 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporally Robust Multi-Agent STL Motion Planning in Continuous Time
Oct 16, 2023
Signal Temporal Logic (STL) is a formal language over continuous-time signals (such as trajectories of a multi-agent system) that allows for the specification of complex spatial and temporal system requirements (such as staying sufficiently close to each other within certain time intervals). To promote robustness in multi-agent motion planning with such complex requirements, we consider motion planning with the goal of maximizing the temporal robustness of their joint STL specification, i.e. maximizing the permissible time shifts of each agent's trajectory while still satisfying the STL specification. Previous methods presented temporally robust motion planning and control in a discrete-time Mixed Integer Linear Programming (MILP) optimization scheme. In contrast, we parameterize the trajectory by continuous B\'ezier curves, where the curvature and the time-traversal of the trajectory are parameterized individually. We show an algorithm generating continuous-time temporally robust trajectories and prove soundness of our approach. Moreover, we empirically show that our parametrization realizes this with a considerable speed-up compared to state-of-the-art methods based on constant interval time discretization.
A Probabilistic Neural Twin for Treatment Planning in Peripheral Pulmonary Artery Stenosis
Dec 01, 2023The substantial computational cost of high-fidelity models in numerical hemodynamics has, so far, relegated their use mainly to offline treatment planning. New breakthroughs in data-driven architectures and optimization techniques for fast surrogate modeling provide an exciting opportunity to overcome these limitations, enabling the use of such technology for time-critical decisions. We discuss an application to the repair of multiple stenosis in peripheral pulmonary artery disease through either transcatheter pulmonary artery rehabilitation or surgery, where it is of interest to achieve desired pressures and flows at specific locations in the pulmonary artery tree, while minimizing the risk for the patient. Since different degrees of success can be achieved in practice during treatment, we formulate the problem in probability, and solve it through a sample-based approach. We propose a new offline-online pipeline for probabilsitic real-time treatment planning which combines offline assimilation of boundary conditions, model reduction, and training dataset generation with online estimation of marginal probabilities, possibly conditioned on the degree of augmentation observed in already repaired lesions. Moreover, we propose a new approach for the parametrization of arbitrarily shaped vascular repairs through iterative corrections of a zero-dimensional approximant. We demonstrate this pipeline for a diseased model of the pulmonary artery tree available through the Vascular Model Repository.
Backbone-based Dynamic Graph Spatio-Temporal Network for Epidemic Forecasting
Dec 01, 2023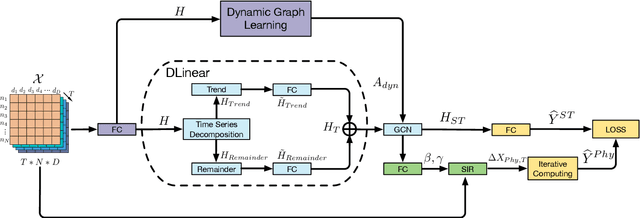

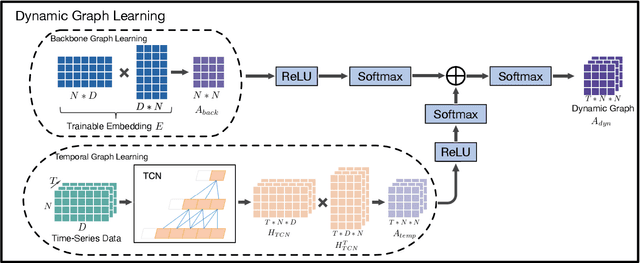
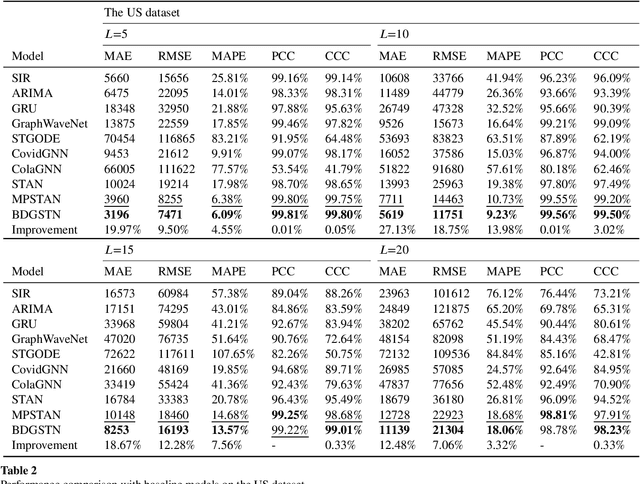
Accurate epidemic forecasting is a critical task in controlling disease transmission. Many deep learning-based models focus only on static or dynamic graphs when constructing spatial information, ignoring their relationship. Additionally, these models often rely on recurrent structures, which can lead to error accumulation and computational time consumption. To address the aforementioned problems, we propose a novel model called Backbone-based Dynamic Graph Spatio-Temporal Network (BDGSTN). Intuitively, the continuous and smooth changes in graph structure, make adjacent graph