 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Detection Algorithm for Multiple Cognitive Users in Spectrum Sensing
Nov 30, 2023
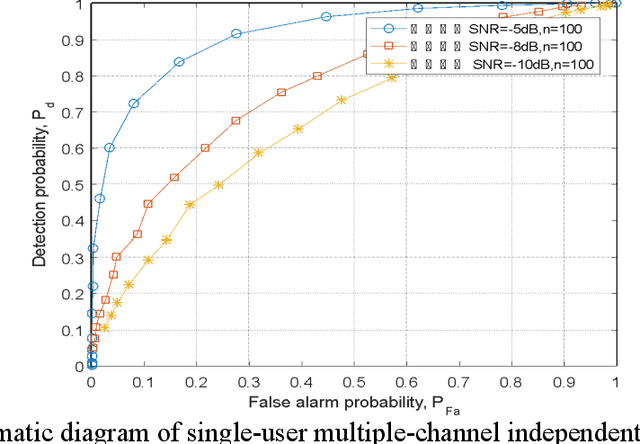
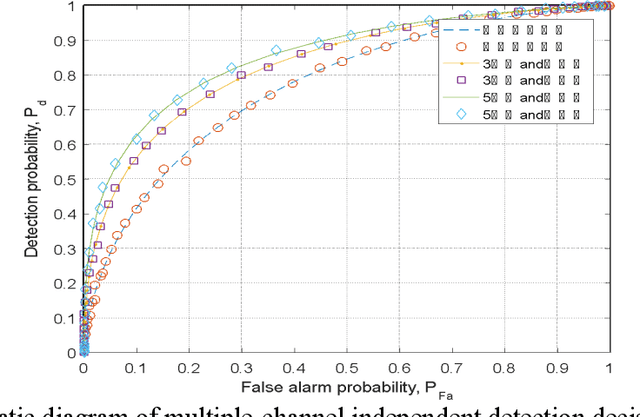
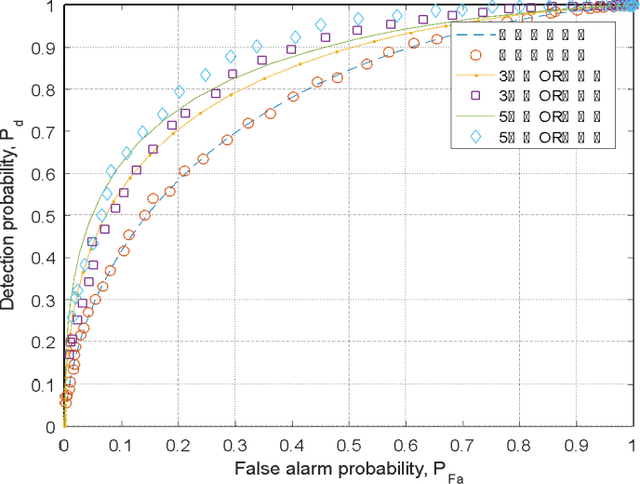
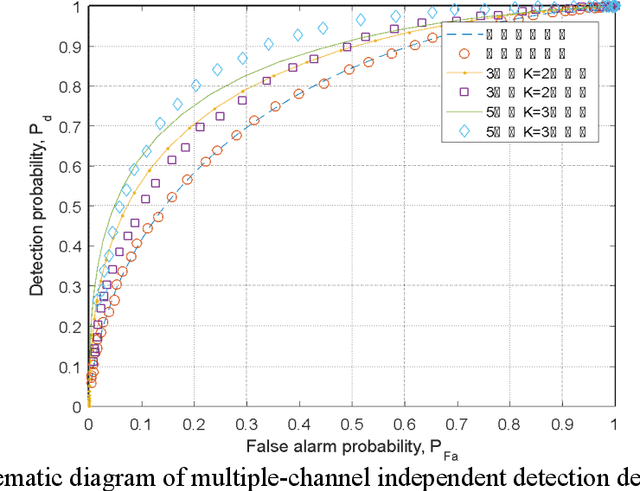
Spectrum sensing technology is a crucial aspect of modern communication technology, serving as one of the essential techniques for efficiently utilizing scarce information resources in tight frequency bands. This paper first introduces three common logical circuit decision criteria in hard decisions and analyzes their decision rigor. Building upon hard decisions, the paper further introduces a method for multi-user spectrum sensing based on soft decisions. Then the paper simulates the false alarm probability and detection probability curves corresponding to the three criteria. The simulated results of multi-user collaborative sensing indicate that the simulation process significantly reduces false alarm probability and enhances detection probability. This approach effectively detects spectrum resources unoccupied during idle periods, leveraging the concept of time-division multiplexing and rationalizing the redistribution of information resources. The entire computation process relies on the calculation principles of power spectral density in communication theory, involving threshold decision detection for noise power and the sum of noise and signal power. It provides a secondary decision detection, reflecting the perceptual decision performance of logical detection methods with relative accuracy.
