 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023
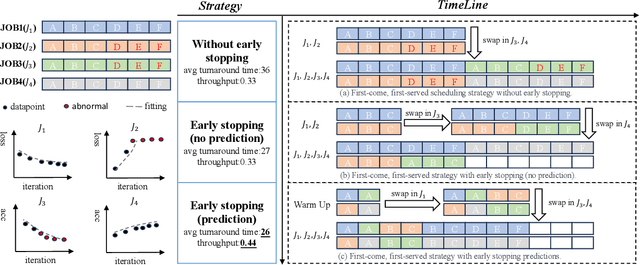
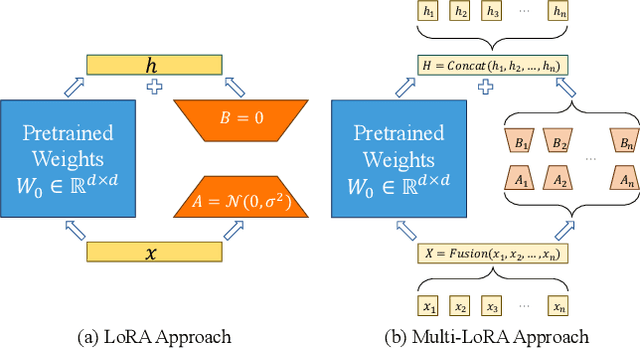
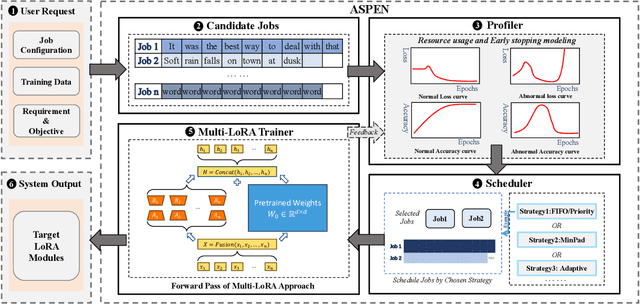
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.
A Multi-In-Single-Out Network for Video Frame Interpolation without Optical Flow
Dec 05, 2023In general, deep learning-based video frame interpolation (VFI) methods have predominantly focused on estimating motion vectors between two input frames and warping them to the target time. While this approach has shown impressive performance for linear motion between two input frames, it exhibits limitations when dealing with occlusions and nonlinear movements. Recently, generative models have been applied to VFI to address these issues. However, as VFI is not a task focused on generating plausible images, but rather on predicting accurate intermediate frames between two given frames, performance limitations still persist. In this paper, we propose a multi-in-single-out (MISO) based VFI method that does not rely on motion vector estimation, allowing it to effectively model occlusions and nonlinear motion. Additionally, we introduce a novel motion perceptual loss that enables MISO-VFI to better capture the spatio-temporal correlations within the video frames. Our MISO-VFI method achieves state-of-the-art results on VFI benchmarks Vimeo90K, Middlebury, and UCF101, with a significant performance gap compared to existing approaches.
Rethinking Adversarial Training with Neural Tangent Kernel
Dec 04, 2023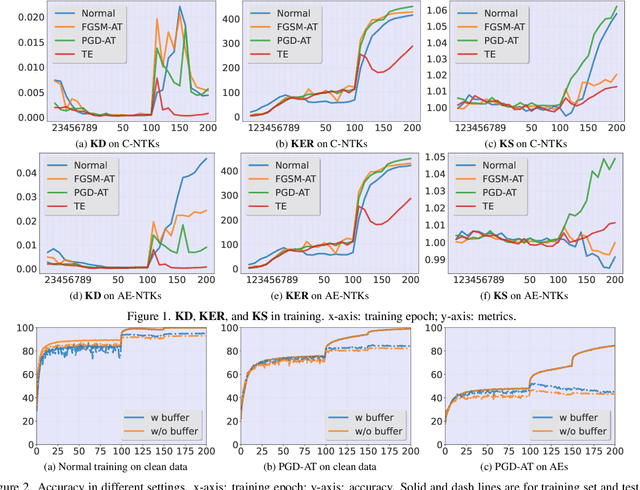
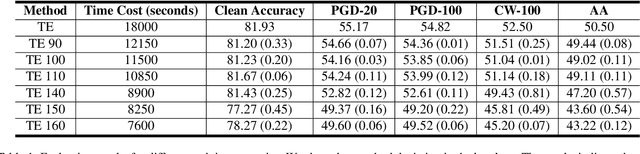

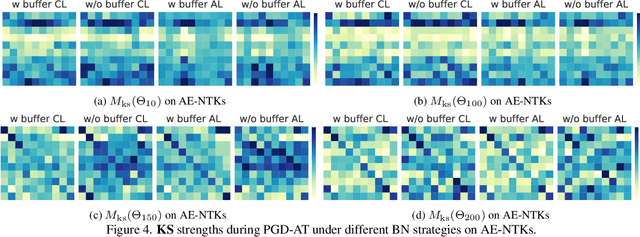
Adversarial training (AT) is an important and attractive topic in deep learning security, exhibiting mysteries and odd properties. Recent studies of neural network training dynamics based on Neural Tangent Kernel (NTK) make it possible to reacquaint AT and deeply analyze its properties. In this paper, we perform an in-depth investigation of AT process and properties with NTK, such as NTK evolution. We uncover three new findings that are missed in previous works. First, we disclose the impact of data normalization on AT and the importance of unbiased estimators in batch normalization layers. Second, we experimentally explore the kernel dynamics and propose more time-saving AT methods. Third, we study the spectrum feature inside the kernel to address the catastrophic overfitting problem. To the best of our knowledge, it is the first work leveraging the observations of kernel dynamics to improve existing AT methods.
