 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Nov 30, 2023
Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal language models, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
Oct 16, 2023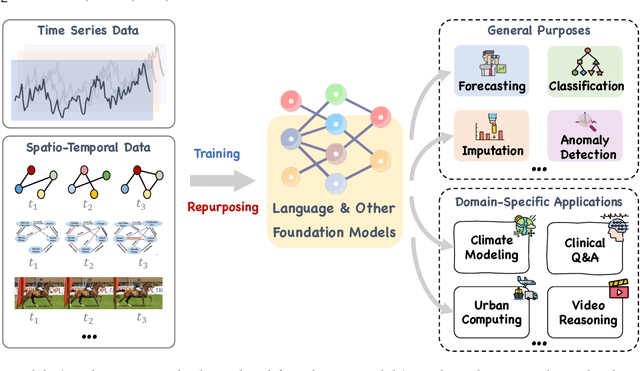
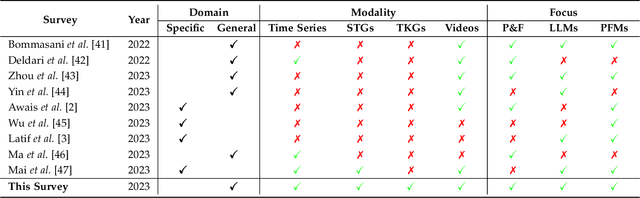
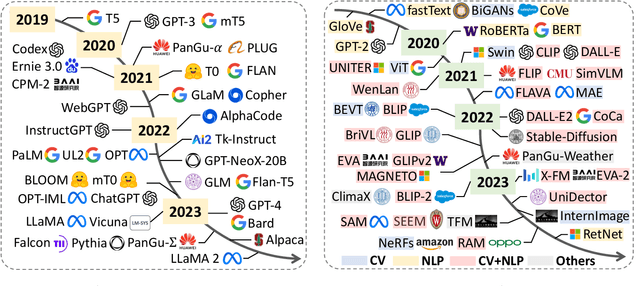
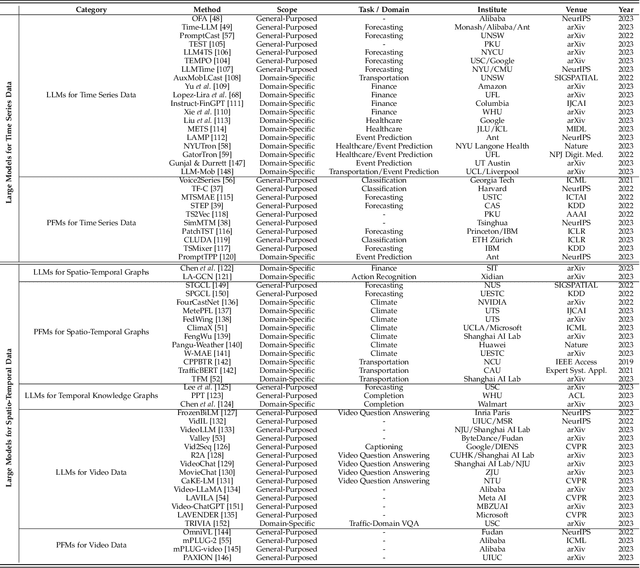
Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.
Operator Learning for Continuous Spatial-Temporal Model with A Hybrid Optimization Scheme
Nov 20, 2023Partial differential equations are often used in the spatial-temporal modeling of complex dynamical systems in many engineering applications. In this work, we build on the recent progress of operator learning and present a data-driven modeling framework that is continuous in both space and time. A key feature of the proposed model is the resolution-invariance with respect to both spatial and temporal discretizations. To improve the long-term performance of the calibrated model, we further propose a hybrid optimization scheme that leverages both gradient-based and derivative-free optimization methods and efficiently trains on both short-term time series and long-term statistics. We investigate the performance of the spatial-temporal continuous learning framework with three numerical examples, including the viscous Burgers' equation, the Navier-Stokes equations, and the Kuramoto-Sivashinsky equation. The results confirm the resolution-invariance of the proposed modeling framework and also demonstrate stable long-term simulations with only short-term time series data. In addition, we show that the proposed model can better predict long-term statistics via the hybrid optimization scheme with a combined use of short-term and long-term data.
