 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
8+8=4: Formalizing Time Units to Handle Symbolic Music Durations
Oct 23, 2023
This paper focuses on the nominal durations of musical events (notes and rests) in a symbolic musical score, and on how to conveniently handle these in computer applications. We propose the usage of a temporal unit that is directly related to the graphical symbols in musical scores and pair this with a set of operations that cover typical computations in music applications. We formalize this time unit and the more commonly used approach in a single mathematical framework, as semirings, algebraic structures that enable an abstract description of algorithms/processing pipelines. We then discuss some practical use cases and highlight when our system can improve such pipelines by making them more efficient in terms of data type used and the number of computations.
Fast and Reliable Generation of EHR Time Series via Diffusion Models
Oct 23, 2023Electronic Health Records (EHRs) are rich sources of patient-level data, including laboratory tests, medications, and diagnoses, offering valuable resources for medical data analysis. However, concerns about privacy often restrict access to EHRs, hindering downstream analysis. Researchers have explored various methods for generating privacy-preserving EHR data. In this study, we introduce a new method for generating diverse and realistic synthetic EHR time series data using Denoising Diffusion Probabilistic Models (DDPM). We conducted experiments on six datasets, comparing our proposed method with seven existing methods. Our results demonstrate that our approach significantly outperforms all existing methods in terms of data utility while requiring less training effort. Our approach also enhances downstream medical data analysis by providing diverse and realistic synthetic EHR data.
Using Learnable Physics for Real-Time Exercise Form Recommendations
Oct 11, 2023Good posture and form are essential for safe and productive exercising. Even in gym settings, trainers may not be readily available for feedback. Rehabilitation therapies and fitness workouts can thus benefit from recommender systems that provide real-time evaluation. In this paper, we present an algorithmic pipeline that can diagnose problems in exercise techniques and offer corrective recommendations, with high sensitivity and specificity in real-time. We use MediaPipe for pose recognition, count repetitions using peak-prominence detection, and use a learnable physics simulator to track motion evolution for each exercise. A test video is diagnosed based on deviations from the prototypical learned motion using statistical learning. The system is evaluated on six full and upper body exercises. These real-time recommendations, counseled via low-cost equipment like smartphones, will allow exercisers to rectify potential mistakes making self-practice feasible while reducing the risk of workout injuries.
* Accepted by ACM RecSys '23, 12 pages , 7 Figures
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
Oct 15, 2023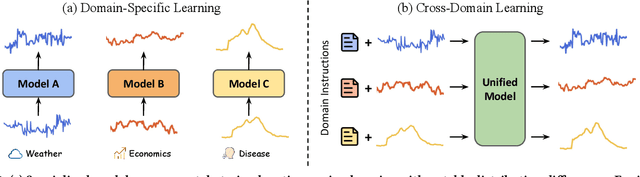
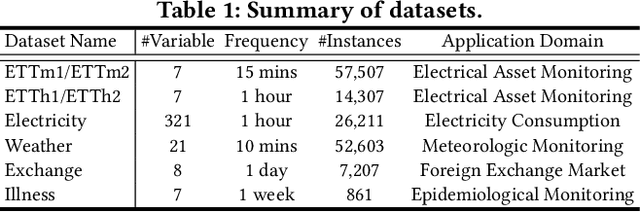
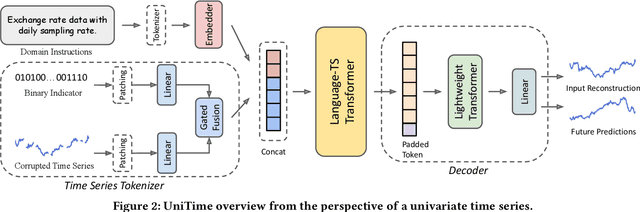
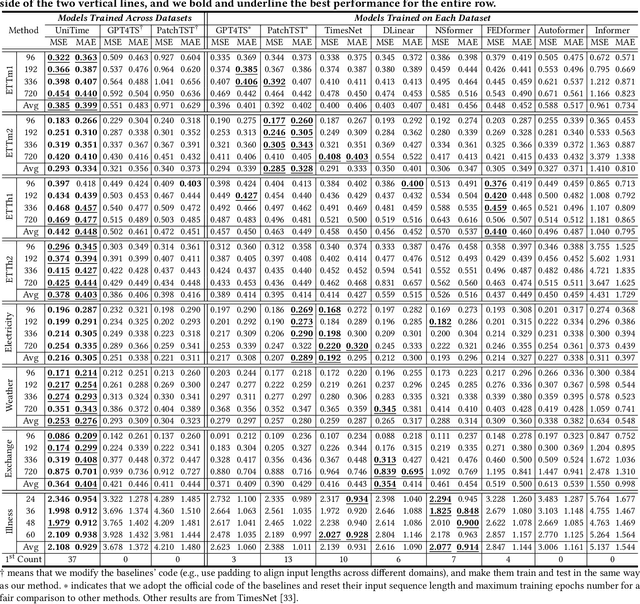
Multivariate time series forecasting plays a pivotal role in contemporary web technologies. In contrast to conventional methods that involve creating dedicated models for specific time series application domains, this research advocates for a unified model paradigm that transcends domain boundaries. However, learning an effective cross-domain model presents the following challenges. First, various domains exhibit disparities in data characteristics, e.g., the number of variables, posing hurdles for existing models that impose inflexible constraints on these factors. Second, the model may encounter difficulties in distinguishing data from various domains, leading to suboptimal performance in our assessments. Third, the diverse convergence rates of time series domains can also result in compromised empirical performance. To address these issues, we propose UniTime for effective cross-domain time series learning. Concretely, UniTime can flexibly adapt to data with varying characteristics. It also uses domain instructions and a Language-TS Transformer to offer identification information and align two modalities. In addition, UniTime employs masking to alleviate domain convergence speed imbalance issues. Our extensive experiments demonstrate the effectiveness of UniTime in advancing state-of-the-art forecasting performance and zero-shot transferability.
