 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ReLU-QP: A GPU-Accelerated Quadratic Programming Solver for Model-Predictive Control
Nov 29, 2023
We present ReLU-QP, a GPU-accelerated solver for quadratic programs (QPs) that is capable of solving high-dimensional control problems at real-time rates. ReLU-QP is derived by exactly reformulating the Alternating Direction Method of Multipliers (ADMM) algorithm for solving QPs as a deep, weight-tied neural network with rectified linear unit (ReLU) activations. This reformulation enables the deployment of ReLU-QP on GPUs using standard machine-learning toolboxes. We evaluate the performance of ReLU-QP across three model-predictive control (MPC) benchmarks: stabilizing random linear dynamical systems with control limits, balancing an Atlas humanoid robot on a single foot, and tracking whole-body reference trajectories on a quadruped equipped with a six-degree-of-freedom arm. These benchmarks indicate that ReLU-QP is competitive with state-of-the-art CPU-based solvers for small-to-medium-scale problems and offers order-of-magnitude speed improvements for larger-scale problems.
Learning-driven Zero Trust in Distributed Computing Continuum Systems
Nov 29, 2023Converging Zero Trust (ZT) with learning techniques can solve various operational and security challenges in Distributed Computing Continuum Systems (DCCS). Implementing centralized ZT architecture is seen as unsuitable for the computing continuum (e.g., computing entities with limited connectivity and visibility, etc.). At the same time, implementing decentralized ZT in the computing continuum requires understanding infrastructure limitations and novel approaches to enhance resource access management decisions. To overcome such challenges, we present a novel learning-driven ZT conceptual architecture designed for DCCS. We aim to enhance ZT architecture service quality by incorporating lightweight learning strategies such as Representation Learning (ReL) and distributing ZT components across the computing continuum. The ReL helps to improve the decision-making process by predicting threats or untrusted requests. Through an illustrative example, we show how the learning process detects and blocks the requests, enhances resource access control, and reduces network and computation overheads. Lastly, we discuss the conceptual architecture, processes, and provide a research agenda.
VITATECS: A Diagnostic Dataset for Temporal Concept Understanding of Video-Language Models
Nov 29, 2023The ability to perceive how objects change over time is a crucial ingredient in human intelligence. However, current benchmarks cannot faithfully reflect the temporal understanding abilities of video-language models (VidLMs) due to the existence of static visual shortcuts. To remedy this issue, we present VITATECS, a diagnostic VIdeo-Text dAtaset for the evaluation of TEmporal Concept underStanding. Specifically, we first introduce a fine-grained taxonomy of temporal concepts in natural language in order to diagnose the capability of VidLMs to comprehend different temporal aspects. Furthermore, to disentangle the correlation between static and temporal information, we generate counterfactual video descriptions that differ from the original one only in the specified temporal aspect. We employ a semi-automatic data collection framework using large language models and human-in-the-loop annotation to obtain high-quality counterfactual descriptions efficiently. Evaluation of representative video-language understanding models confirms their deficiency in temporal understanding, revealing the need for greater emphasis on the temporal elements in video-language research.
Zero-shot Retrieval: Augmenting Pre-trained Models with Search Engines
Nov 29, 2023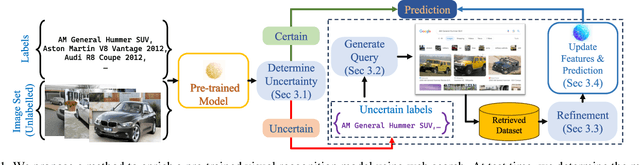
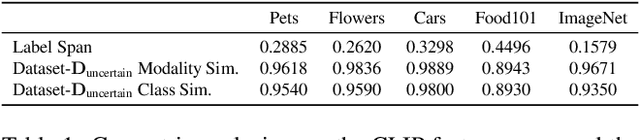
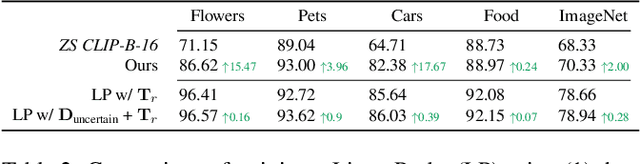
Large pre-trained models can dramatically reduce the amount of task-specific data required to solve a problem, but they often fail to capture domain-specific nuances out of the box. The Web likely contains the information necessary to excel on any specific application, but identifying the right data a priori is challenging. This paper shows how to leverage recent advances in NLP and multi-modal learning to augment a pre-trained model with search engine retrieval. We propose to retrieve useful data from the Web at test time based on test cases that the model is uncertain about. Different from existing retrieval-augmented approaches, we then update the model to address this underlying uncertainty. We demonstrate substantial improvements in zero-shot performance, e.g. a remarkable increase of 15 percentage points in accuracy on the Stanford Cars and Flowers datasets. We also present extensive experiments that explore the impact of noisy retrieval and different learning strategies.