* https://aei.ewapublishing.org/article.html?pk=e24c40d220434209ae2fe2e984bcf2c2
Instructing Hierarchical Tasks to Robots by Verbal Commands
Nov 30, 2023Natural language is an effective tool for communication, as information can be expressed in different ways and at different levels of complexity. Verbal commands, utilized for instructing robot tasks, can therefor replace traditional robot programming techniques, and provide a more expressive means to assign actions and enable collaboration. However, the challenge of utilizing speech for robot programming is how actions and targets can be grounded to physical entities in the world. In addition, to be time-efficient, a balance needs to be found between fine- and course-grained commands and natural language phrases. In this work we provide a framework for instructing tasks to robots by verbal commands. The framework includes functionalities for single commands to actions and targets, as well as longer-term sequences of actions, thereby providing a hierarchical structure to the robot tasks. Experimental evaluation demonstrates the functionalities of the framework by human collaboration with a robot in different tasks, with different levels of complexity. The tools are provided open-source at https://petim44.github.io/voice-jogger/
CLS-CAD: Synthesizing CAD Assemblies in Fusion 360
Nov 30, 2023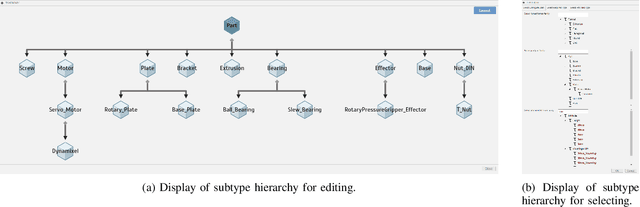
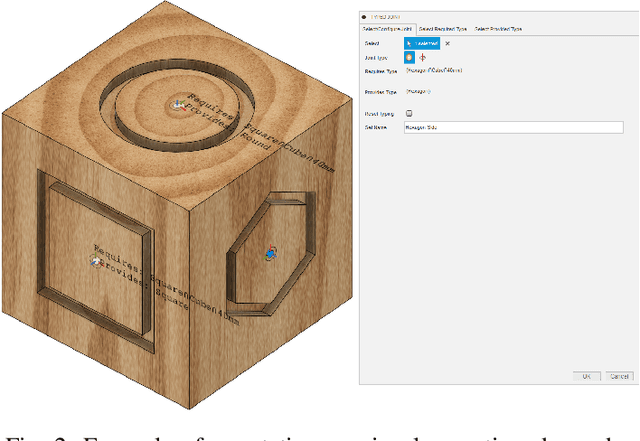
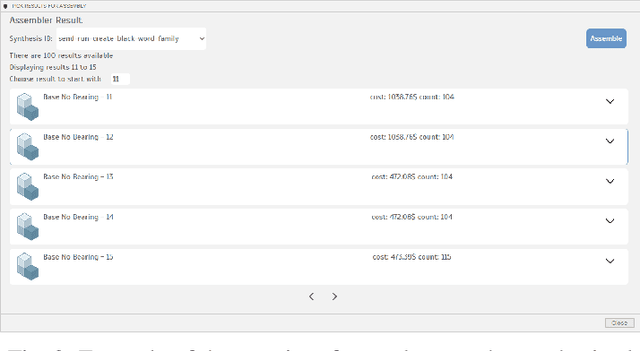
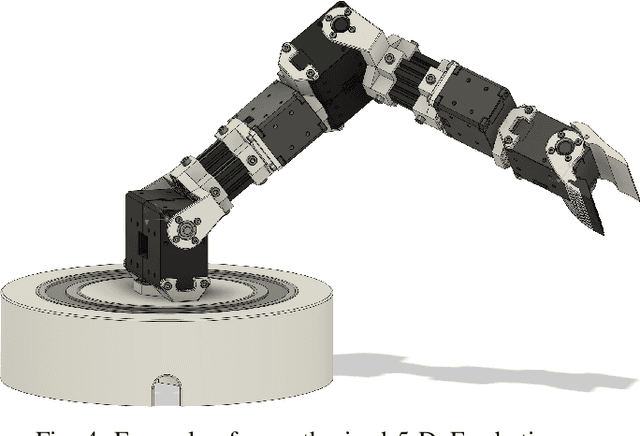
The CAD design process includes a number of repetitive steps when creating assemblies. This issue is compounded when engineering whole product lines or design families, as steps like inserting parts common to all variations, such as fasteners and product-integral base parts, get repeated numerous times. This makes creating designs time-, and as a result, cost-intensive. While many CAD software packages have APIs, the effort of creating use-case specific plugins to automate creation of assemblies usually outweighs the benefit. We developed a plugin for the CAD software package "Fusion 360" which tackles this issue. The plugin adds several graphical interfaces to Fusion 360 that allow parts to be annotated with types, subtype hierarchies to be managed, and requests to synthesize assembly programs for assemblies to be posed. The plugin is use-case agnostic and is able to generate arbitrary open kinematic chain structures. We envision engineers working with CAD software being able to make designed parts reusable and automate the generation of different design alternatives as well as whole product lines.
