 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DDMT: Denoising Diffusion Mask Transformer Models for Multivariate Time Series Anomaly Detection
Oct 13, 2023
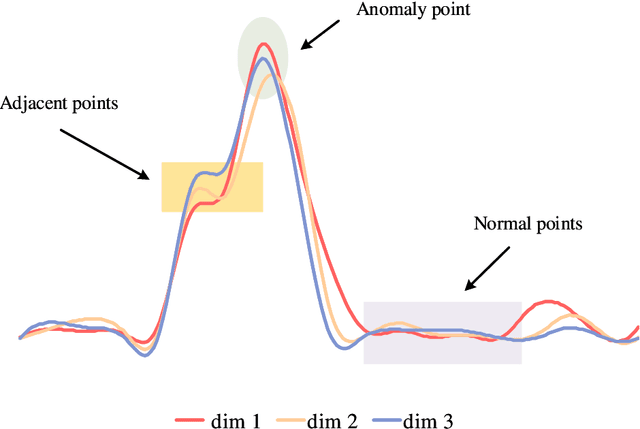

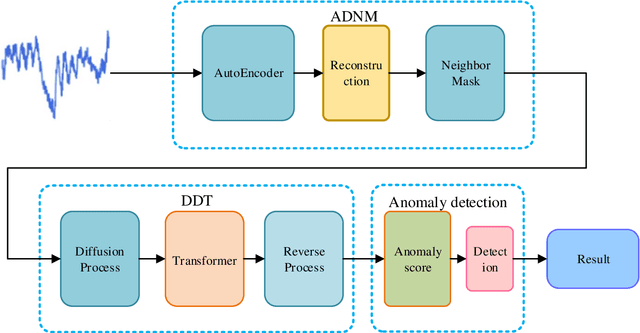
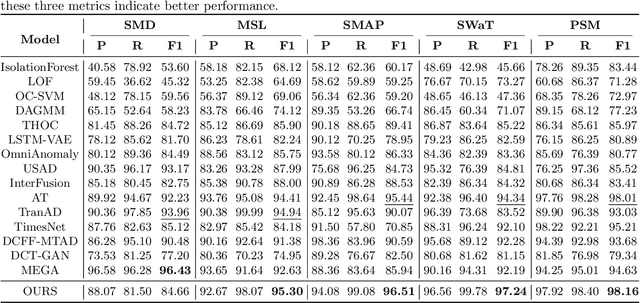
Anomaly detection in multivariate time series has emerged as a crucial challenge in time series research, with significant research implications in various fields such as fraud detection, fault diagnosis, and system state estimation. Reconstruction-based models have shown promising potential in recent years for detecting anomalies in time series data. However, due to the rapid increase in data scale and dimensionality, the issues of noise and Weak Identity Mapping (WIM) during time series reconstruction have become increasingly pronounced. To address this, we introduce a novel Adaptive Dynamic Neighbor Mask (ADNM) mechanism and integrate it with the Transformer and Denoising Diffusion Model, creating a new framework for multivariate time series anomaly detection, named Denoising Diffusion Mask Transformer (DDMT). The ADNM module is introduced to mitigate information leakage between input and output features during data reconstruction, thereby alleviating the problem of WIM during reconstruction. The Denoising Diffusion Transformer (DDT) employs the Transformer as an internal neural network structure for Denoising Diffusion Model. It learns the stepwise generation process of time series data to model the probability distribution of the data, capturing normal data patterns and progressively restoring time series data by removing noise, resulting in a clear recovery of anomalies. To the best of our knowledge, this is the first model that combines Denoising Diffusion Model and the Transformer for multivariate time series anomaly detection. Experimental evaluations were conducted on five publicly available multivariate time series anomaly detection datasets. The results demonstrate that the model effectively identifies anomalies in time series data, achieving state-of-the-art performance in anomaly detection.
Allpass impulse response modelling
Nov 24, 2023This document defines a method for FIR system modelling which is very trivial as it only depends on phase introduction and removal (allpass filters). As magnitude is not altered, the processing is numerically stable. It is limited to phase alteration which maintains the time domain magnitude to force a system within its linear limits.