Adam-like Algorithm with Smooth Clipping Attains Global Minima: Analysis Based on Ergodicity of Functional SDEs
Nov 29, 2023In this paper, we prove that an Adam-type algorithm with smooth clipping approaches the global minimizer of the regularized non-convex loss function. Adding smooth clipping and taking the state space as the set of all trajectories, we can apply the ergodic theory of Markov semigroups for this algorithm and investigate its asymptotic behavior. The ergodic theory we establish in this paper reduces the problem of evaluating the convergence, generalization error and discretization error of this algorithm to the problem of evaluating the difference between two functional stochastic differential equations (SDEs) with different drift coefficients. As a result of our analysis, we have shown that this algorithm minimizes the the regularized non-convex loss function with errors of the form $n^{-1/2}$, $\eta^{1/4}$, $\beta^{-1} \log (\beta + 1)$ and $e^{- c t}$. Here, $c$ is a constant and $n$, $\eta$, $\beta$ and $t$ denote the size of the training dataset, learning rate, inverse temperature and time, respectively.
Precipitation Nowcasting With Spatial And Temporal Transfer Learning Using Swin-UNETR
Nov 29, 2023Climate change has led to an increase in frequency of extreme weather events. Early warning systems can prevent disasters and loss of life. Managing such events remain a challenge for both public and private institutions. Precipitation nowcasting can help relevant institutions to better prepare for such events. Numerical weather prediction (NWP) has traditionally been used to make physics based forecasting, and recently deep learning based approaches have been used to reduce turn-around time for nowcasting. In this work, recently proposed Swin-UNETR (Swin UNEt TRansformer) is used for precipitation nowcasting for ten different regions of Europe. Swin-UNETR utilizes a U-shaped network within which a swin transformer-based encoder extracts multi-scale features from multiple input channels of satellite image, while CNN-based decoder makes the prediction. Trained model is capable of nowcasting not only for the regions for which data is available, but can also be used for new regions for which data is not available.
A Physics-Guided Bi-Fidelity Fourier-Featured Operator Learning Framework for Predicting Time Evolution of Drag and Lift Coefficients
Nov 07, 2023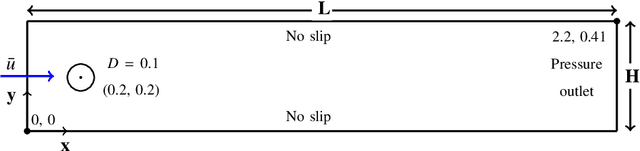

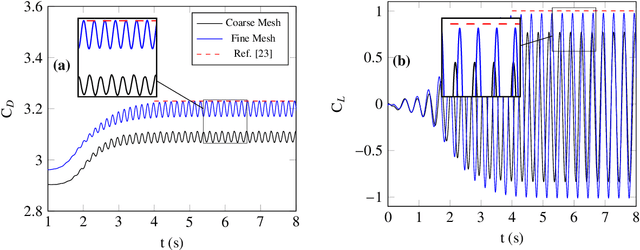

In the pursuit of accurate experimental and computational data while minimizing effort, there is a constant need for high-fidelity results. However, achieving such results often requires significant computational resources. To address this challenge, this paper proposes a deep operator learning-based framework that requires a limited high-fidelity dataset for training. We introduce a novel physics-guided, bi-fidelity, Fourier-featured Deep Operator Network (DeepONet) framework that effectively combines low and high-fidelity datasets, leveraging the strengths of each. In our methodology, we began by designing a physics-guided Fourier-featured DeepONet, drawing inspiration from the intrinsic physical behavior of the target solution. Subsequently, we train this network to primarily learn the low-fidelity solution, utilizing an extensive dataset. This process ensures a comprehensive grasp of the foundational solution patterns. Following this foundational learning, the low-fidelity deep operator network's output is enhanced using a physics-guided Fourier-featured residual deep operator network. This network refines the initial low-fidelity output, achieving the high-fidelity solution by employing a small high-fidelity dataset for training. Notably, in our framework, we employ the Fourier feature network as the Trunk network for the DeepONets, given its proficiency in capturing and learning the oscillatory nature of the target solution with high precision. We validate our approach using a well-known 2D benchmark cylinder problem, which aims to predict the time trajectories of lift and drag coefficients. The results highlight that the physics-guided Fourier-featured deep operator network, serving as a foundational building block of our framework, possesses superior predictive capability for the lift and drag coefficients compared to its data-driven counterparts.
