 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Anomaly Detection using Masked Latent Generative Modeling
Nov 22, 2023
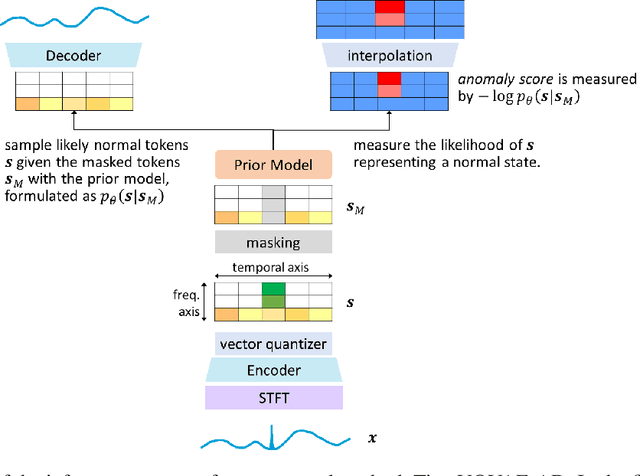
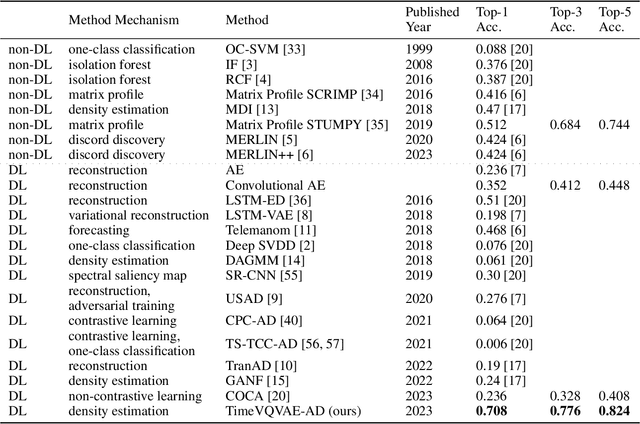
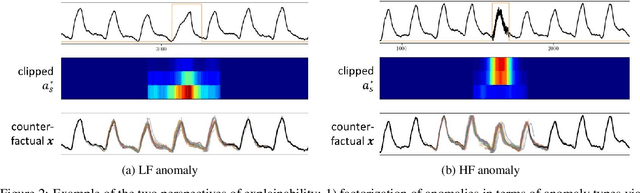
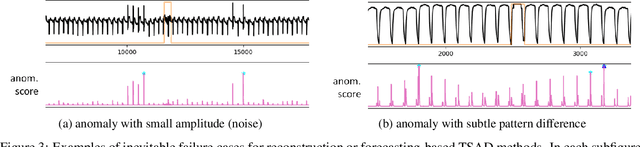
We present a novel time series anomaly detection method that achieves excellent detection accuracy while offering a superior level of explainability. Our proposed method, TimeVQVAE-AD, leverages masked generative modeling adapted from the cutting-edge time series generation method known as TimeVQVAE. The prior model is trained on the discrete latent space of a time-frequency domain. Notably, the dimensional semantics of the time-frequency domain are preserved in the latent space, enabling us to compute anomaly scores across different frequency bands, which provides a better insight into the detected anomalies. Additionally, the generative nature of the prior model allows for sampling likely normal states for detected anomalies, enhancing the explainability of the detected anomalies through counterfactuals. Our experimental evaluation on the UCR Time Series Anomaly archive demonstrates that TimeVQVAE-AD significantly surpasses the existing methods in terms of detection accuracy and explainability.
Ultrasensitive Textile Strain Sensors Redefine Wearable Silent Speech Interfaces with High Machine Learning Efficiency
Nov 27, 2023Our research presents a wearable Silent Speech Interface (SSI) technology that excels in device comfort, time-energy efficiency, and speech decoding accuracy for real-world use. We developed a biocompatible, durable textile choker with an embedded graphene-based strain sensor, capable of accurately detecting subtle throat movements. This sensor, surpassing other strain sensors in sensitivity by 420%, simplifies signal processing compared to traditional voice recognition methods. Our system uses a computationally efficient neural network, specifically a one-dimensional convolutional neural network with residual structures, to decode speech signals. This network is energy and time-efficient, reducing computational load by 90% while achieving 95.25% accuracy for a 20-word lexicon and swiftly adapting to new users and words with minimal samples. This innovation demonstrates a practical, sensitive, and precise wearable SSI suitable for daily communication applications.