structures share a basic pattern. To capture this property, we use adaptive methods to generate static backbone graphs containing the primary information and temporal models to generate dynamic temporal graphs of epidemic data, fusing them to generate a backbone-based dynamic graph. To overcome potential limitations associated with recurrent structures, we introduce a linear model DLinear to handle temporal dependencies and combine it with dynamic graph convolution for epidemic forecasting. Extensive experiments on two datasets demonstrate that BDGSTN outperforms baseline models and ablation comparison further verifies the effectiveness of model components. Furthermore, we analyze and measure the significance of backbone and temporal graphs by using information metrics from different aspects. Finally, we compare model parameter volume and training time to confirm the superior complexity and efficiency of BDGSTN.
Optimization Landscape of Policy Gradient Methods for Discrete-time Static Output Feedback
Oct 29, 2023In recent times, significant advancements have been made in delving into the optimization landscape of policy gradient methods for achieving optimal control in linear time-invariant (LTI) systems. Compared with state-feedback control, output-feedback control is more prevalent since the underlying state of the system may not be fully observed in many practical settings. This paper analyzes the optimization landscape inherent to policy gradient methods when applied to static output feedback (SOF) control in discrete-time LTI systems subject to quadratic cost. We begin by establishing crucial properties of the SOF cost, encompassing coercivity, L-smoothness, and M-Lipschitz continuous Hessian. Despite the absence of convexity, we leverage these properties to derive novel findings regarding convergence (and nearly dimension-free rate) to stationary points for three policy gradient methods, including the vanilla policy gradient method, the natural policy gradient method, and the Gauss-Newton method. Moreover, we provide proof that the vanilla policy gradient method exhibits linear convergence towards local minima when initialized near such minima. The paper concludes by presenting numerical examples that validate our theoretical findings. These results not only characterize the performance of gradient descent for optimizing the SOF problem but also provide insights into the effectiveness of general policy gradient methods within the realm of reinforcement learning.
Solving the Team Orienteering Problem with Transformers
Nov 30, 2023Route planning for a fleet of vehicles is an important task in applications such as package delivery, surveillance, or transportation. This problem is usually modeled as a Combinatorial Optimization problem named as Team Orienteering Problem. The most popular Team Orienteering Problem solvers are mainly based on either linear programming, which provides accurate solutions by employing a large computation time that grows with the size of the problem, or heuristic methods, which usually find suboptimal solutions in a shorter amount of time. In this paper, a multi-agent route planning system capable of solving the Team Orienteering Problem in a very fast and accurate manner is presented. The proposed system is based on a centralized Transformer neural network that can learn to encode the scenario (modeled as a graph) and the context of the agents to provide fast and accurate solutions. Several experiments have been performed to demonstrate that the presented system can outperform most of the state-of-the-art works in terms of computation speed. In addition, the code is publicly available at \url{http://gti.ssr.upm.es/data}.
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.
