 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can LLMs get help from other LLMs without revealing private information?
Apr 02, 2024
Cascades are a common type of machine learning systems in which a large, remote model can be queried if a local model is not able to accurately label a user's data by itself. Serving stacks for large language models (LLMs) increasingly use cascades due to their ability to preserve task performance while dramatically reducing inference costs. However, applying cascade systems in situations where the local model has access to sensitive data constitutes a significant privacy risk for users since such data could be forwarded to the remote model. In this work, we show the feasibility of applying cascade systems in such setups by equipping the local model with privacy-preserving techniques that reduce the risk of leaking private information when querying the remote model. To quantify information leakage in such setups, we introduce two privacy measures. We then propose a system that leverages the recently introduced social learning paradigm in which LLMs collaboratively learn from each other by exchanging natural language. Using this paradigm, we demonstrate on several datasets that our methods minimize the privacy loss while at the same time improving task performance compared to a non-cascade baseline.
Large Language Models for Orchestrating Bimanual Robots
Apr 02, 2024Although there has been rapid progress in endowing robots with the ability to solve complex manipulation tasks, generating control policies for bimanual robots to solve tasks involving two hands is still challenging because of the difficulties in effective temporal and spatial coordination. With emergent abilities in terms of step-by-step reasoning and in-context learning, Large Language Models (LLMs) have taken control of a variety of robotic tasks. However, the nature of language communication via a single sequence of discrete symbols makes LLM-based coordination in continuous space a particular challenge for bimanual tasks. To tackle this challenge for the first time by an LLM, we present LAnguage-model-based Bimanual ORchestration (LABOR), an agent utilizing an LLM to analyze task configurations and devise coordination control policies for addressing long-horizon bimanual tasks. In the simulated environment, the LABOR agent is evaluated through several everyday tasks on the NICOL humanoid robot. Reported success rates indicate that overall coordination efficiency is close to optimal performance, while the analysis of failure causes, classified into spatial and temporal coordination and skill selection, shows that these vary over tasks. The project website can be found at http://labor-agent.github.io
The Solution for the CVPR 2023 1st foundation model challenge-Track2
Apr 02, 2024In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
Defense without Forgetting: Continual Adversarial Defense with Anisotropic & Isotropic Pseudo Replay
Apr 02, 2024Deep neural networks have demonstrated susceptibility to adversarial attacks. Adversarial defense techniques often focus on one-shot setting to maintain robustness against attack. However, new attacks can emerge in sequences in real-world deployment scenarios. As a result, it is crucial for a defense model to constantly adapt to new attacks, but the adaptation process can lead to catastrophic forgetting of previously defended against attacks. In this paper, we discuss for the first time the concept of continual adversarial defense under a sequence of attacks, and propose a lifelong defense baseline called Anisotropic \& Isotropic Replay (AIR), which offers three advantages: (1) Isotropic replay ensures model consistency in the neighborhood distribution of new data, indirectly aligning the output preference between old and new tasks. (2) Anisotropic replay enables the model to learn a compromise data manifold with fresh mixed semantics for further replay constraints and potential future attacks. (3) A straightforward regularizer mitigates the 'plasticity-stability' trade-off by aligning model output between new and old tasks. Experiment results demonstrate that AIR can approximate or even exceed the empirical performance upper bounds achieved by Joint Training.
Using Large Language Models to Understand Telecom Standards
Apr 02, 2024The Third Generation Partnership Project (3GPP) has successfully introduced standards for global mobility. However, the volume and complexity of these standards has increased over time, thus complicating access to relevant information for vendors and service providers. Use of Generative Artificial Intelligence (AI) and in particular Large Language Models (LLMs), may provide faster access to relevant information. In this paper, we evaluate the capability of state-of-art LLMs to be used as Question Answering (QA) assistants for 3GPP document reference. Our contribution is threefold. First, we provide a benchmark and measuring methods for evaluating performance of LLMs. Second, we do data preprocessing and fine-tuning for one of these LLMs and provide guidelines to increase accuracy of the responses that apply to all LLMs. Third, we provide a model of our own, TeleRoBERTa, that performs on-par with foundation LLMs but with an order of magnitude less number of parameters. Results show that LLMs can be used as a credible reference tool on telecom technical documents, and thus have potential for a number of different applications from troubleshooting and maintenance, to network operations and software product development.
