 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Animation Generation and Control on Rigged Models via Large Language Models
Oct 27, 2023




We introduce a novel method for real-time animation control and generation on rigged models using natural language input. First, we embed a large language model (LLM) in Unity to output structured texts that can be parsed into diverse and realistic animations. Second, we illustrate LLM's potential to enable flexible state transition between existing animations. We showcase the robustness of our approach through qualitative results on various rigged models and motions.
Personalized Predictions of Glioblastoma Infiltration: Mathematical Models, Physics-Informed Neural Networks and Multimodal Scans
Nov 28, 2023Predicting the infiltration of Glioblastoma (GBM) from medical MRI scans is crucial for understanding tumor growth dynamics and designing personalized radiotherapy treatment plans.Mathematical models of GBM growth can complement the data in the prediction of spatial distributions of tumor cells. However, this requires estimating patient-specific parameters of the model from clinical data, which is a challenging inverse problem due to limited temporal data and the limited time between imaging and diagnosis. This work proposes a method that uses Physics-Informed Neural Networks (PINNs) to estimate patient-specific parameters of a reaction-diffusion PDE model of GBM growth from a single 3D structural MRI snapshot. PINNs embed both the data and the PDE into a loss function, thus integrating theory and data. Key innovations include the identification and estimation of characteristic non-dimensional parameters, a pre-training step that utilizes the non-dimensional parameters and a fine-tuning step to determine the patient specific parameters. Additionally, the diffuse domain method is employed to handle the complex brain geometry within the PINN framework. Our method is validated both on synthetic and patient datasets, and shows promise for real-time parametric inference in the clinical setting for personalized GBM treatment.
UE4-NeRF:Neural Radiance Field for Real-Time Rendering of Large-Scale Scene
Oct 20, 2023Neural Radiance Fields (NeRF) is a novel implicit 3D reconstruction method that shows immense potential and has been gaining increasing attention. It enables the reconstruction of 3D scenes solely from a set of photographs. However, its real-time rendering capability, especially for interactive real-time rendering of large-scale scenes, still has significant limitations. To address these challenges, in this paper, we propose a novel neural rendering system called UE4-NeRF, specifically designed for real-time rendering of large-scale scenes. We partitioned each large scene into different sub-NeRFs. In order to represent the partitioned independent scene, we initialize polygonal meshes by constructing multiple regular octahedra within the scene and the vertices of the polygonal faces are continuously optimized during the training process. Drawing inspiration from Level of Detail (LOD) techniques, we trained meshes of varying levels of detail for different observation levels. Our approach combines with the rasterization pipeline in Unreal Engine 4 (UE4), achieving real-time rendering of large-scale scenes at 4K resolution with a frame rate of up to 43 FPS. Rendering within UE4 also facilitates scene editing in subsequent stages. Furthermore, through experiments, we have demonstrated that our method achieves rendering quality comparable to state-of-the-art approaches. Project page: https://jamchaos.github.io/UE4-NeRF/.
Foundation Models for Weather and Climate Data Understanding: A Comprehensive Survey
Dec 05, 2023As artificial intelligence (AI) continues to rapidly evolve, the realm of Earth and atmospheric sciences is increasingly adopting data-driven models, powered by progressive developments in deep learning (DL). Specifically, DL techniques are extensively utilized to decode the chaotic and nonlinear aspects of Earth systems, and to address climate challenges via understanding weather and climate data. Cutting-edge performance on specific tasks within narrower spatio-temporal scales has been achieved recently through DL. The rise of large models, specifically large language models (LLMs), has enabled fine-tuning processes that yield remarkable outcomes across various downstream tasks, thereby propelling the advancement of general AI. However, we are still navigating the initial stages of crafting general AI for weather and climate. In this survey, we offer an exhaustive, timely overview of state-of-the-art AI methodologies specifically engineered for weather and climate data, with a special focus on time series and text data. Our primary coverage encompasses four critical aspects: types of weather and climate data, principal model architectures, model scopes and applications, and datasets for weather and climate. Furthermore, in relation to the creation and application of foundation models for weather and climate data understanding, we delve into the field's prevailing challenges, offer crucial insights, and propose detailed avenues for future research. This comprehensive approach equips practitioners with the requisite knowledge to make substantial progress in this domain. Our survey encapsulates the most recent breakthroughs in research on large, data-driven models for weather and climate data understanding, emphasizing robust foundations, current advancements, practical applications, crucial resources, and prospective research opportunities.
DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance
Dec 05, 2023Image-to-video generation, which aims to generate a video starting from a given reference image, has drawn great attention. Existing methods try to extend pre-trained text-guided image diffusion models to image-guided video generation models. Nevertheless, these methods often result in either low fidelity or flickering over time due to their limitation to shallow image guidance and poor temporal consistency. To tackle these problems, we propose a high-fidelity image-to-video generation method by devising a frame retention branch on the basis of a pre-trained video diffusion model, named DreamVideo. Instead of integrating the reference image into the diffusion process in a semantic level, our DreamVideo perceives the reference image via convolution layers and concatenate the features with the noisy latents as model input. By this means, the details of the reference image can be preserved to the greatest extent. In addition, by incorporating double-condition classifier-free guidance, a single image can be directed to videos of different actions by providing varying prompt texts. This has significant implications for controllable video generation and holds broad application prospects. We conduct comprehensive experiments on the public dataset, both quantitative and qualitative results indicate that our method outperforms the state-of-the-art method. Especially for fidelity, our model has powerful image retention ability and result in high FVD in UCF101 compared to other image-to-video models. Also, precise control can be achieved by giving different text prompts. Further details and comprehensive results of our model will be presented in https://anonymous0769.github.io/DreamVideo/.
Machine Learning Driven Sensitivity Analysis of E3SM Land Model Parameters for Wetland Methane Emissions
Dec 05, 2023Methane (CH4) is the second most critical greenhouse gas after carbon dioxide, contributing to 16-25% of the observed atmospheric warming. Wetlands are the primary natural source of methane emissions globally. However, wetland methane emission estimates from biogeochemistry models contain considerable uncertainty. One of the main sources of this uncertainty arises from the numerous uncertain model parameters within various physical, biological, and chemical processes that influence methane production, oxidation, and transport. Sensitivity Analysis (SA) can help identify critical parameters for methane emission and achieve reduced biases and uncertainties in future projections. This study performs SA for 19 selected parameters responsible for critical biogeochemical processes in the methane module of the Energy Exascale Earth System Model (E3SM) land model (ELM). The impact of these parameters on various CH4 fluxes is examined at 14 FLUXNET- CH4 sites with diverse vegetation types. Given the extensive number of model simulations needed for global variance-based SA, we employ a machine learning (ML) algorithm to emulate the complex behavior of ELM methane biogeochemistry. ML enables the computational time to be shortened significantly from 6 CPU hours to 0.72 milliseconds, achieving reduced computational costs. We found that parameters linked to CH4 production and diffusion generally present the highest sensitivities despite apparent seasonal variation. Comparing simulated emissions from perturbed parameter sets against FLUXNET-CH4 observations revealed that better performances can be achieved at each site compared to the default parameter values. This presents a scope for further improving simulated emissions using parameter calibration with advanced optimization techniques like Bayesian optimization.
Robust UAV Position and Attitude Estimation using Multiple GNSS Receivers for Laser-based 3D Mapping
Dec 05, 2023Small-sized unmanned aerial vehicles (UAVs) have been widely investigated for use in a variety of applications such as remote sensing and aerial surveying. Direct three-dimensional (3D) mapping using a small-sized UAV equipped with a laser scanner is required for numerous remote sensing applications. In direct 3D mapping, the precise information about the position and attitude of the UAV is necessary for constructing 3D maps. In this study, we propose a novel and robust technique for estimating the position and attitude of small-sized UAVs by employing multiple low-cost and light-weight global navigation satellite system (GNSS) antennas/receivers. Using the "redundancy" of multiple GNSS receivers, we enhance the performance of real-time kinematic (RTK)-GNSS by employing single-frequency GNSS receivers. This method consists of two approaches: hybrid GNSS fix solutions and consistency examination of the GNSS signal strength. The fix rate of RTK-GNSS using single-frequency GNSS receivers can be highly enhanced to combine multiple RTK-GNSS to fix solutions in the multiple antennas. In addition, positioning accuracy and fix rate can be further enhanced to detect multipath signals by using multiple GNSS antennas. In this study, we developed a prototype UAV that is equipped with six GNSS antennas/receivers. From the static test results, we conclude that the proposed technique can enhance the accuracy of the position and attitude estimation in multipath environments. From the flight test, the proposed system could generate a 3D map with an accuracy of 5 cm.
* Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2019
Air-Decoding: Attribute Distribution Reconstruction for Decoding-Time Controllable Text Generation
Oct 23, 2023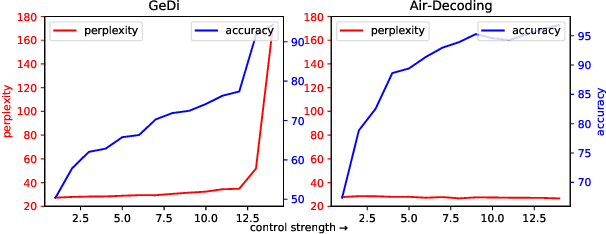
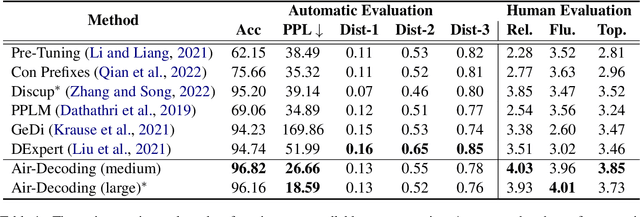
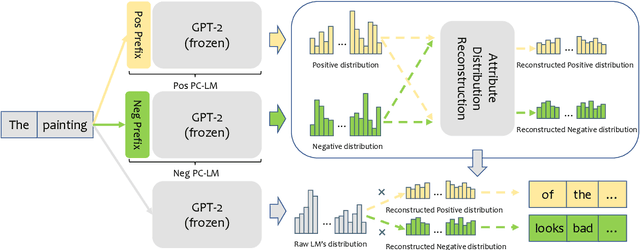
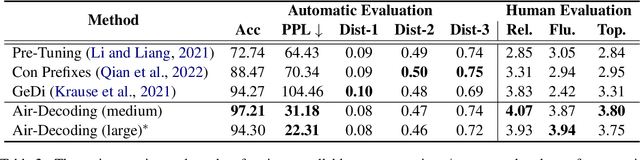
Controllable text generation (CTG) aims to generate text with desired attributes, and decoding-time-based methods have shown promising performance on this task. However, in this paper, we identify the phenomenon of Attribute Collapse for the first time. It causes the fluency of generated text to rapidly decrease when the control strength exceeds a critical value, rendering the text completely unusable. This limitation hinders the effectiveness of decoding methods in achieving high levels of controllability. To address this problem, we propose a novel lightweight decoding framework named Air-Decoding. Its main idea is reconstructing the attribute distributions to balance the weights between attribute words and non-attribute words to generate more fluent text. Specifically, we train prefixes by prefix-tuning to obtain attribute distributions. Then we design a novel attribute distribution reconstruction method to balance the obtained distributions and use the reconstructed distributions to guide language models for generation, effectively avoiding the issue of Attribute Collapse. Experiments on multiple CTG tasks prove that our method achieves a new state-of-the-art control performance.
Pose Estimation and Tracking for ASIST
Nov 30, 2023Aircraft Ship Integrated Secure and Traverse (ASIST) is a system designed to arrest helicopters safely and efficiently on ships. Originally, a precision Helicopter Position Sensing Equipment (HPSE) tracked and monitored the position of the helicopter relative to the Rapid Securing Device (RSD). However, using the HPSE component was determined to be infeasible in the transition of the ASIST system due to the hardware installation requirements. As a result, sailors track the position of the helicopters with their eyes with no sensor or artificially intelligent decision aid. Manually tracking the helicopter takes additional time and makes recoveries more difficult, especially at high sea states. Performing recoveries without the decision aid leads to higher uncertainty and cognitive load. PETA (Pose Estimation and Tracking for ASIST) is a research effort to create a helicopter tracking system prototype without hardware installation requirements for ASIST system operators. Its overall goal is to improve situational awareness and reduce operator uncertainty with respect to the aircrafts position relative to the RSD, and consequently increase the allowable landing area. The authors produced a prototype system capable of tracking helicopters with respect to the RSD. The software included a helicopter pose estimation component, camera pose estimation component, and a user interface component. PETA demonstrated the potential for state-of-the-art computer vision algorithms Faster R-CNN and HRNet (High-Resolution Network) to be used to estimate the pose of helicopters in real-time, returning ASIST to its originally intended capability. PETA also demonstrated that traditional methods of encoder-decoders could be used to estimate the orientation of the helicopter and could be used to confirm the output from HRNet.