Online Change Points Detection for Linear Dynamical Systems with Finite Sample Guarantees
Nov 30, 2023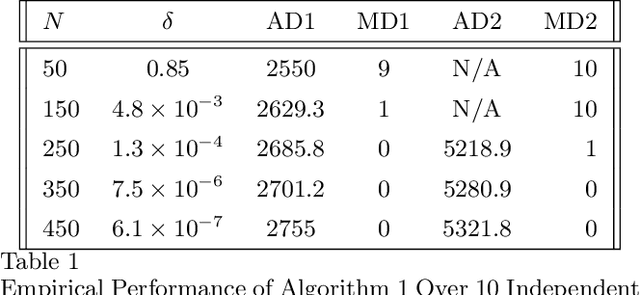
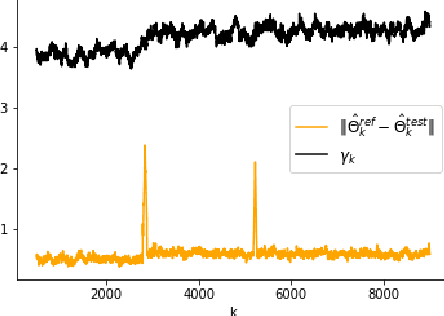
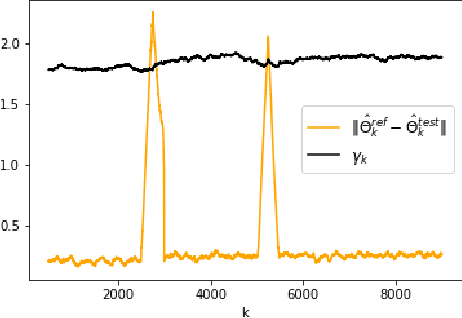
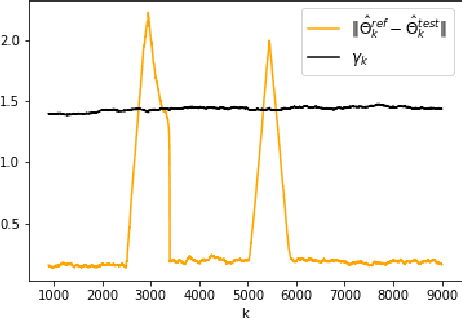
The problem of online change point detection is to detect abrupt changes in properties of time series, ideally as soon as possible after those changes occur. Existing work on online change point detection either assumes i.i.d data, focuses on asymptotic analysis, does not present theoretical guarantees on the trade-off between detection accuracy and detection delay, or is only suitable for detecting single change points. In this work, we study the online change point detection problem for linear dynamical systems with unknown dynamics, where the data exhibits temporal correlations and the system could have multiple change points. We develop a data-dependent threshold that can be used in our test that allows one to achieve a pre-specified upper bound on the probability of making a false alarm. We further provide a finite-sample-based bound for the probability of detecting a change point. Our bound demonstrates how parameters used in our algorithm affect the detection probability and delay, and provides guidance on the minimum required time between changes to guarantee detection.