Real-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024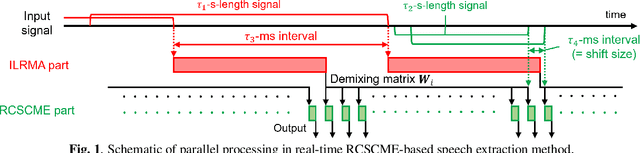
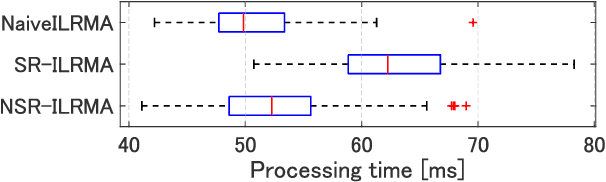
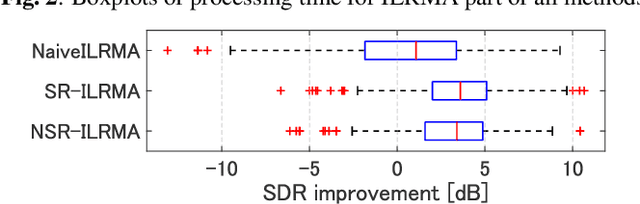
Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
CASPER: Causality-Aware Spatiotemporal Graph Neural Networks for Spatiotemporal Time Series Imputation
Mar 18, 2024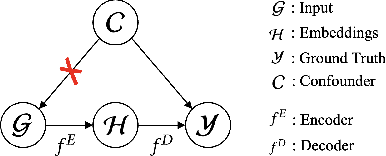
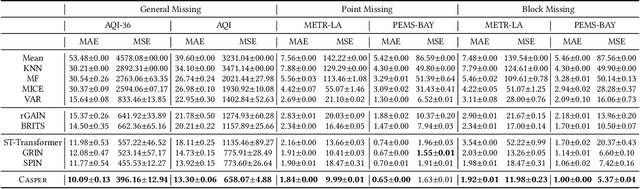
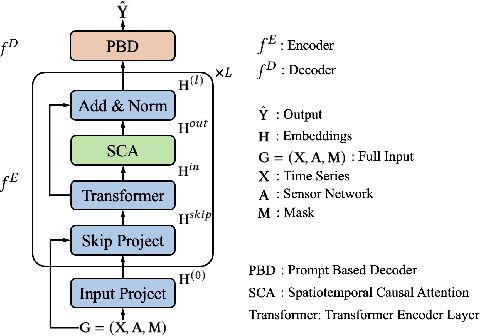
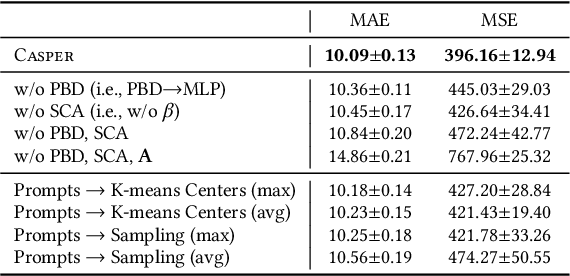
Spatiotemporal time series is the foundation of understanding human activities and their impacts, which is usually collected via monitoring sensors placed at different locations. The collected data usually contains missing values due to various failures, which have significant impact on data analysis. To impute the missing values, a lot of methods have been introduced. When recovering a specific data point, most existing methods tend to take into consideration all the information relevant to that point regardless of whether they have a cause-and-effect relationship. During data collection, it is inevitable that some unknown confounders are included, e.g., background noise in time series and non-causal shortcut edges in the constructed sensor network. These confounders could open backdoor paths between the input and output, in other words, they establish non-causal correlations between the input and output. Over-exploiting these non-causal correlations could result in overfitting and make the model vulnerable to noises. In this paper, we first revisit spatiotemporal time series imputation from a causal perspective, which shows the causal relationships among the input, output, embeddings and confounders. Next, we show how to block the confounders via the frontdoor adjustment. Based on the results of the frontdoor adjustment, we introduce a novel Causality-Aware SPatiotEmpoRal graph neural network (CASPER), which contains a novel Spatiotemporal Causal Attention (SCA) and a Prompt Based Decoder (PBD). PBD could reduce the impact of confounders and SCA could discover the sparse causal relationships among embeddings. Theoretical analysis reveals that SCA discovers causal relationships based on the values of gradients. We evaluate Casper on three real-world datasets, and the experimental results show that Casper outperforms the baselines and effectively discovers causal relationships.
