 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On-sensor Printed Machine Learning Classification via Bespoke ADC and Decision Tree Co-Design
Dec 02, 2023
Printed electronics (PE) technology provides cost-effective hardware with unmet customization, due to their low non-recurring engineering and fabrication costs. PE exhibit features such as flexibility, stretchability, porosity, and conformality, which make them a prominent candidate for enabling ubiquitous computing. Still, the large feature sizes in PE limit the realization of complex printed circuits, such as machine learning classifiers, especially when processing sensor inputs is necessary, mainly due to the costly analog-to-digital converters (ADCs). To this end, we propose the design of fully customized ADCs and present, for the first time, a co-design framework for generating bespoke Decision Tree classifiers. Our comprehensive evaluation shows that our co-design enables self-powered operation of on-sensor printed classifiers in all benchmark cases.
TLControl: Trajectory and Language Control for Human Motion Synthesis
Nov 28, 2023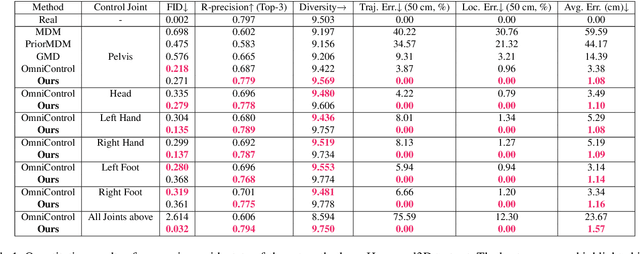
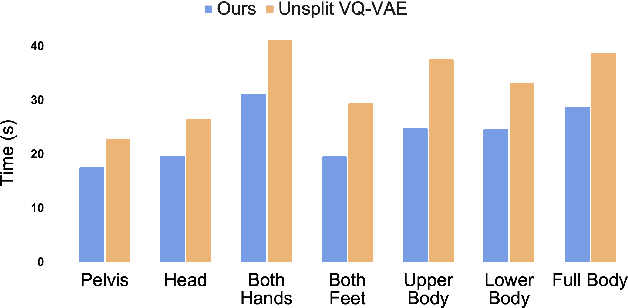
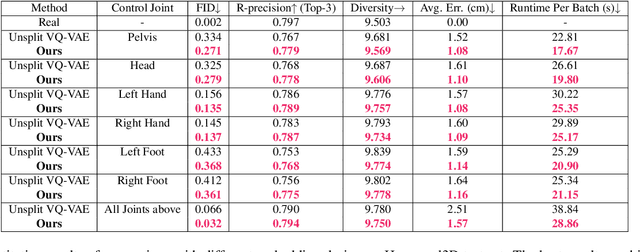
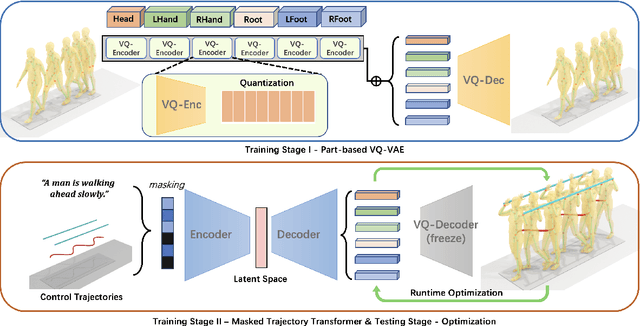
Controllable human motion synthesis is essential for applications in AR/VR, gaming, movies, and embodied AI. Existing methods often focus solely on either language or full trajectory control, lacking precision in synthesizing motions aligned with user-specified trajectories, especially for multi-joint control. To address these issues, we present TLControl, a new method for realistic human motion synthesis, incorporating both low-level trajectory and high-level language semantics controls. Specifically, we first train a VQ-VAE to learn a compact latent motion space organized by body parts. We then propose a Masked Trajectories Transformer to make coarse initial predictions of full trajectories of joints based on the learned latent motion space, with user-specified partial trajectories and text descriptions as conditioning. Finally, we introduce an efficient test-time optimization to refine these coarse predictions for accurate trajectory control. Experiments demonstrate that TLControl outperforms the state-of-the-art in trajectory accuracy and time efficiency, making it practical for interactive and high-quality animation generation.
