 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Manipulating the Label Space for In-Context Classification
Dec 06, 2023
After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
MMM: Generative Masked Motion Model
Dec 06, 2023Recent advances in text-to-motion generation using diffusion and autoregressive models have shown promising results. However, these models often suffer from a trade-off between real-time performance, high fidelity, and motion editability. To address this gap, we introduce MMM, a novel yet simple motion generation paradigm based on Masked Motion Model. MMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into a sequence of discrete tokens in latent space, and (2) a conditional masked motion transformer that learns to predict randomly masked motion tokens, conditioned on the pre-computed text tokens. By attending to motion and text tokens in all directions, MMM explicitly captures inherent dependency among motion tokens and semantic mapping between motion and text tokens. During inference, this allows parallel and iterative decoding of multiple motion tokens that are highly consistent with fine-grained text descriptions, therefore simultaneously achieving high-fidelity and high-speed motion generation. In addition, MMM has innate motion editability. By simply placing mask tokens in the place that needs editing, MMM automatically fills the gaps while guaranteeing smooth transitions between editing and non-editing parts. Extensive experiments on the HumanML3D and KIT-ML datasets demonstrate that MMM surpasses current leading methods in generating high-quality motion (evidenced by superior FID scores of 0.08 and 0.429), while offering advanced editing features such as body-part modification, motion in-betweening, and the synthesis of long motion sequences. In addition, MMM is two orders of magnitude faster on a single mid-range GPU than editable motion diffusion models. Our project page is available at \url{https://exitudio.github.io/MMM-page}.
CheapNET: Improving Light-weight speech enhancement network by projected loss function
Nov 27, 2023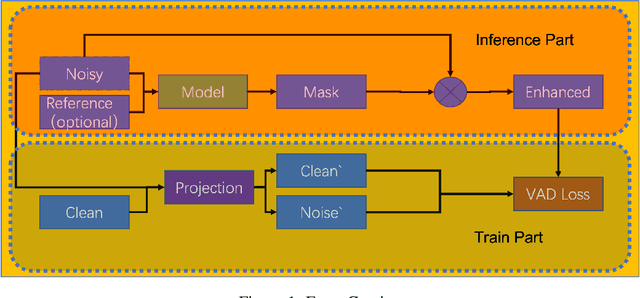
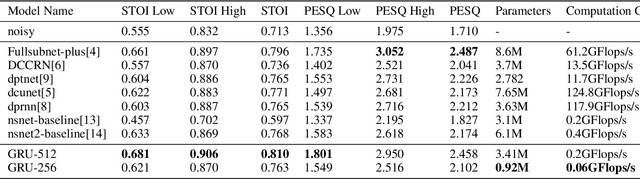
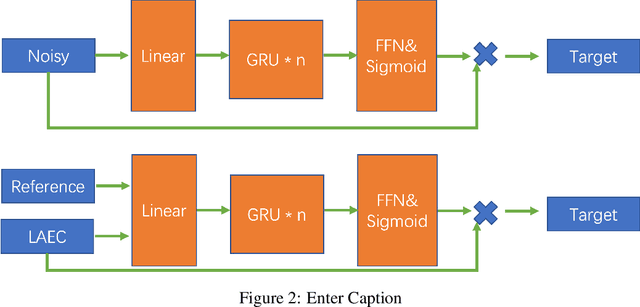
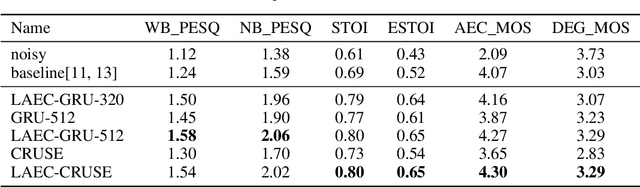
Noise suppression and echo cancellation are critical in speech enhancement and essential for smart devices and real-time communication. Deployed in voice processing front-ends and edge devices, these algorithms must ensure efficient real-time inference with low computational demands. Traditional edge-based noise suppression often uses MSE-based amplitude spectrum mask training, but this approach has limitations. We introduce a novel projection loss function, diverging from MSE, to enhance noise suppression. This method uses projection techniques to isolate key audio components from noise, significantly improving model performance. For echo cancellation, the function enables direct predictions on LAEC pre-processed outputs, substantially enhancing performance. Our noise suppression model achieves near state-of-the-art results with only 3.1M parameters and 0.4GFlops/s computational load. Moreover, our echo cancellation model outperforms replicated industry-leading models, introducing a new perspective in speech enhancement.
