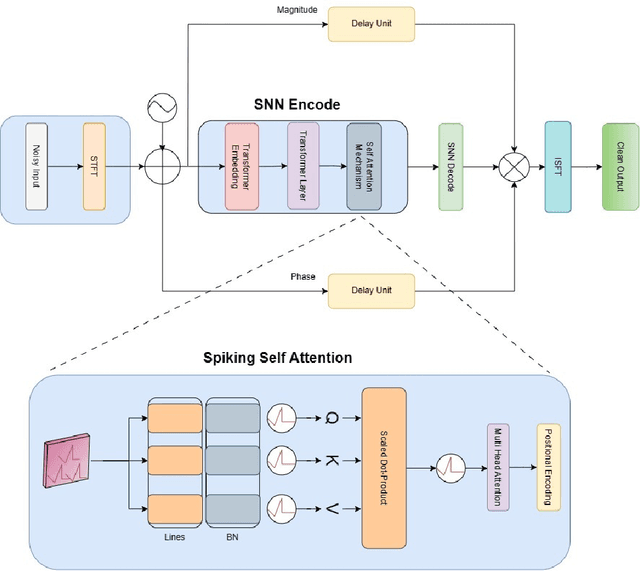
This paper presents a novel approach to neuromorphic audio processing by integrating the strengths of Spiking Neural Networks (SNNs), Transformers, and high-performance computing (HPC) into the HPCNeuroNet architecture. Utilizing the Intel N-DNS dataset, we demonstrate the system's capability to process diverse human vocal recordings across multiple languages and noise backgrounds. The core of our approach lies in the fusion of the temporal dynamics of SNNs with the attention mechanisms of Transformers, enabling the model to capture intricate audio patterns and relationships. Our architecture, HPCNeuroNet, employs the Short-Time Fourier Transform (STFT) for time-frequency representation, Transformer embeddings for dense vector generation, and SNN encoding/decoding mechanisms for spike train conversions. The system's performance is further enhanced by leveraging the computational capabilities of NVIDIA's GeForce RTX 3060 GPU and Intel's Core i9 12900H CPU. Additionally, we introduce a hardware implementation on the Xilinx VU37P HBM FPGA platform, optimizing for energy efficiency and real-time processing. The proposed accelerator achieves a throughput of 71.11 Giga-Operations Per Second (GOP/s) with a 3.55 W on-chip power consumption at 100 MHz. The comparison results with off-the-shelf devices and recent state-of-the-art implementations illustrate that the proposed accelerator has obvious advantages in terms of energy efficiency and design flexibility. Through design-space exploration, we provide insights into optimizing core capacities for audio tasks. Our findings underscore the transformative potential of integrating SNNs, Transformers, and HPC for neuromorphic audio processing, setting a new benchmark for future research and applications.
Deep Learning for Automatic Strain Quantification in Arrhythmogenic Right Ventricular Cardiomyopathy
Nov 24, 2023Quantification of cardiac motion with cine Cardiac Magnetic Resonance Imaging (CMRI) is an integral part of arrhythmogenic right ventricular cardiomyopathy (ARVC) diagnosis. Yet, the expert evaluation of motion abnormalities with CMRI is a challenging task. To automatically assess cardiac motion, we register CMRIs from different time points of the cardiac cycle using Implicit Neural Representations (INRs) and perform a biomechanically informed regularization inspired by the myocardial incompressibility assumption. To enhance the registration performance, our method first rectifies the inter-slice misalignment inherent to CMRI by performing a rigid registration guided by the long-axis views, and then increases the through-plane resolution using an unsupervised deep learning super-resolution approach. Finally, we propose to synergically combine information from short-axis and 4-chamber long-axis views, along with an initialization to incorporate information from multiple cardiac time points. Thereafter, to quantify cardiac motion, we calculate global and segmental strain over a cardiac cycle and compute the peak strain. The evaluation of the method is performed on a dataset of cine CMRI scans from 47 ARVC patients and 67 controls. Our results show that inter-slice alignment and generation of super-resolved volumes combined with joint analysis of the two cardiac views, notably improves registration performance. Furthermore, the proposed initialization yields more physiologically plausible registrations. The significant differences in the peak strain, discerned between the ARVC patients and healthy controls suggest that automated motion quantification methods may assist in diagnosis and provide further understanding of disease-specific alterations of cardiac motion.