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams
Oct 16, 2023Test-time adaptation (TTA) aims to address distributional shifts between training and testing data using only unlabeled test data streams for continual model adaptation. However, most TTA methods assume benign test streams, while test samples could be unexpectedly diverse in the wild. For instance, an unseen object or noise could appear in autonomous driving. This leads to a new threat to existing TTA algorithms; we found that prior TTA algorithms suffer from those noisy test samples as they blindly adapt to incoming samples. To address this problem, we present Screening-out Test-Time Adaptation (SoTTA), a novel TTA algorithm that is robust to noisy samples. The key enabler of SoTTA is two-fold: (i) input-wise robustness via high-confidence uniform-class sampling that effectively filters out the impact of noisy samples and (ii) parameter-wise robustness via entropy-sharpness minimization that improves the robustness of model parameters against large gradients from noisy samples. Our evaluation with standard TTA benchmarks with various noisy scenarios shows that our method outperforms state-of-the-art TTA methods under the presence of noisy samples and achieves comparable accuracy to those methods without noisy samples. The source code is available at https://github.com/taeckyung/SoTTA .
Error Performance of Coded AFDM Systems in Doubly Selective Channels
Nov 27, 2023Affine frequency division multiplexing (AFDM) is a strong candidate for the sixth-generation wireless network thanks to its strong resilience to delay-Doppler spreads. In this letter, we investigate the error performance of coded AFDM systems in doubly selective channels. We first study the conditional pairwise-error probability (PEP) of AFDM system and derive its conditional coding gain. Then, we show that there is a fundamental trade-off between the diversity gain and the coding gain of AFDM system, namely the coding gain declines with a descending speed with respect to the number of separable paths, while the diversity gain increases linearly. Moreover, we propose a near-optimal turbo decoder based on the sum-product algorithm for coded AFDM systems to improve its error performance. Simulation results verify our analyses and the effectiveness of the proposed turbo decoder, showing that AFDM outperforms orthogonal frequency division multiplexing (OFDM) and orthogonal time frequency space (OTFS) in both coded and uncoded cases over high-mobility channels.
Streaming Lossless Volumetric Compression of Medical Images Using Gated Recurrent Convolutional Neural Network
Nov 27, 2023Deep learning-based lossless compression methods offer substantial advantages in compressing medical volumetric images. Nevertheless, many learning-based algorithms encounter a trade-off between practicality and compression performance. This paper introduces a hardware-friendly streaming lossless volumetric compression framework, utilizing merely one-thousandth of the model weights compared to other learning-based compression frameworks. We propose a gated recurrent convolutional neural network that combines diverse convolutional structures and fusion gate mechanisms to capture the inter-slice dependencies in volumetric images. Based on such contextual information, we can predict the pixel-by-pixel distribution for entropy coding. Guided by hardware/software co-design principles, we implement the proposed framework on Field Programmable Gate Array to achieve enhanced real-time performance. Extensive experimental results indicate that our method outperforms traditional lossless volumetric compressors and state-of-the-art learning-based lossless compression methods across various medical image benchmarks. Additionally, our method exhibits robust generalization ability and competitive compression speed