Continual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Nov 30, 2023Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.
Guided Demonstrations Using Automated Excuse Generation
Nov 30, 2023Teaching task-level directives to robots via demonstration is a popular tool to expand the robot's capabilities to interact with its environment. While current learning from demonstration systems primarily focuses on abstracting the task-level knowledge to the robot, these systems lack the ability to understand which part of the task can be already solved given the robot's prior knowledge. Therefore, instead of only requiring demonstrations of the missing pieces, these systems will require a demonstration of the complete task, which is cumbersome, repetitive, and can discourage people from helping the robot by performing the demonstrations. Therefore, we propose to use the notion of "excuses" to identify the smallest change in the robot state that makes a task, currently not solvable by the robot, solvable -- as a means to solicit more targeted demonstrations from a human. These excuses are generated automatically using combinatorial search over possible changes that can be made to the robot's state and choosing the minimum changes that make it solvable. These excuses then serve as guidance for the demonstrator who can use it to decide what to demonstrate to the robot in order to make this requested change possible, thereby making the original task solvable for the robot without having to demonstrate it in its entirety. By working with symbolic state descriptions, the excuses can be directly communicated and intuitively understood by a human demonstrator. We show empirically and in a user study that the use of excuses reduces the demonstration time by 54% and leads to a 74% reduction in demonstration size.
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Nov 30, 2023Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal language models, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
MINTY: Rule-based Models that Minimize the Need for Imputing Features with Missing Values
Nov 23, 2023Rule models are often preferred in prediction tasks with tabular inputs as they can be easily interpreted using natural language and provide predictive performance on par with more complex models. However, most rule models' predictions are undefined or ambiguous when some inputs are missing, forcing users to rely on statistical imputation models or heuristics like zero imputation, undermining the interpretability of the models. In this work, we propose fitting concise yet precise rule models that learn to avoid relying on features with missing values and, therefore, limit their reliance on imputation at test time. We develop MINTY, a method that learns rules in the form of disjunctions between variables that act as replacements for each other when one or more is missing. This results in a sparse linear rule model, regularized to have small dependence on features with missing values, that allows a trade-off between goodness of fit, interpretability, and robustness to missing values at test time. We demonstrate the value of MINTY in experiments using synthetic and real-world data sets and find its predictive performance comparable or favorable to baselines, with smaller reliance on features with missing values.
Tube-NeRF: Efficient Imitation Learning of Visuomotor Policies from MPC using Tube-Guided Data Augmentation and NeRFs
Nov 23, 2023Imitation learning (IL) can train computationally-efficient sensorimotor policies from a resource-intensive Model Predictive Controller (MPC), but it often requires many samples, leading to long training times or limited robustness. To address these issues, we combine IL with a variant of robust MPC that accounts for process and sensing uncertainties, and we design a data augmentation (DA) strategy that enables efficient learning of vision-based policies. The proposed DA method, named Tube-NeRF, leverages Neural Radiance Fields (NeRFs) to generate novel synthetic images, and uses properties of the robust MPC (the tube) to select relevant views and to efficiently compute the corresponding actions. We tailor our approach to the task of localization and trajectory tracking on a multirotor, by learning a visuomotor policy that generates control actions using images from the onboard camera as only source of horizontal position. Our evaluations numerically demonstrate learning of a robust visuomotor policy with an 80-fold increase in demonstration efficiency and a 50% reduction in training time over current IL methods. Additionally, our policies successfully transfer to a real multirotor, achieving accurate localization and low tracking errors despite large disturbances, with an onboard inference time of only 1.5 ms.
Optimal Power Flow in Highly Renewable Power System Based on Attention Neural Networks
Nov 23, 2023The Optimal Power Flow (OPF) problem is pivotal for power system operations, guiding generator output and power distribution to meet demand at minimized costs, while adhering to physical and engineering constraints. The integration of renewable energy sources, like wind and solar, however, poses challenges due to their inherent variability. This variability, driven largely by changing weather conditions, demands frequent recalibrations of power settings, thus necessitating recurrent OPF resolutions. This task is daunting using traditional numerical methods, particularly for extensive power systems. In this work, we present a cutting-edge, physics-informed machine learning methodology, trained using imitation learning and historical European weather datasets. Our approach directly correlates electricity demand and weather patterns with power dispatch and generation, circumventing the iterative requirements of traditional OPF solvers. This offers a more expedient solution apt for real-time applications. Rigorous evaluations on aggregated European power systems validate our method's superiority over existing data-driven techniques in OPF solving. By presenting a quick, robust, and efficient solution, this research sets a new standard in real-time OPF resolution, paving the way for more resilient power systems in the era of renewable energy.