Neural SPDE solver for uncertainty quantification in high-dimensional space-time dynamics
Nov 03, 2023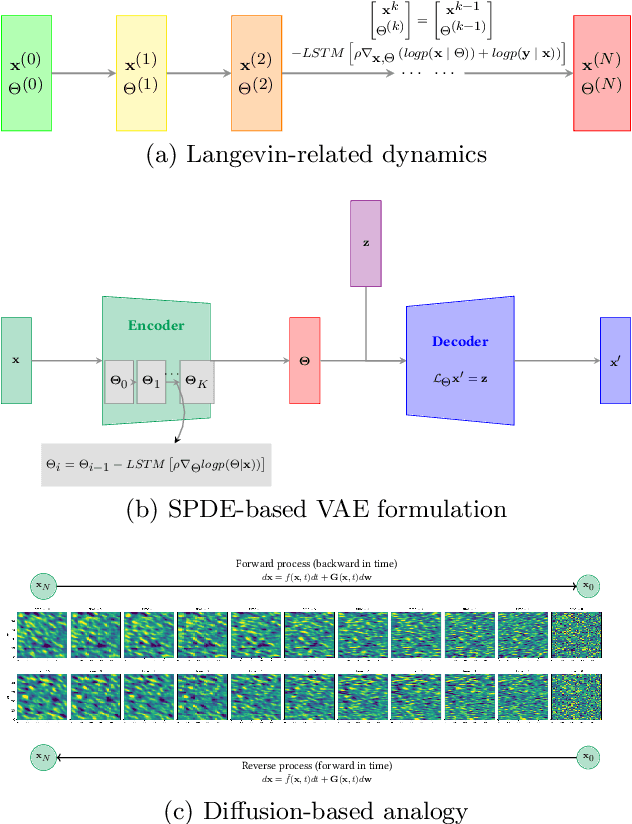
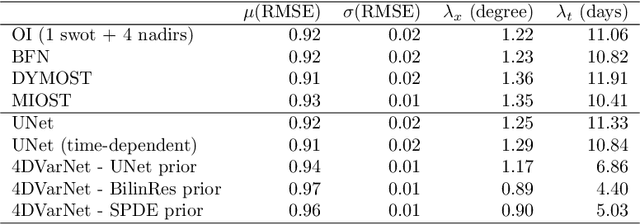
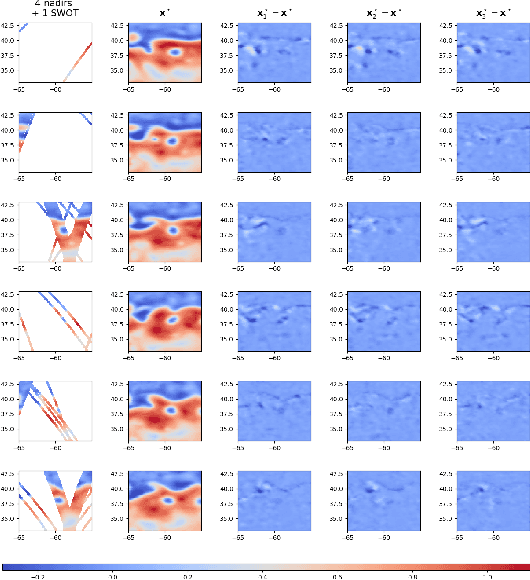
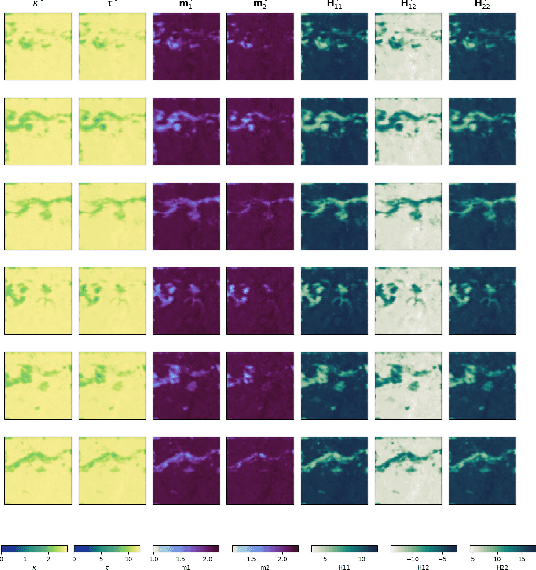
Historically, the interpolation of large geophysical datasets has been tackled using methods like Optimal Interpolation (OI) or model-based data assimilation schemes. However, the recent connection between Stochastic Partial Differential Equations (SPDE) and Gaussian Markov Random Fields (GMRF) introduced a novel approach to handle large datasets making use of sparse precision matrices in OI. Recent advancements in deep learning also addressed this issue by incorporating data assimilation into neural architectures: it treats the reconstruction task as a joint learning problem involving both prior model and solver as neural networks. Though, it requires further developments to quantify the associated uncertainties. In our work, we leverage SPDEbased Gaussian Processes to estimate complex prior models capable of handling nonstationary covariances in space and time. We develop a specific architecture able to learn both state and SPDE parameters as a neural SPDE solver, while providing the precisionbased analytical form of the SPDE sampling. The latter is used as a surrogate model along the data assimilation window. Because the prior is stochastic, we can easily draw samples from it and condition the members by our neural solver, allowing flexible estimation of the posterior distribution based on large ensemble. We demonstrate this framework on realistic Sea Surface Height datasets. Our solution improves the OI baseline, aligns with neural prior while enabling uncertainty quantification and online parameter estimation.