MST-GAT: A Multimodal Spatial-Temporal Graph Attention Network for Time Series Anomaly Detection
Oct 17, 2023Multimodal time series (MTS) anomaly detection is crucial for maintaining the safety and stability of working devices (e.g., water treatment system and spacecraft), whose data are characterized by multivariate time series with diverse modalities. Although recent deep learning methods show great potential in anomaly detection, they do not explicitly capture spatial-temporal relationships between univariate time series of different modalities, resulting in more false negatives and false positives. In this paper, we propose a multimodal spatial-temporal graph attention network (MST-GAT) to tackle this problem. MST-GAT first employs a multimodal graph attention network (M-GAT) and a temporal convolution network to capture the spatial-temporal correlation in multimodal time series. Specifically, M-GAT uses a multi-head attention module and two relational attention modules (i.e., intra- and inter-modal attention) to model modal correlations explicitly. Furthermore, MST-GAT optimizes the reconstruction and prediction modules simultaneously. Experimental results on four multimodal benchmarks demonstrate that MST-GAT outperforms the state-of-the-art baselines. Further analysis indicates that MST-GAT strengthens the interpretability of detected anomalies by locating the most anomalous univariate time series.
Object Detector Differences when using Synthetic and Real Training Data
Dec 01, 2023To train well-performing generalizing neural networks, sufficiently large and diverse datasets are needed. Collecting data while adhering to privacy legislation becomes increasingly difficult and annotating these large datasets is both a resource-heavy and time-consuming task. An approach to overcome these difficulties is to use synthetic data since it is inherently scalable and can be automatically annotated. However, how training on synthetic data affects the layers of a neural network is still unclear. In this paper, we train the YOLOv3 object detector on real and synthetic images from city environments. We perform a similarity analysis using Centered Kernel Alignment (CKA) to explore the effects of training on synthetic data on a layer-wise basis. The analysis captures the architecture of the detector while showing both different and similar patterns between different models. With this similarity analysis we want to give insights on how training synthetic data affects each layer and to give a better understanding of the inner workings of complex neural networks. The results show that the largest similarity between a detector trained on real data and a detector trained on synthetic data was in the early layers, and the largest difference was in the head part. The results also show that no major difference in performance or similarity could be seen between frozen and unfrozen backbone.
* 27 pages. The Version of Record of this article is published in Springer Nature Computer Science 2023, and is available online at https://doi.org/10.1007/s42979-023-01704-5
Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Dec 01, 2023We pursue the goal of developing robots that can interact zero-shot with generic unseen objects via a diverse repertoire of manipulation skills and show how passive human videos can serve as a rich source of data for learning such generalist robots. Unlike typical robot learning approaches which directly learn how a robot should act from interaction data, we adopt a factorized approach that can leverage large-scale human videos to learn how a human would accomplish a desired task (a human plan), followed by translating this plan to the robots embodiment. Specifically, we learn a human plan predictor that, given a current image of a scene and a goal image, predicts the future hand and object configurations. We combine this with a translation module that learns a plan-conditioned robot manipulation policy, and allows following humans plans for generic manipulation tasks in a zero-shot manner with no deployment-time training. Importantly, while the plan predictor can leverage large-scale human videos for learning, the translation module only requires a small amount of in-domain data, and can generalize to tasks not seen during training. We show that our learned system can perform over 16 manipulation skills that generalize to 40 objects, encompassing 100 real-world tasks for table-top manipulation and diverse in-the-wild manipulation. https://homangab.github.io/hopman/