Temporal Importance Factor for Loss Functions for CTR Prediction
Nov 28, 2023Click-through rate (CTR) prediction is an important task for the companies to recommend products which better match user preferences. User behavior in digital advertising is dynamic and changes over time. It is crucial for the companies to capture the most recent trends to provide more accurate recommendations for users. In CTR prediction, most models use binary cross-entropy loss function. However, it does not focus on the data distribution shifts occurring over time. To address this problem, we propose a factor for the loss functions by utilizing the sequential nature of user-item interactions. This approach aims to focus on the most recent samples by penalizing them more through the loss function without forgetting the long-term information. Our solution is model-agnostic, and the temporal importance factor can be used with different loss functions. Offline experiments in both public and company datasets show that the temporal importance factor for loss functions outperforms the baseline loss functions considered.
Fourier Neural Differential Equations for learning Quantum Field Theories
Nov 28, 2023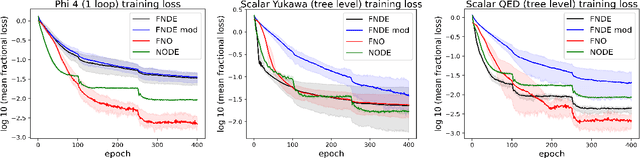
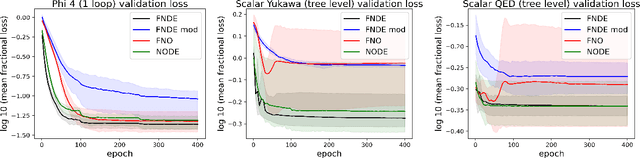
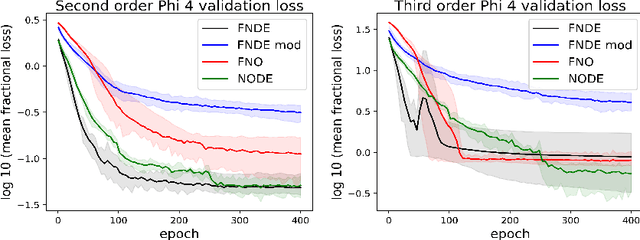
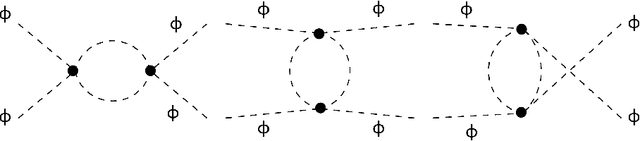
A Quantum Field Theory is defined by its interaction Hamiltonian, and linked to experimental data by the scattering matrix. The scattering matrix is calculated as a perturbative series, and represented succinctly as a first order differential equation in time. Neural Differential Equations (NDEs) learn the time derivative of a residual network's hidden state, and have proven efficacy in learning differential equations with physical constraints. Hence using an NDE to learn particle scattering matrices presents a possible experiment-theory phenomenological connection. In this paper, NDE models are used to learn $\phi^4$ theory, Scalar-Yukawa theory and Scalar Quantum Electrodynamics. A new NDE architecture is also introduced, the Fourier Neural Differential Equation (FNDE), which combines NDE integration and Fourier network convolution. The FNDE model demonstrates better generalisability than the non-integrated equivalent FNO model. It is also shown that by training on scattering data, the interaction Hamiltonian of a theory can be extracted from network parameters.
GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Surfaces
Nov 29, 2023The advent of neural 3D Gaussians has recently brought about a revolution in the field of neural rendering, facilitating the generation of high-quality renderings at real-time speeds. However, the explicit and discrete representation encounters challenges when applied to scenes featuring reflective surfaces. In this paper, we present GaussianShader, a novel method that applies a simplified shading function on 3D Gaussians to enhance the neural rendering in scenes with reflective surfaces while preserving the training and rendering efficiency. The main challenge in applying the shading function lies in the accurate normal estimation on discrete 3D Gaussians. Specifically, we proposed a novel normal estimation framework based on the shortest axis directions of 3D Gaussians with a delicately designed loss to make the consistency between the normals and the geometries of Gaussian spheres. Experiments show that GaussianShader strikes a commendable balance between efficiency and visual quality. Our method surpasses Gaussian Splatting in PSNR on specular object datasets, exhibiting an improvement of 1.57dB. When compared to prior works handling reflective surfaces, such as Ref-NeRF, our optimization time is significantly accelerated (23h vs. 0.58h). Please click on our project website to see more results.