A Novel Normalized-Cut Solver with Nearest Neighbor Hierarchical Initialization
Nov 26, 2023Normalized-Cut (N-Cut) is a famous model of spectral clustering. The traditional N-Cut solvers are two-stage: 1) calculating the continuous spectral embedding of normalized Laplacian matrix; 2) discretization via $K$-means or spectral rotation. However, this paradigm brings two vital problems: 1) two-stage methods solve a relaxed version of the original problem, so they cannot obtain good solutions for the original N-Cut problem; 2) solving the relaxed problem requires eigenvalue decomposition, which has $\mathcal{O}(n^3)$ time complexity ($n$ is the number of nodes). To address the problems, we propose a novel N-Cut solver designed based on the famous coordinate descent method. Since the vanilla coordinate descent method also has $\mathcal{O}(n^3)$ time complexity, we design various accelerating strategies to reduce the time complexity to $\mathcal{O}(|E|)$ ($|E|$ is the number of edges). To avoid reliance on random initialization which brings uncertainties to clustering, we propose an efficient initialization method that gives deterministic outputs. Extensive experiments on several benchmark datasets demonstrate that the proposed solver can obtain larger objective values of N-Cut, meanwhile achieving better clustering performance compared to traditional solvers.
Are Vision Transformers More Data Hungry Than Newborn Visual Systems?
Dec 05, 2023Vision transformers (ViTs) are top performing models on many computer vision benchmarks and can accurately predict human behavior on object recognition tasks. However, researchers question the value of using ViTs as models of biological learning because ViTs are thought to be more data hungry than brains, with ViTs requiring more training data to reach similar levels of performance. To test this assumption, we directly compared the learning abilities of ViTs and animals, by performing parallel controlled rearing experiments on ViTs and newborn chicks. We first raised chicks in impoverished visual environments containing a single object, then simulated the training data available in those environments by building virtual animal chambers in a video game engine. We recorded the first-person images acquired by agents moving through the virtual chambers and used those images to train self supervised ViTs that leverage time as a teaching signal, akin to biological visual systems. When ViTs were trained through the eyes of newborn chicks, the ViTs solved the same view invariant object recognition tasks as the chicks. Thus, ViTs were not more data hungry than newborn visual systems: both learned view invariant object representations in impoverished visual environments. The flexible and generic attention based learning mechanism in ViTs combined with the embodied data streams available to newborn animals appears sufficient to drive the development of animal-like object recognition.
TSVR+: Twin support vector regression with privileged information
Dec 05, 2023In the realm of machine learning, the data may contain additional attributes, known as privileged information (PI). The main purpose of PI is to assist in the training of the model and then utilize the acquired knowledge to make predictions for unseen samples. Support vector regression (SVR) is an effective regression model, however, it has a low learning speed due to solving a convex quadratic problem (QP) subject to a pair of constraints. In contrast, twin support vector regression (TSVR) is more efficient than SVR as it solves two QPs each subject to one set of constraints. However, TSVR and its variants are trained only on regular features and do not use privileged features for training. To fill this gap, we introduce a fusion of TSVR with learning using privileged information (LUPI) and propose a novel approach called twin support vector regression with privileged information (TSVR+). The regularization terms in the proposed TSVR+ capture the essence of statistical learning theory and implement the structural risk minimization principle. We use the successive overrelaxation (SOR) technique to solve the optimization problem of the proposed TSVR+, which enhances the training efficiency. As far as our knowledge extends, the integration of the LUPI concept into twin variants of regression models is a novel advancement. The numerical experiments conducted on UCI, stock and time series data collectively demonstrate the superiority of the proposed model.
Constrained Twin Variational Auto-Encoder for Intrusion Detection in IoT Systems
Dec 05, 2023Intrusion detection systems (IDSs) play a critical role in protecting billions of IoT devices from malicious attacks. However, the IDSs for IoT devices face inherent challenges of IoT systems, including the heterogeneity of IoT data/devices, the high dimensionality of training data, and the imbalanced data. Moreover, the deployment of IDSs on IoT systems is challenging, and sometimes impossible, due to the limited resources such as memory/storage and computing capability of typical IoT devices. To tackle these challenges, this article proposes a novel deep neural network/architecture called Constrained Twin Variational Auto-Encoder (CTVAE) that can feed classifiers of IDSs with more separable/distinguishable and lower-dimensional representation data. Additionally, in comparison to the state-of-the-art neural networks used in IDSs, CTVAE requires less memory/storage and computing power, hence making it more suitable for IoT IDS systems. Extensive experiments with the 11 most popular IoT botnet datasets show that CTVAE can boost around 1% in terms of accuracy and Fscore in detection attack compared to the state-of-the-art machine learning and representation learning methods, whilst the running time for attack detection is lower than 2E-6 seconds and the model size is lower than 1 MB. We also further investigate various characteristics of CTVAE in the latent space and in the reconstruction representation to demonstrate its efficacy compared with current well-known methods.