Quantum-classical simulation of quantum field theory by quantum circuit learning
Nov 27, 2023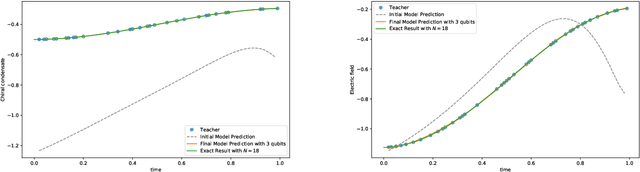
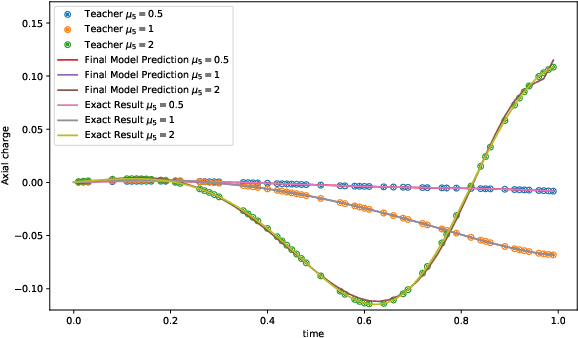
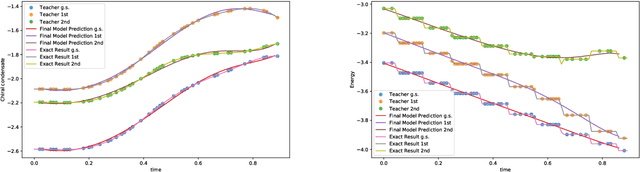
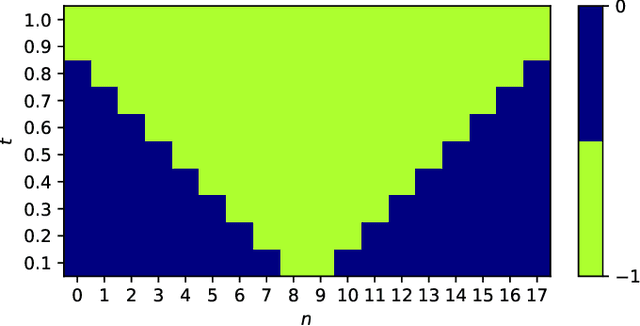
We employ quantum circuit learning to simulate quantum field theories (QFTs). Typically, when simulating QFTs with quantum computers, we encounter significant challenges due to the technical limitations of quantum devices when implementing the Hamiltonian using Pauli spin matrices. To address this challenge, we leverage quantum circuit learning, employing a compact configuration of qubits and low-depth quantum circuits to predict real-time dynamics in quantum field theories. The key advantage of this approach is that a single-qubit measurement can accurately forecast various physical parameters, including fully-connected operators. To demonstrate the effectiveness of our method, we use it to predict quench dynamics, chiral dynamics and jet production in a 1+1-dimensional model of quantum electrodynamics. We find that our predictions closely align with the results of rigorous classical calculations, exhibiting a high degree of accuracy. This hybrid quantum-classical approach illustrates the feasibility of efficiently simulating large-scale QFTs on cutting-edge quantum devices.
PatchBMI-Net: Lightweight Facial Patch-based Ensemble for BMI Prediction
Nov 29, 2023Due to an alarming trend related to obesity affecting 93.3 million adults in the United States alone, body mass index (BMI) and body weight have drawn significant interest in various health monitoring applications. Consequently, several studies have proposed self-diagnostic facial image-based BMI prediction methods for healthy weight monitoring. These methods have mostly used convolutional neural network (CNN) based regression baselines, such as VGG19, ResNet50, and Efficient-NetB0, for BMI prediction from facial images. However, the high computational requirement of these heavy-weight CNN models limits their deployment to resource-constrained mobile devices, thus deterring weight monitoring using smartphones. This paper aims to develop a lightweight facial patch-based ensemble (PatchBMI-Net) for BMI prediction to facilitate the deployment and weight monitoring using smartphones. Extensive experiments on BMI-annotated facial image datasets suggest that our proposed PatchBMI-Net model can obtain Mean Absolute Error (MAE) in the range [3.58, 6.51] with a size of about 3.3 million parameters. On cross-comparison with heavyweight models, such as ResNet-50 and Xception, trained for BMI prediction from facial images, our proposed PatchBMI-Net obtains equivalent MAE along with the model size reduction of about 5.4x and the average inference time reduction of about 3x when deployed on Apple-14 smartphone. Thus, demonstrating performance efficiency as well as low latency for on-device deployment and weight monitoring using smartphone applications.