Cross-correlation image analysis for real-time particle tracking
Oct 12, 2023Accurately measuring translations between images is essential in many fields, including biology, medicine, geography, and physics. Existing methods, including the popular FFT-based cross-correlation, are not suitable for real-time analysis, which is especially vital in feedback control systems. To fill this gap, we introduce a new algorithm which approaches shot-noise limited displacement detection and a GPU-based implementation for real-time image analysis.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
One Pass Streaming Algorithm for Super Long Token Attention Approximation in Sublinear Space
Nov 24, 2023Deploying Large Language Models (LLMs) in streaming applications that involve long contexts, particularly for extended dialogues and text analysis, is of paramount importance but presents two significant challenges. Firstly, the memory consumption is substantial during the decoding phase due to the caching of Key and Value states (KV) of previous tokens. Secondly, attention computation is time-consuming with a time complexity of $O(n^2)$ for the generation of each token. In recent OpenAI DevDay (Nov 6, 2023), OpenAI released a new model that is able to support a 128K-long document, in our paper, we focus on the memory-efficient issue when context length $n$ is much greater than 128K ($n \gg 2^d$). Considering a single-layer self-attention with Query, Key, and Value matrices $Q, K, V \in \mathbb{R}^{n \times d}$, the polynomial method approximates the attention output $T \in \mathbb{R}^{n \times d}$. It accomplishes this by constructing $U_1, U_2 \in \mathbb{R}^{n \times t}$ to expedite attention ${\sf Attn}(Q, K, V)$ computation within $n^{1+o(1)}$ time executions. Despite this, storing the Key and Value matrices $K, V \in \mathbb{R}^{n \times d}$ still necessitates $O( n d)$ space, leading to significant memory usage. In response to these challenges, we introduce a new algorithm that only reads one pass of the data in streaming fashion. This method employs sublinear space $o(n)$ to store three sketch matrices, alleviating the need for exact $K, V$ storage. Notably, our algorithm exhibits exceptional memory-efficient performance with super-long tokens. As the token length $n$ increases, our error guarantee diminishes while the memory usage remains nearly constant. This unique attribute underscores the potential of our technique in efficiently handling LLMs in streaming applications.
Reinforcement Learning from Statistical Feedback: the Journey from AB Testing to ANT Testing
Nov 24, 2023Reinforcement Learning from Human Feedback (RLHF) has played a crucial role in the success of large models such as ChatGPT. RLHF is a reinforcement learning framework which combines human feedback to improve learning effectiveness and performance. However, obtaining preferences feedback manually is quite expensive in commercial applications. Some statistical commercial indicators are usually more valuable and always ignored in RLHF. There exists a gap between commercial target and model training. In our research, we will attempt to fill this gap with statistical business feedback instead of human feedback, using AB testing which is a well-established statistical method. Reinforcement Learning from Statistical Feedback (RLSF) based on AB testing is proposed. Statistical inference methods are used to obtain preferences for training the reward network, which fine-tunes the pre-trained model in reinforcement learning framework, achieving greater business value. Furthermore, we extend AB testing with double selections at a single time-point to ANT testing with multiple selections at different feedback time points. Moreover, we design numerical experiences to validate the effectiveness of our algorithm framework.