Simple Semantic-Aided Few-Shot Learning
Nov 30, 2023Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in few-shot learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on five benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks.
Enhanced MIMO-DCT-OFDM System Using Cosine Domain Equalizer
Nov 24, 2023Discrete Cosine Transform (DCT) can be used instead of conventional Discrete Fourier Transform (DFT) for the Orthogonal Frequency Division Multiplexing (OFDM) construction, which offers many advantages. In this paper, the Multiple-Input-Multiple-Output (MIMO) DCT-OFDM is enhanced using a proposed Cosine Domain Equalizer (CDE) instead of a Frequency Domain Equalizer (FDE). The results are evaluated through the Rayleigh fading channel with Co-Carrier Frequency Offset (Co-CFO) of different MIMO configurations. The average bit error probability and the simulated time of the proposed scheme and the conventional one is compared, which indicates the importance of the proposed scheme. Also, a closed formula for the number of arithmetic operations of the proposed equalizer is developed. The proposed equalizer gives a simulation time reduction of about 81.21%, 83.74% compared to that of the conventional LZF-FDE, and LMMSE-FDE, respectively for the case of 4x4 configuration.
Individualized Dynamic Model for Multi-resolutional Data
Nov 22, 2023Mobile health has emerged as a major success in tracking individual health status, due to the popularity and power of smartphones and wearable devices. This has also brought great challenges in handling heterogeneous, multi-resolution data which arise ubiquitously in mobile health due to irregular multivariate measurements collected from individuals. In this paper, we propose an individualized dynamic latent factor model for irregular multi-resolution time series data to interpolate unsampled measurements of time series with low resolution. One major advantage of the proposed method is the capability to integrate multiple irregular time series and multiple subjects by mapping the multi-resolution data to the latent space. In addition, the proposed individualized dynamic latent factor model is applicable to capturing heterogeneous longitudinal information through individualized dynamic latent factors. In theory, we provide the integrated interpolation error bound of the proposed estimator and derive the convergence rate with B-spline approximation methods. Both the simulation studies and the application to smartwatch data demonstrate the superior performance of the proposed method compared to existing methods.