A Systematic Review of Aspect-based Sentiment Analysis (ABSA): Domains, Methods, and Trends
Dec 03, 2023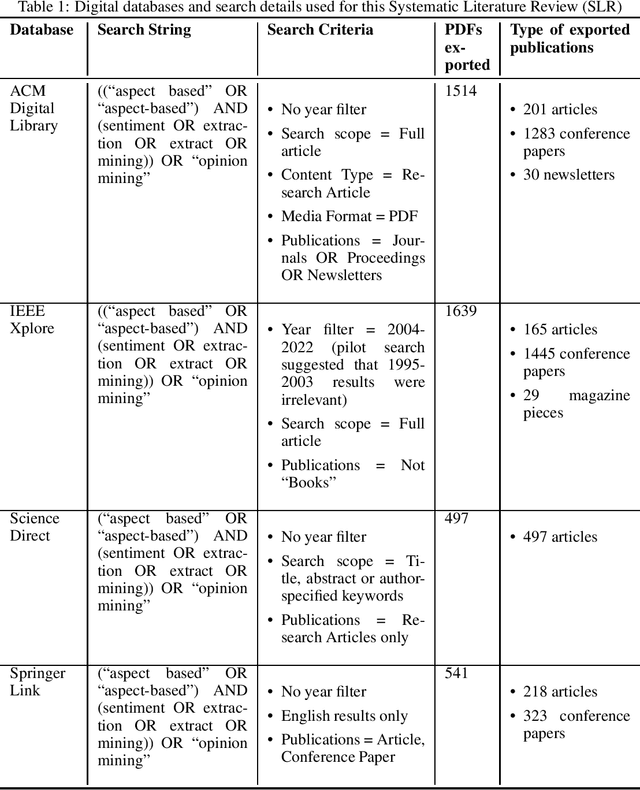
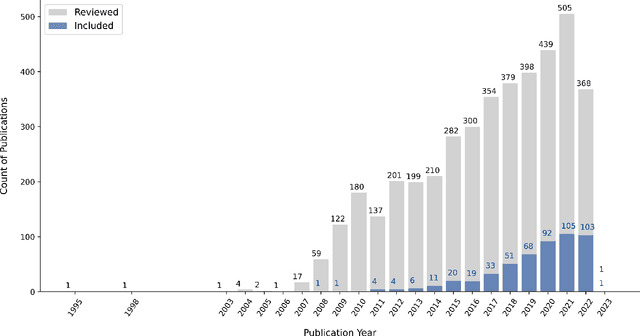
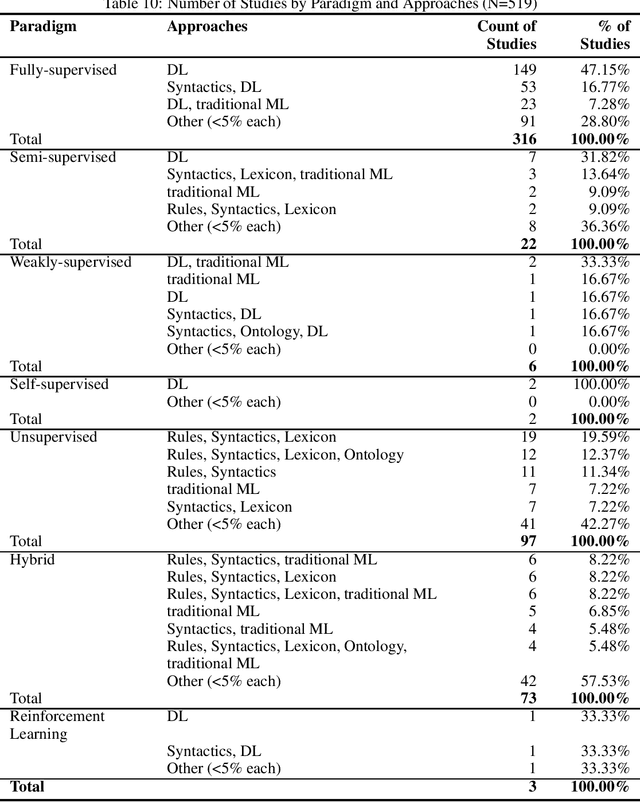
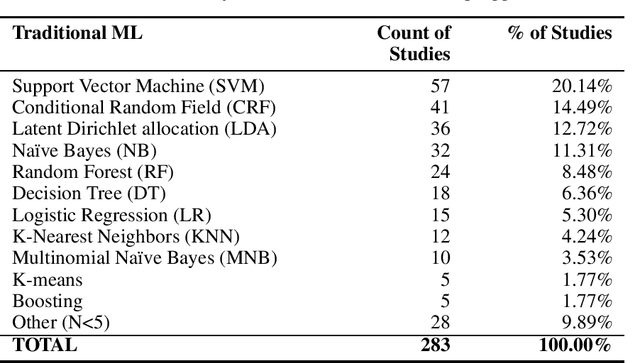
Aspect-based Sentiment Analysis (ABSA) is a type of fine-grained sentiment analysis (SA) that identifies aspects and the associated opinions from a given text. In the digital era, ABSA gained increasing popularity and applications in mining opinionated text data to obtain insights and support decisions. ABSA research employs linguistic, statistical, and machine-learning approaches and utilises resources such as labelled datasets, aspect and sentiment lexicons and ontology. By its nature, ABSA is domain-dependent and can be sensitive to the impact of misalignment between the resource and application domains. However, to our knowledge, this topic has not been explored by the existing ABSA literature reviews. In this paper, we present a Systematic Literature Review (SLR) of ABSA studies with a focus on the research application domain, dataset domain, and the research methods to examine their relationships and identify trends over time. Our results suggest a number of potential systemic issues in the ABSA research literature, including the predominance of the ``product/service review'' dataset domain among the majority of studies that did not have a specific research application domain, coupled with the prevalence of dataset-reliant methods such as supervised machine learning. This review makes a number of unique contributions to the ABSA research field: 1) To our knowledge, it is the first SLR that links the research domain, dataset domain, and research method through a systematic perspective; 2) it is one of the largest scoped SLR on ABSA, with 519 eligible studies filtered from 4191 search results without time constraint; and 3) our review methodology adopted an innovative automatic filtering process based on PDF-mining, which enhanced screening quality and reliability. Suggestions and our review limitations are also discussed.
ALSTER: A Local Spatio-Temporal Expert for Online 3D Semantic Reconstruction
Dec 03, 2023We propose an online 3D semantic segmentation method that incrementally reconstructs a 3D semantic map from a stream of RGB-D frames. Unlike offline methods, ours is directly applicable to scenarios with real-time constraints, such as robotics or mixed reality. To overcome the inherent challenges of online methods, we make two main contributions. First, to effectively extract information from the input RGB-D video stream, we jointly estimate geometry and semantic labels per frame in 3D. A key focus of our approach is to reason about semantic entities both in the 2D input and the local 3D domain to leverage differences in spatial context and network