Beyond Sole Strength: Customized Ensembles for Generalized Vision-Language Models
Nov 28, 2023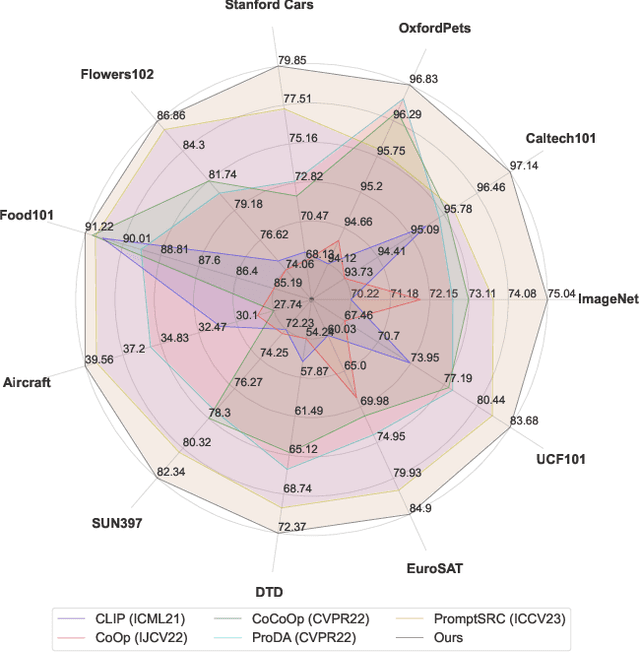
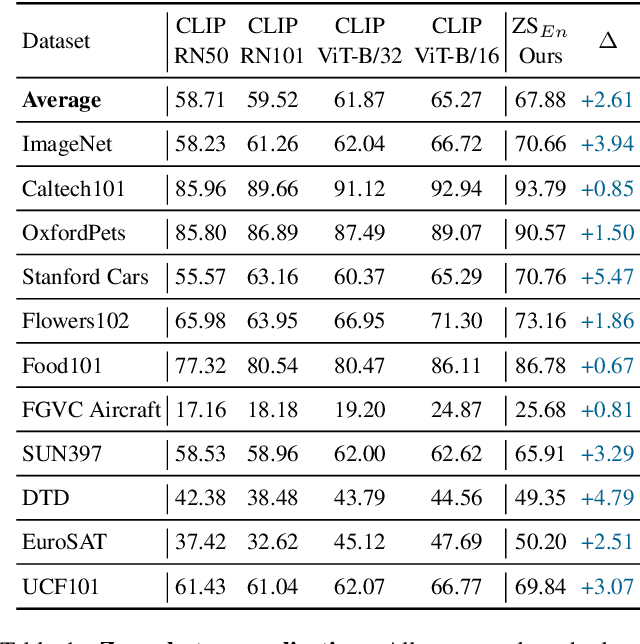
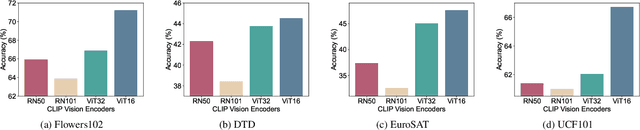
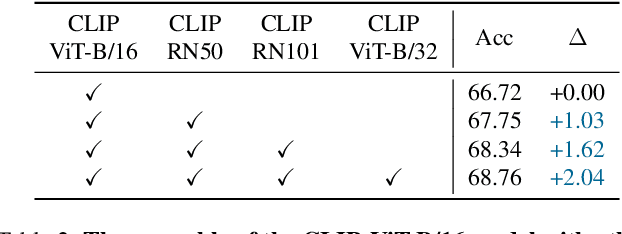
Fine-tuning pre-trained vision-language models (VLMs), e.g., CLIP, for the open-world generalization has gained increasing popularity due to its practical value. However, performance advancements are limited when relying solely on intricate algorithmic designs for a single model, even one exhibiting strong performance, e.g., CLIP-ViT-B/16. This paper, for the first time, explores the collaborative potential of leveraging much weaker VLMs to enhance the generalization of a robust single model. The affirmative findings motivate us to address the generalization problem from a novel perspective, i.e., ensemble of pre-trained VLMs. We introduce three customized ensemble strategies, each tailored to one specific scenario. Firstly, we introduce the zero-shot ensemble, automatically adjusting the logits of different models based on their confidence when only pre-trained VLMs are available. Furthermore, for scenarios with extra few-shot samples, we propose the training-free and tuning ensemble, offering flexibility based on the availability of computing resources. The proposed ensemble strategies are evaluated on zero-shot, base-to-new, and cross-dataset generalization, achieving new state-of-the-art performance. Notably, this work represents an initial stride toward enhancing the generalization performance of VLMs via ensemble. The code is available at https://github.com/zhiheLu/Ensemble_VLM.git.