Computer Vision for Carriers: PATRIOT
Nov 27, 2023Deck tracking performed on carriers currently involves a team of sailors manually identifying aircraft and updating a digital user interface called the Ouija Board. Improvements to the deck tracking process would result in increased Sortie Generation Rates, and therefore applying automation is seen as a critical method to improve deck tracking. However, the requirements on a carrier ship do not allow for the installation of hardware-based location sensing technologies like Global Positioning System (GPS) sensors. PATRIOT (Panoramic Asset Tracking of Real-Time Information for the Ouija Tabletop) is a research effort and proposed solution to performing deck tracking with passive sensing and without the need for GPS sensors. PATRIOT is a prototype system which takes existing camera feeds, calculates aircraft poses, and updates a virtual Ouija board interface with the current status of the assets. PATRIOT would allow for faster, more accurate, and less laborious asset tracking for aircraft, people, and support equipment. PATRIOT is anticipated to benefit the warfighter by reducing cognitive workload, reducing manning requirements, collecting data to improve logistics, and enabling an automation gateway for future efforts to improve efficiency and safety. The authors have developed and tested algorithms to perform pose estimations of assets in real-time including OpenPifPaf, High-Resolution Network (HRNet), HigherHRNet (HHRNet), Faster R-CNN, and in-house developed encoder-decoder network. The software was tested with synthetic and real-world data and was able to accurately extract the pose of assets. Fusion, tracking, and real-world generality are planned to be improved to ensure a successful transition to the fleet.
A decoder-only foundation model for time-series forecasting
Oct 14, 2023Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
A Comprehensive Python Library for Deep Learning-Based Event Detection in Multivariate Time Series Data and Information Retrieval in NLP
Oct 25, 2023Event detection in time series data is crucial in various domains, including finance, healthcare, cybersecurity, and science. Accurately identifying events in time series data is vital for making informed decisions, detecting anomalies, and predicting future trends. Despite extensive research exploring diverse methods for event detection in time series, with deep learning approaches being among the most advanced, there is still room for improvement and innovation in this field. In this paper, we present a new deep learning supervised method for detecting events in multivariate time series data. Our method combines four distinct novelties compared to existing deep-learning supervised methods. Firstly, it is based on regression instead of binary classification. Secondly, it does not require labeled datasets where each point is labeled; instead, it only requires reference events defined as time points or intervals of time. Thirdly, it is designed to be robust by using a stacked ensemble learning meta-model that combines deep learning models, ranging from classic feed-forward neural networks (FFNs) to state-of-the-art architectures like transformers. This ensemble approach can mitigate individual model weaknesses and biases, resulting in more robust predictions. Finally, to facilitate practical implementation, we have developed a Python package to accompany our proposed method. The package, called eventdetector-ts, can be installed through the Python Package Index (PyPI). In this paper, we present our method and provide a comprehensive guide on the usage of the package. We showcase its versatility and effectiveness through different real-world use cases from natural language processing (NLP) to financial security domains.
Threat-Based Resource Allocation Strategy for Target Tracking in a Cognitive Radar Network
Nov 23, 2023Cognitive radar is developed to utilize the feedback of its operating environment obtained from a beam to make resource allocation decisions by solving optimization problems. Previous works focused on target tracking accuracy by designing an evaluation metric for an optimization problem. However, in a real combat situation, not only the tracking performance of the target but also its operational perspective should be considered. In this study, the usage of threats in the allocation of radar resource is proposed for a cognitive radar framework. Resource allocation regarding radar dwell time is considered to reflect the operational importance of target effects. The dwell time allocation problem is solved using a Second-Order Cone Program (SOCP). Numerical simulations are performed to verify the effectiveness of the proposed framework.