MTS-LOF: Medical Time-Series Representation Learning via Occlusion-Invariant Features
Oct 19, 2023Medical time series data are indispensable in healthcare, providing critical insights for disease diagnosis, treatment planning, and patient management. The exponential growth in data complexity, driven by advanced sensor technologies, has presented challenges related to data labeling. Self-supervised learning (SSL) has emerged as a transformative approach to address these challenges, eliminating the need for extensive human annotation. In this study, we introduce a novel framework for Medical Time Series Representation Learning, known as MTS-LOF. MTS-LOF leverages the strengths of contrastive learning and Masked Autoencoder (MAE) methods, offering a unique approach to representation learning for medical time series data. By combining these techniques, MTS-LOF enhances the potential of healthcare applications by providing more sophisticated, context-rich representations. Additionally, MTS-LOF employs a multi-masking strategy to facilitate occlusion-invariant feature learning. This approach allows the model to create multiple views of the data by masking portions of it. By minimizing the discrepancy between the representations of these masked patches and the fully visible patches, MTS-LOF learns to capture rich contextual information within medical time series datasets. The results of experiments conducted on diverse medical time series datasets demonstrate the superiority of MTS-LOF over other methods. These findings hold promise for significantly enhancing healthcare applications by improving representation learning. Furthermore, our work delves into the integration of joint-embedding SSL and MAE techniques, shedding light on the intricate interplay between temporal and structural dependencies in healthcare data. This understanding is crucial, as it allows us to grasp the complexities of healthcare data analysis.
Air-Decoding: Attribute Distribution Reconstruction for Decoding-Time Controllable Text Generation
Oct 24, 2023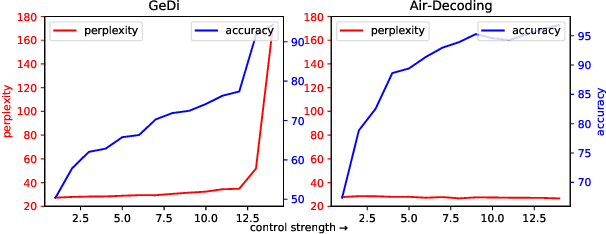
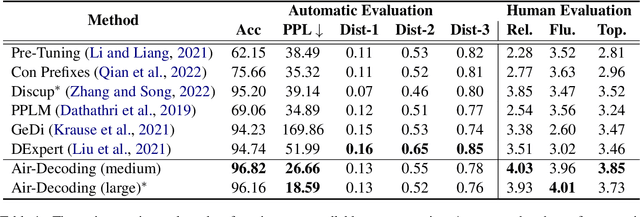
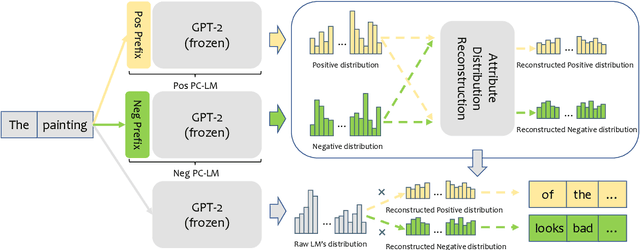
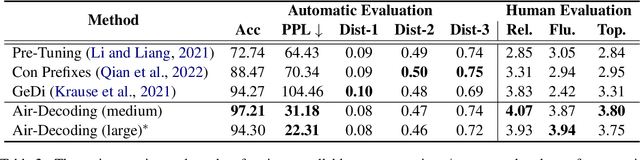
Controllable text generation (CTG) aims to generate text with desired attributes, and decoding-time-based methods have shown promising performance on this task. However, in this paper, we identify the phenomenon of Attribute Collapse for the first time. It causes the fluency of generated text to rapidly decrease when the control strength exceeds a critical value, rendering the text completely unusable. This limitation hinders the effectiveness of decoding methods in achieving high levels of controllability. To address this problem, we propose a novel lightweight decoding framework named Air-Decoding. Its main idea is reconstructing the attribute distributions to balance the weights between attribute words and non-attribute words to generate more fluent text. Specifically, we train prefixes by prefix-tuning to obtain attribute distributions. Then we design a novel attribute distribution reconstruction method to balance the obtained distributions and use the reconstructed distributions to guide language models for generation, effectively avoiding the issue of Attribute Collapse. Experiments on multiple CTG tasks prove that our method achieves a new state-of-the-art control performance.