New Epochs in AI Supervision: Design and Implementation of an Autonomous Radiology AI Monitoring System
Nov 24, 2023With the increasingly widespread adoption of AI in healthcare, maintaining the accuracy and reliability of AI models in clinical practice has become crucial. In this context, we introduce novel methods for monitoring the performance of radiology AI classification models in practice, addressing the challenges of obtaining real-time ground truth for performance monitoring. We propose two metrics - predictive divergence and temporal stability - to be used for preemptive alerts of AI performance changes. Predictive divergence, measured using Kullback-Leibler and Jensen-Shannon divergences, evaluates model accuracy by comparing predictions with those of two supplementary models. Temporal stability is assessed through a comparison of current predictions against historical moving averages, identifying potential model decay or data drift. This approach was retrospectively validated using chest X-ray data from a single-center imaging clinic, demonstrating its effectiveness in maintaining AI model reliability. By providing continuous, real-time insights into model performance, our system ensures the safe and effective use of AI in clinical decision-making, paving the way for more robust AI integration in healthcare
A statistical approach to latent dynamic modeling with differential equations
Nov 27, 2023Ordinary differential equations (ODEs) can provide mechanistic models of temporally local changes of processes, where parameters are often informed by external knowledge. While ODEs are popular in systems modeling, they are less established for statistical modeling of longitudinal cohort data, e.g., in a clinical setting. Yet, modeling of local changes could also be attractive for assessing the trajectory of an individual in a cohort in the immediate future given its current status, where ODE parameters could be informed by further characteristics of the individual. However, several hurdles so far limit such use of ODEs, as compared to regression-based function fitting approaches. The potentially higher level of noise in cohort data might be detrimental to ODEs, as the shape of the ODE solution heavily depends on the initial value. In addition, larger numbers of variables multiply such problems and might be difficult to handle for ODEs. To address this, we propose to use each observation in the course of time as the initial value to obtain multiple local ODE solutions and build a combined estimator of the underlying dynamics. Neural networks are used for obtaining a low-dimensional latent space for dynamic modeling from a potentially large number of variables, and for obtaining patient-specific ODE parameters from baseline variables. Simultaneous identification of dynamic models and of a latent space is enabled by recently developed differentiable programming techniques. We illustrate the proposed approach in an application with spinal muscular atrophy patients and a corresponding simulation study. In particular, modeling of local changes in health status at any point in time is contrasted to the interpretation of functions obtained from a global regression. This more generally highlights how different application settings might demand different modeling strategies.
On the Out-Of-Distribution Robustness of Self-Supervised Representation Learning for Phonocardiogram Signals
Dec 01, 2023Objective: Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with newly-collected, out-of-distribution (OOD) datasets. Methods: Contrastive Self-Supervised Learning (SSL) offers a potential solution to the scarcity of labeled data as it takes advantage of unlabeled data to increase model effectiveness and robustness. In this research, we propose applying contrastive SSL for detecting abnormalities in phonocardiogram (PCG) samples by learning a generalized representation of the signal. Specifically, we perform an extensive comparative evaluation of a wide range of audio-based augmentations and evaluate trained classifiers on multiple datasets across different downstream tasks. Results: We experimentally demonstrate that, depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32% when evaluated on unseen data, while SSL models only lose up to 10% or even improve in some cases. Conclusions: Contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed extensive evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing. Significance: We provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.
A Low-Power Neuromorphic Approach for Efficient Eye-Tracking
Dec 01, 2023This paper introduces a neuromorphic methodology for eye tracking, harnessing pure event data captured by a Dynamic Vision Sensor (DVS) camera. The framework integrates a directly trained Spiking Neuron Network (SNN) regression model and leverages a state-of-the-art low power edge neuromorphic processor - Speck, collectively aiming to advance the precision and efficiency of eye-tracking systems. First, we introduce a representative event-based eye-tracking dataset, "Ini-30", which was collected with two glass-mounted DVS cameras from thirty volunteers. Then,a SNN model, based on Integrate And Fire (IAF) neurons, named "Retina", is described , featuring only 64k parameters (6.63x fewer than the latest) and achieving pupil tracking error of only 3.24 pixels in a 64x64 DVS input. The continous regression output is obtained by means of convolution using a non-spiking temporal 1D filter slided across the output spiking layer. Finally, we evaluate Retina on the neuromorphic processor, showing an end-to-end power between 2.89-4.8 mW and a latency of 5.57-8.01 mS dependent on the time window. We also benchmark our model against the latest event-based eye-tracking method, "3ET", which was built upon event frames. Results show that Retina achieves superior precision with 1.24px less pupil centroid error and reduced computational complexity with 35 times fewer MAC operations. We hope this work will open avenues for further investigation of close-loop neuromorphic solutions and true event-based training pursuing edge performance.