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Dec 04, 2023Foundation models, specifically Large Language Models (LLM's), have lately gained wide-spread attention and adoption. Reinforcement Learning with Human Feedback (RLHF) involves training a reward model to capture desired behaviors, which is then used to align LLM's. These reward models are additionally used at inference-time to estimate LLM responses' adherence to those desired behaviors. However, there is little work measuring how robust these reward models are to distribution shifts. In this work, we evaluate how reward model performance - measured via accuracy and calibration (i.e. alignment between accuracy and confidence) - is affected by distribution shift. We show novel calibration patterns and accuracy drops due to OOD prompts and responses, and that the reward model is more sensitive to shifts in responses than prompts. Additionally, we adapt an OOD detection technique commonly used in classification to the reward model setting to detect these distribution shifts in prompts and responses.
Authoring Worked Examples for Java Programming with Human-AI Collaboration
Dec 04, 2023Worked examples (solutions to typical programming problems presented as a source code in a certain language and are used to explain the topics from a programming class) are among the most popular types of learning content in programming classes. Most approaches and tools for presenting these examples to students are based on line-by-line explanations of the example code. However, instructors rarely have time to provide line-by-line explanations for a large number of examples typically used in a programming class. In this paper, we explore and assess a human-AI collaboration approach to authoring worked examples for Java programming. We introduce an authoring system for creating Java worked examples that generates a starting version of code explanations and presents it to the instructor to edit if necessary. We also present a study that assesses the quality of explanations created with this approach.
Extended Deep Adaptive Input Normalization for Preprocessing Time Series Data for Neural Networks
Oct 23, 2023Data preprocessing is a crucial part of any machine learning pipeline, and it can have a significant impact on both performance and training efficiency. This is especially evident when using deep neural networks for time series prediction and classification: real-world time series data often exhibit irregularities such as multi-modality, skewness and outliers, and the model performance can degrade rapidly if these characteristics are not adequately addressed. In this work, we propose the EDAIN (Extended Deep Adaptive Input Normalization) layer, a novel adaptive neural layer that learns how to appropriately normalize irregular time series data for a given task in an end-to-end fashion, instead of using a fixed normalization scheme. This is achieved by optimizing its unknown parameters simultaneously with the deep neural network using back-propagation. Our experiments, conducted using synthetic data, a credit default prediction dataset, and a large-scale limit order book benchmark dataset, demonstrate the superior performance of the EDAIN layer when compared to conventional normalization methods and existing adaptive time series preprocessing layers.
Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Nov 29, 2023Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce hash-encoded shape and appearance to speed up training and propose time-dependent ambient occlusion to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method outperforms existing methods in terms of training time, rendering speed, and reconstruction quality. Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.
ROSO: Improving Robotic Policy Inference via Synthetic Observations
Nov 29, 2023In this paper, we propose the use of generative artificial intelligence (AI) to improve zero-shot performance of a pre-trained policy by altering observations during inference. Modern robotic systems, powered by advanced neural networks, have demonstrated remarkable capabilities on pre-trained tasks. However, generalizing and adapting to new objects and environments is challenging, and fine-tuning visuomotor policies is time-consuming. To overcome these issues we propose Robotic Policy Inference via Synthetic Observations (ROSO). ROSO uses stable diffusion to pre-process a robot's observation of novel objects during inference time to fit within its distribution of observations of the pre-trained policies. This novel paradigm allows us to transfer learned knowledge from known tasks to previously unseen scenarios, enhancing the robot's adaptability without requiring lengthy fine-tuning. Our experiments show that incorporating generative AI into robotic inference significantly improves successful outcomes, finishing up to 57% of tasks otherwise unsuccessful with the pre-trained policy.