Diffusion-TS: Interpretable Diffusion for General Time Series Generation
Mar 14, 2024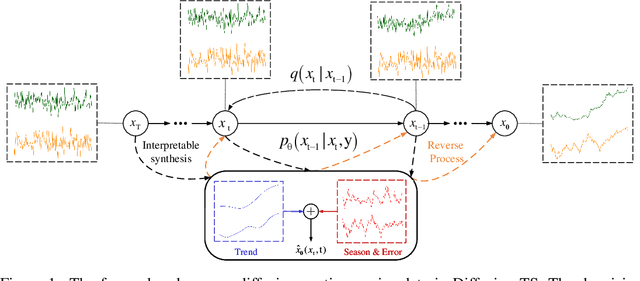
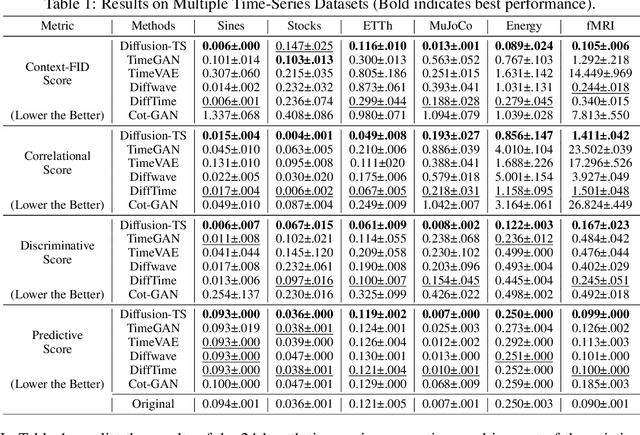
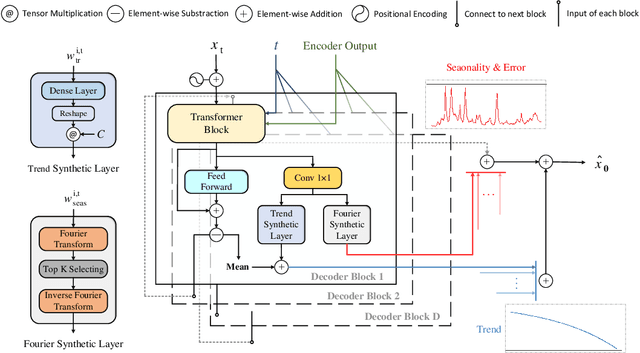
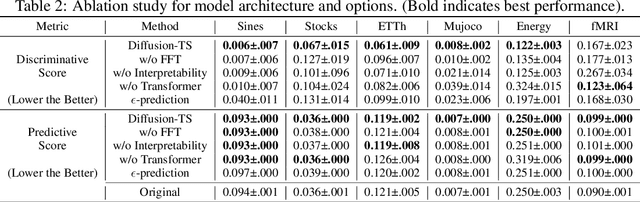
Denoising diffusion probabilistic models (DDPMs) are becoming the leading paradigm for generative models. It has recently shown breakthroughs in audio synthesis, time series imputation and forecasting. In this paper, we propose Diffusion-TS, a novel diffusion-based framework that generates multivariate time series samples of high quality by using an encoder-decoder transformer with disentangled temporal representations, in which the decomposition technique guides Diffusion-TS to capture the semantic meaning of time series while transformers mine detailed sequential information from the noisy model input. Different from existing diffusion-based approaches, we train the model to directly reconstruct the sample instead of the noise in each diffusion step, combining a Fourier-based loss term. Diffusion-TS is expected to generate time series satisfying both interpretablity and realness. In addition, it is shown that the proposed Diffusion-TS can be easily extended to conditional generation tasks, such as forecasting and imputation, without any model changes. This also motivates us to further explore the performance of Diffusion-TS under irregular settings. Finally, through qualitative and quantitative experiments, results show that Diffusion-TS achieves the state-of-the-art results on various realistic analyses of time series.
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
Apr 02, 2024The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.