The Stochastic Dynamic Post-Disaster Inventory Allocation Problem with Trucks and UAVs
Nov 30, 2023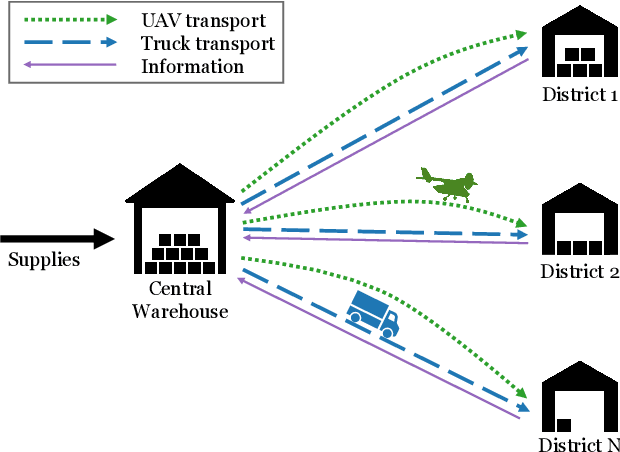
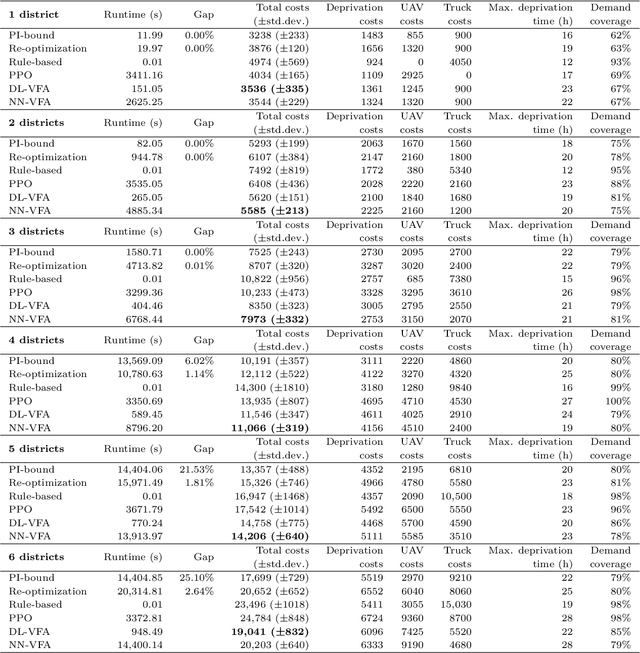
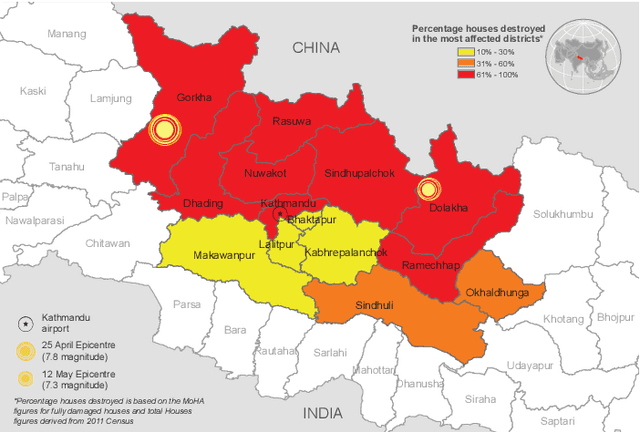
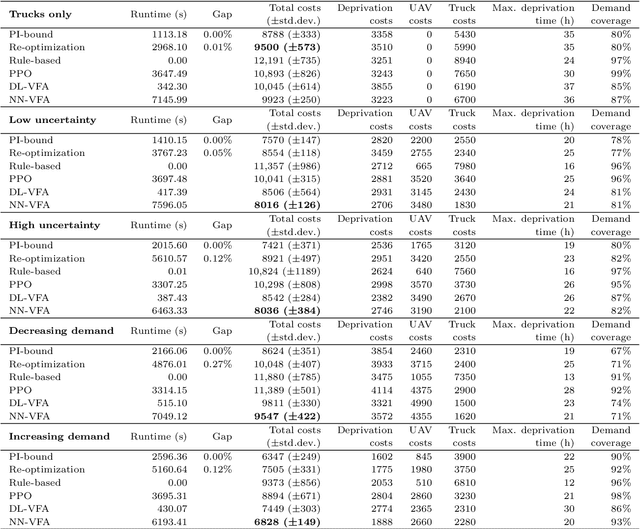
Humanitarian logistics operations face increasing difficulties due to rising demands for aid in disaster areas. This paper investigates the dynamic allocation of scarce relief supplies across multiple affected districts over time. It introduces a novel stochastic dynamic post-disaster inventory allocation problem with trucks and unmanned aerial vehicles delivering relief goods under uncertain supply and demand. The relevance of this humanitarian logistics problem lies in the importance of considering the inter-temporal social impact of deliveries. We achieve this by incorporating deprivation costs when allocating scarce supplies. Furthermore, we consider the inherent uncertainties of disaster areas and the potential use of cargo UAVs to enhance operational efficiency. This study proposes two anticipatory solution methods based on approximate dynamic programming, specifically decomposed linear value function approximation and neural network value function approximation to effectively manage uncertainties in the dynamic allocation process. We compare DL-VFA and NN-VFA with various state-of-the-art methods (exact re-optimization, PPO) and results show a 6-8% improvement compared to the best benchmarks. NN-VFA provides the best performance and captures nonlinearities in the problem, whereas DL-VFA shows excellent scalability against a minor performance loss. The experiments reveal that consideration of deprivation costs results in improved allocation of scarce supplies both across affected districts and over time. Finally, results show that deploying UAVs can play a crucial role in the allocation of relief goods, especially in the first stages after a disaster. The use of UAVs reduces transportation- and deprivation costs together by 16-20% and reduces maximum deprivation times by 19-40%, while maintaining similar levels of demand coverage, showcasing efficient and effective operations.