In Search of Lost Online Test-time Adaptation: A Survey
Oct 31, 2023

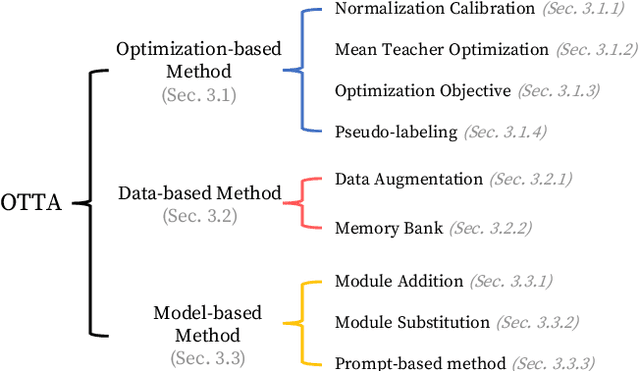

In this paper, we present a comprehensive survey on online test-time adaptation (OTTA), a paradigm focused on adapting machine learning models to novel data distributions upon batch arrival. Despite the proliferation of OTTA methods recently, the field is mired in issues like ambiguous settings, antiquated backbones, and inconsistent hyperparameter tuning, obfuscating the real challenges and making reproducibility elusive. For clarity and a rigorous comparison, we classify OTTA techniques into three primary categories and subject them to benchmarks using the potent Vision Transformer (ViT) backbone to discover genuinely effective strategies. Our benchmarks span not only conventional corrupted datasets such as CIFAR-10/100-C and ImageNet-C but also real-world shifts embodied in CIFAR-10.1 and CIFAR-10-Warehouse, encapsulating variations across search engines and synthesized data by diffusion models. To gauge efficiency in online scenarios, we introduce novel evaluation metrics, inclusive of FLOPs, shedding light on the trade-offs between adaptation accuracy and computational overhead. Our findings diverge from existing literature, indicating: (1) transformers exhibit heightened resilience to diverse domain shifts, (2) the efficacy of many OTTA methods hinges on ample batch sizes, and (3) stability in optimization and resistance to perturbations are critical during adaptation, especially when the batch size is 1. Motivated by these insights, we pointed out promising directions for future research. The source code will be made available.
Effectively Fine-tune to Improve Large Multimodal Models for Radiology Report Generation
Dec 03, 2023Writing radiology reports from medical images requires a high level of domain expertise. It is time-consuming even for trained radiologists and can be error-prone for inexperienced radiologists. It would be appealing to automate this task by leveraging generative AI, which has shown drastic progress in vision and language understanding. In particular, Large Language Models (LLM) have demonstrated impressive capabilities recently and continued to set new state-of-the-art performance on almost all natural language tasks. While many have proposed architectures to combine vision models with LLMs for multimodal tasks, few have explored practical fine-tuning strategies. In this work, we proposed a simple yet effective two-stage fine-tuning protocol to align visual features to LLM's text embedding space as soft visual prompts. Our framework with OpenLLaMA-7B achieved state-of-the-art level performance without domain-specific pretraining. Moreover, we provide detailed analyses of soft visual prompts and attention mechanisms, shedding light on future research directions.
Towards an accurate and generalizable multiple sclerosis lesion segmentation model using self-ensembled lesion fusion
Dec 03, 2023Automatic multiple sclerosis (MS) lesion segmentation using multi-contrast magnetic resonance (MR) images provides improved efficiency and reproducibility compared to manual delineation. Current state-of-the-art automatic MS lesion segmentation methods utilize modified U-Net-like architectures. However, in the literature, dedicated architecture modifications were always required to maximize their performance. In addition, the best-performing methods have not proven to be generalizable to diverse test datasets with contrast variations and image artifacts. In this work, we developed an accurate and generalizable MS lesion segmentation model using the well-known U-Net architecture without further modification. A novel test-time self-ensembled lesion fusion strategy is proposed that not only achieved the best performance using the ISBI 2015 MS segmentation challenge data but also demonstrated robustness across various self-ensemble parameter choices. Moreover, equipped with instance normalization rather than batch normalization widely used in literature, the model trained on the ISBI challenge data generalized well on clinical test datasets from different scanners.