Poster: Real-Time Object Substitution for Mobile Diminished Reality with Edge Computing
Oct 23, 2023Diminished Reality (DR) is considered as the conceptual counterpart to Augmented Reality (AR), and has recently gained increasing attention from both industry and academia. Unlike AR which adds virtual objects to the real world, DR allows users to remove physical content from the real world. When combined with object replacement technology, it presents an further exciting avenue for exploration within the metaverse. Although a few researches have been conducted on the intersection of object substitution and DR, there is no real-time object substitution for mobile diminished reality architecture with high quality. In this paper, we propose an end-to-end architecture to facilitate immersive and real-time scene construction for mobile devices with edge computing.
Active RIS Enhanced Spectrum Sensing for Cognitive Radio Networks
Nov 28, 2023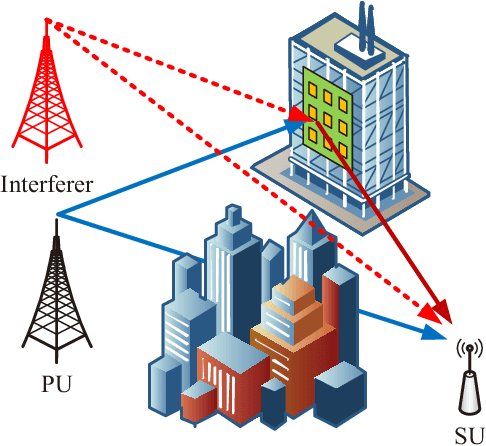
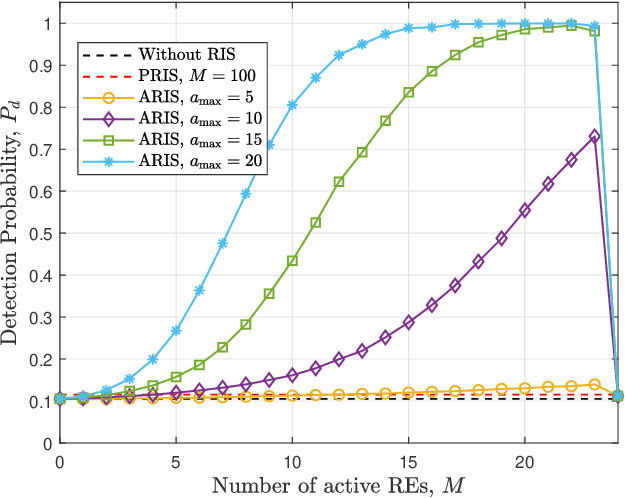

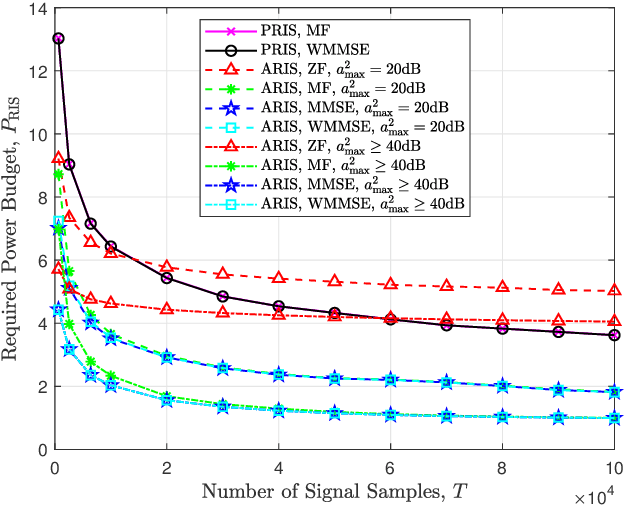
In opportunistic cognitive radio networks, when the primary signal is very weak compared to the background noise, the secondary user requires long sensing time to achieve a reliable spectrum sensing performance, leading to little remaining time for the secondary transmission. To tackle this issue, we propose an active reconfigurable intelligent surface (RIS) assisted spectrum sensing system, where the received signal strength from the interested primary user can be enhanced and underlying interference within the background noise can be mitigated as well. In comparison with the passive RIS, the active RIS can not only adapt the phase shift of each reflecting element but also amplify the incident signals. Notably, we study the reflecting coefficient matrix (RCM) optimization problem to improve the detection probability given a maximum tolerable false alarm probability and limited sensing time. Then, we show that the formulated problem can be equivalently transformed to a weighted mean square error minimization problem using the principle of the well-known weighted minimum mean square error (WMMSE) algorithm, and an iterative optimization approach is proposed to obtain the optimal RCM. In addition, to fairly compare passive RIS and active RIS, we study the required power budget of the RIS to achieve a target detection probability under a special case where the direct links are neglected and the RIS-related channels are line-of-sight. Via extensive simulations, the effectiveness of the WMMSE-based RCM optimization approach is demonstrated. Furthermore, the results reveal that the active RIS can outperform the passive RIS when the underlying interference within the background noise is relatively weak, whereas the passive RIS performs better in strong interference scenarios because the same power budget can support a vast number of passive reflecting elements for interference mitigation.
TurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023
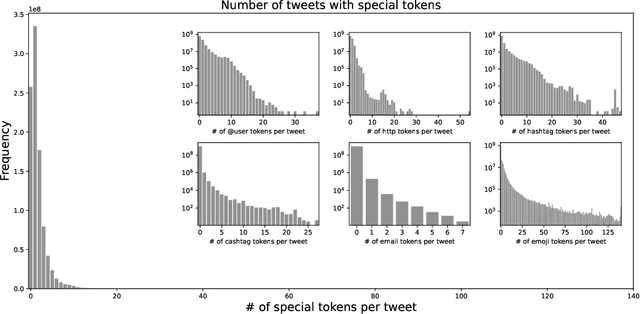
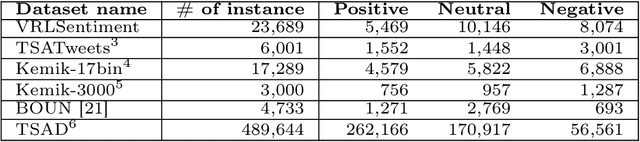
Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
Two Scalable Approaches for Burned-Area Mapping Using U-Net and Landsat Imagery
Nov 29, 2023Monitoring wildfires is an essential step in minimizing their impact on the planet, understanding the many negative environmental, economic, and social consequences. Recent advances in remote sensing technology combined with the increasing application of artificial intelligence methods have improved real-time, high-resolution fire monitoring. This study explores two proposed approaches based on the U-Net model for automating and optimizing the burned-area mapping process. Denoted 128 and AllSizes (AS), they are trained on datasets with a different class balance by cropping input images to different sizes. They are then applied to Landsat imagery and time-series data from two fire-prone regions in Chile. The results obtained after enhancement of model performance by hyperparameter optimization demonstrate the effectiveness of both approaches. Tests based on 195 representative images of the study area show that increasing dataset balance using the AS model yields better performance. More specifically, AS exhibited a Dice Coefficient (DC) of 0.93, an Omission Error (OE) of 0.086, and a Commission Error (CE) of 0.045, while the 128 model achieved a DC of 0.86, an OE of 0.12, and a CE of 0.12. These findings should provide a basis for further development of scalable automatic burned-area mapping tools.
Continuous Pose for Monocular Cameras in Neural Implicit Representation
Nov 28, 2023In this paper, we showcase the effectiveness of optimizing monocular camera poses as a continuous function of time. The camera poses are represented using an implicit neural function which maps the given time to the corresponding camera pose. The mapped camera poses are then used for the downstream tasks where joint camera pose optimization is also required. While doing so, the network parameters -- that implicitly represent camera poses -- are optimized. We exploit the proposed method in four diverse experimental settings, namely, (1) NeRF from noisy poses; (2) NeRF from asynchronous Events; (3) Visual Simultaneous Localization and Mapping (vSLAM); and (4) vSLAM with IMUs. In all four settings, the proposed method performs significantly better than the compared baselines and the state-of-the-art methods. Additionally, using the assumption of continuous motion, changes in pose may actually live in a manifold that has lower than 6 degrees of freedom (DOF) is also realized. We call this low DOF motion representation as the \emph{intrinsic motion} and use the approach in vSLAM settings, showing impressive camera tracking performance.