Typhoon Intensity Prediction with Vision Transformer
Nov 28, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
Multi-defender Security Games with Schedules
Nov 28, 2023Stackelberg Security Games are often used to model strategic interactions in high-stakes security settings. The majority of existing models focus on single-defender settings where a single entity assumes command of all security assets. However, many realistic scenarios feature multiple heterogeneous defenders with their own interests and priorities embedded in a more complex system. Furthermore, defenders rarely choose targets to protect. Instead, they have a multitude of defensive resources or schedules at its disposal, each with different protective capabilities. In this paper, we study security games featuring multiple defenders and schedules simultaneously. We show that unlike prior work on multi-defender security games, the introduction of schedules can cause non-existence of equilibrium even under rather restricted environments. We prove that under the mild restriction that any subset of a schedule is also a schedule, non-existence of equilibrium is not only avoided, but can be computed in polynomial time in games with two defenders. Under additional assumptions, our algorithm can be extended to games with more than two defenders and its computation scaled up in special classes of games with compactly represented schedules such as those used in patrolling applications. Experimental results suggest that our methods scale gracefully with game size, making our algorithms amongst the few that can tackle multiple heterogeneous defenders.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Nov 28, 2023Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the SfM points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency. To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians into a more efficient and compact format. Drawing inspiration from the concept of Network Pruning, LightGaussian identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a pruning and recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects. Additionally, LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower degree, allowing knowledge transfer to more compact representations while maintaining reflectance. Furthermore, we propose a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth representations with minimal accuracy losses. In summary, LightGaussian achieves an averaged compression rate over 15x while boosting the FPS from 139 to 215, enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank and Temple datasets. Project website: https://lightgaussian.github.io/
HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting
Nov 28, 2023Realistic 3D human generation from text prompts is a desirable yet challenging task. Existing methods optimize 3D representations like mesh or neural fields via score distillation sampling (SDS), which suffers from inadequate fine details or excessive training time. In this paper, we propose an efficient yet effective framework, HumanGaussian, that generates high-quality 3D humans with fine-grained geometry and realistic appearance. Our key insight is that 3D Gaussian Splatting is an efficient renderer with periodic Gaussian shrinkage or growing, where such adaptive density control can be naturally guided by intrinsic human structures. Specifically, 1) we first propose a Structure-Aware SDS that simultaneously optimizes human appearance and geometry. The multi-modal score function from both RGB and depth space is leveraged to distill the Gaussian densification and pruning process. 2) Moreover, we devise an Annealed Negative Prompt Guidance by decomposing SDS into a noisier generative score and a cleaner classifier score, which well addresses the over-saturation issue. The floating artifacts are further eliminated based on Gaussian size in a prune-only phase to enhance generation smoothness. Extensive experiments demonstrate the superior efficiency and competitive quality of our framework, rendering vivid 3D humans under diverse scenarios. Project Page: https://alvinliu0.github.io/projects/HumanGaussian