Swarm Synergy: A Silent Way of Forming Community
Nov 29, 2023In this paper, we introduce a novel swarm application, swarm synergy, where robots in a swarm intend to form communities. Each robot is considered to make independent decisions without any communication capability (silent agent). The proposed algorithm is based on parameters local to individual robots. Engaging scenarios are studied where the silent robots form communities without the preset conditions on the number of communities, community size, goal location of each community, and specific members in the community. Our approach allows silent robots to achieve this self-organized swarm behavior using only sensory inputs from the environment. The algorithm facilitates the formation of multiple swarm communities at arbitrary locations with unspecified goal locations. We further infer the behavior of swarm synergy to ensure the anonymity/untraceability of both robots and communities. The robots intend to form a community by sensing the neighbors, creating synergy in a bounded environment. The time to achieve synergy depends on the environment boundary and the onboard sensor's field of view. Compared to the state-of-art with similar objectives, the proposed communication-free swarm synergy shows comparative time to synergize with untraceability features.
SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM
Dec 06, 2023Large language models (LLMs) have shown remarkable capabilities in various tasks. However their huge model size and the consequent demand for computational and memory resources also pose challenges to model deployment. Currently, 4-bit post-training quantization (PTQ) has achieved some success in LLMs, reducing the memory footprint by approximately 75% compared to FP16 models, albeit with some accuracy loss. In this paper, we propose SmoothQuant+, an accurate and efficient 4-bit weight-only PTQ that requires no additional training, which enables lossless in accuracy for LLMs for the first time. Based on the fact that the loss of weight quantization is amplified by the activation outliers, SmoothQuant+ smoothes the activation outliers by channel before quantization, while adjusting the corresponding weights for mathematical equivalence, and then performs group-wise 4-bit weight quantization for linear layers. We have integrated SmoothQuant+ into the vLLM framework, an advanced high-throughput inference engine specially developed for LLMs, and equipped it with an efficient W4A16 CUDA kernels, so that vLLM can seamlessly support SmoothQuant+ 4-bit weight quantization. Our results show that, with SmoothQuant+, the Code Llama-34B model can be quantized and deployed on a A100 40GB GPU, achieving lossless accuracy and a throughput increase of 1.9 to 4.0 times compared to the FP16 model deployed on two A100 40GB GPUs. Moreover, the latency per token is only 68% of the FP16 model deployed on two A100 40GB GPUs. This is the state-of-the-art 4-bit weight quantization for LLMs as we know.
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Dec 06, 20233D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework leads to warp-level divergence. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
From concrete mixture to structural design -- a holistic optimization procedure in the presence of uncertainties
Dec 06, 2023Designing civil structures such as bridges, dams or buildings is a complex task requiring many synergies from several experts. Each is responsible for different parts of the process. This is often done in a sequential manner, e.g. the structural engineer makes a design under the assumption of certain material properties (e.g. the strength class of the concrete), and then the material engineer optimizes the material with these restrictions. This paper proposes a holistic optimization procedure, which combines the concrete mixture design and structural simulations in a joint, forward workflow that we ultimately seek to invert. In this manner, new mixtures beyond standard ranges can be considered. Any design effort should account for the presence of uncertainties which can be aleatoric or epistemic as when data is used to calibrate physical models or identify models that fill missing links in the workflow. Inverting the causal relations established poses several challenges especially when these involve physics-based models which most often than not do not provide derivatives/sensitivities or when design constraints are present. To this end, we advocate Variational Optimization, with proposed extensions and appropriately chosen heuristics to overcome the aforementioned challenges. The proposed methodology is illustrated using the design of a precast concrete beam with the objective to minimize the global warming potential while satisfying a number of constraints associated with its load-bearing capacity after 28days according to the Eurocode, the demoulding time as computed by a complex nonlinear Finite Element model, and the maximum temperature during the hydration.
Optimal Wildfire Escape Route Planning for Drones under Dynamic Fire and Smoke
Dec 06, 2023In recent years, the increasing prevalence and intensity of wildfires have posed significant challenges to emergency response teams. The utilization of unmanned aerial vehicles (UAVs), commonly known as drones, has shown promise in aiding wildfire management efforts. This work focuses on the development of an optimal wildfire escape route planning system specifically designed for drones, considering dynamic fire and smoke models. First, the location of the source of the wildfire can be well located by information fusion between UAV and satellite, and the road conditions in the vicinity of the fire can be assessed and analyzed using multi-channel remote sensing data. Second, the road network can be extracted and segmented in real time using UAV vision technology, and each road in the road network map can be given priority based on the results of road condition classification. Third, the spread model of dynamic fires calculates the new location of the fire source based on the fire intensity, wind speed and direction, and the radius increases as the wildfire spreads. Smoke is generated around the fire source to create a visual representation of a burning fire. Finally, based on the improved A* algorithm, which considers all the above factors, the UAV can quickly plan an escape route based on the starting and destination locations that avoid the location of the fire source and the area where it is spreading. By considering dynamic fire and smoke models, the proposed system enhances the safety and efficiency of drone operations in wildfire environments.