architectures. Our method predicts 2D features using an off-the-shelf segmentation network. The extracted 2D features are refined by a lightweight 3D network to enable reasoning about the local 3D structure. Second, to efficiently deal with an infinite stream of input RGB-D frames, a subsequent network serves as a temporal expert predicting the incremental scene updates by leveraging 2D, 3D, and past information in a learned manner. These updates are then integrated into a global scene representation. Using these main contributions, our method can enable scenarios with real-time constraints and can scale to arbitrary scene sizes by processing and updating the scene only in a local region defined by the new measurement. Our experiments demonstrate improved results compared to existing online methods that purely operate in local regions and show that complementary sources of information can boost the performance. We provide a thorough ablation study on the benefits of different architectural as well as algorithmic design decisions. Our method yields competitive results on the popular ScanNet benchmark and SceneNN dataset.
Caregiver Talk Shapes Toddler Vision: A Computational Study of Dyadic Play
Dec 07, 2023Infants' ability to recognize and categorize objects develops gradually. The second year of life is marked by both the emergence of more semantic visual representations and a better understanding of word meaning. This suggests that language input may play an important role in shaping visual representations. However, even in suitable contexts for word learning like dyadic play sessions, caregivers utterances are sparse and ambiguous, often referring to objects that are different from the one to which the child attends. Here, we systematically investigate to what extent caregivers' utterances can nevertheless enhance visual representations. For this we propose a computational model of visual representation learning during dyadic play. We introduce a synthetic dataset of ego-centric images perceived by a toddler-agent that moves and rotates toy objects in different parts of its home environment while hearing caregivers' utterances, modeled as captions. We propose to model toddlers' learning as simultaneously aligning representations for 1) close-in-time images and 2) co-occurring images and utterances. We show that utterances with statistics matching those of real caregivers give rise to representations supporting improved category recognition. Our analysis reveals that a small decrease/increase in object-relevant naming frequencies can drastically impact the learned representations. This affects the attention on object names within an utterance, which is required for efficient visuo-linguistic alignment. Overall, our results support the hypothesis that caregivers' naming utterances can improve toddlers' visual representations.