Guided Prompting in SAM for Weakly Supervised Cell Segmentation in Histopathological Images
Nov 29, 2023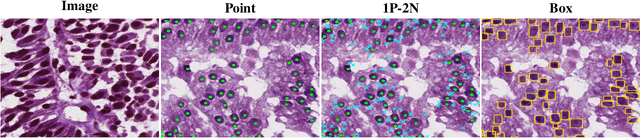
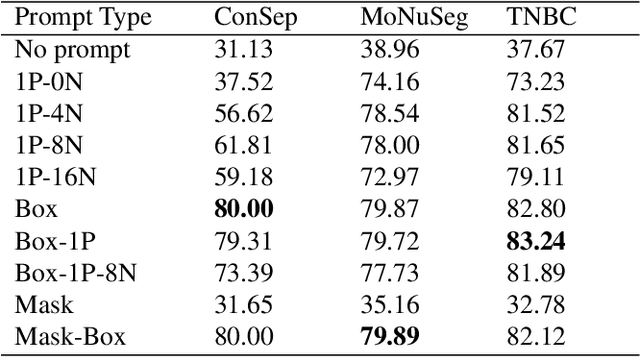
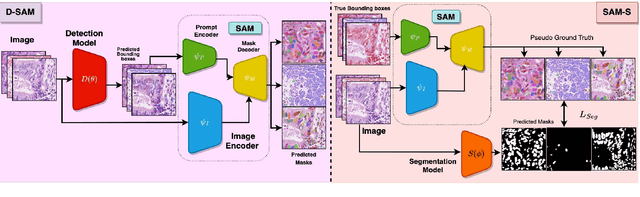
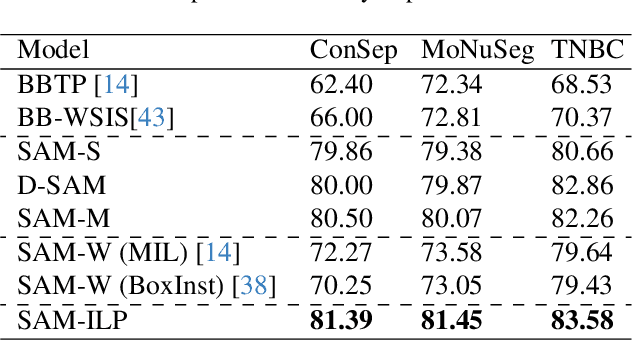
Cell segmentation in histopathological images plays a crucial role in understanding, diagnosing, and treating many diseases. However, data annotation for this is expensive since there can be a large number of cells per image, and expert pathologists are needed for labelling images. Instead, our paper focuses on using weak supervision -- annotation from related tasks -- to induce a segmenter. Recent foundation models, such as Segment Anything (SAM), can use prompts to leverage additional supervision during inference. SAM has performed remarkably well in natural image segmentation tasks; however, its applicability to cell segmentation has not been explored. In response, we investigate guiding the prompting procedure in SAM for weakly supervised cell segmentation when only bounding box supervision is available. We develop two workflows: (1) an object detector's output as a test-time prompt to SAM (D-SAM), and (2) SAM as pseudo mask generator over training data to train a standalone segmentation model (SAM-S). On finding that both workflows have some complementary strengths, we develop an integer programming-based approach to reconcile the two sets of segmentation masks, achieving yet higher performance. We experiment on three publicly available cell segmentation datasets namely, ConSep, MoNuSeg, and TNBC, and find that all SAM-based solutions hugely outperform existing weakly supervised image segmentation models, obtaining 9-15 pt Dice gains.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.