Zero-Touch Networks: Towards Next-Generation Network Automation
Dec 07, 2023The Zero-touch network and Service Management (ZSM) framework represents an emerging paradigm in the management of the fifth-generation (5G) and Beyond (5G+) networks, offering automated self-management and self-healing capabilities to address the escalating complexity and the growing data volume of modern networks. ZSM frameworks leverage advanced technologies such as Machine Learning (ML) to enable intelligent decision-making and reduce human intervention. This paper presents a comprehensive survey of Zero-Touch Networks (ZTNs) within the ZSM framework, covering network optimization, traffic monitoring, energy efficiency, and security aspects of next-generational networks. The paper explores the challenges associated with ZSM, particularly those related to ML, which necessitate the need to explore diverse network automation solutions. In this context, the study investigates the application of Automated ML (AutoML) in ZTNs, to reduce network management costs and enhance performance. AutoML automates the selection and tuning process of a ML model for a given task. Specifically, the focus is on AutoML's ability to predict application throughput and autonomously adapt to data drift. Experimental results demonstrate the superiority of the proposed AutoML pipeline over traditional ML in terms of prediction accuracy. Integrating AutoML and ZSM concepts significantly reduces network configuration and management efforts, allowing operators to allocate more time and resources to other important tasks. The paper also provides a high-level 5G system architecture incorporating AutoML and ZSM concepts. This research highlights the potential of ZTNs and AutoML to revolutionize the management of 5G+ networks, enabling automated decision-making and empowering network operators to achieve higher efficiency, improved performance, and enhanced user experience.
Comparing Large Language Model AI and Human-Generated Coaching Messages for Behavioral Weight Loss
Dec 07, 2023
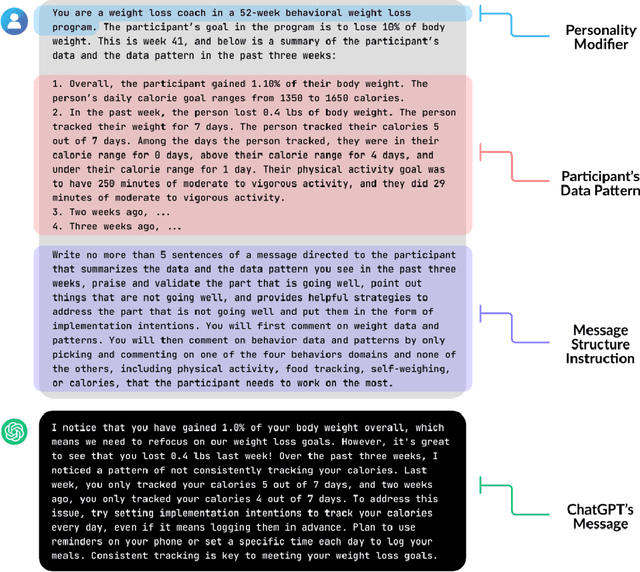


Automated coaching messages for weight control can save time and costs, but their repetitive, generic nature may limit their effectiveness compared to human coaching. Large language model (LLM) based artificial intelligence (AI) chatbots, like ChatGPT, could offer more personalized and novel messages to address repetition with their data-processing abilities. While LLM AI demonstrates promise to encourage healthier lifestyles, studies have yet to examine the feasibility and acceptability of LLM-based BWL coaching. 87 adults in a weight-loss trial rated ten coaching messages' helpfulness (five human-written, five ChatGPT-generated) using a 5-point Likert scale, providing additional open-ended feedback to justify their ratings. Participants also identified which messages they believed were AI-generated. The evaluation occurred in two phases: messages in Phase 1 were perceived as impersonal and negative, prompting revisions for Phase 2 messages. In Phase 1, AI-generated messages were rated less helpful than human-written ones, with 66 percent receiving a helpfulness rating of 3 or higher. However, in Phase 2, the AI messages matched the human-written ones regarding helpfulness, with 82% scoring three or above. Additionally, 50% were misidentified as human-written, suggesting AI's sophistication in mimicking human-generated content. A thematic analysis of open-ended feedback revealed that participants appreciated AI's empathy and personalized suggestions but found them more formulaic, less authentic, and too data-focused. This study reveals the preliminary feasibility and acceptability of LLM AIs, like ChatGPT, in crafting potentially effective weight control coaching messages. Our findings also underscore areas for future enhancement.