 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023
Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
Generalizable Neural Physics Solvers by Baldwinian Evolution
Dec 06, 2023Physics-informed neural networks (PINNs) are at the forefront of scientific machine learning, making possible the creation of machine intelligence that is cognizant of physical laws and able to accurately simulate them. In this paper, the potential of discovering PINNs that generalize over an entire family of physics tasks is studied, for the first time, through a biological lens of the Baldwin effect. Drawing inspiration from the neurodevelopment of precocial species that have evolved to learn, predict and react quickly to their environment, we envision PINNs that are pre-wired with connection strengths inducing strong biases towards efficient learning of physics. To this end, evolutionary selection pressure (guided by proficiency over a family of tasks) is coupled with lifetime learning (to specialize on a smaller subset of those tasks) to produce PINNs that demonstrate fast and physics-compliant prediction capabilities across a range of empirically challenging problem instances. The Baldwinian approach achieves an order of magnitude improvement in prediction accuracy at a fraction of the computation cost compared to state-of-the-art results with PINNs meta-learned by gradient descent. This paper marks a leap forward in the meta-learning of PINNs as generalizable physics solvers.
MACCA: Offline Multi-agent Reinforcement Learning with Causal Credit Assignment
Dec 06, 2023Offline Multi-agent Reinforcement Learning (MARL) is valuable in scenarios where online interaction is impractical or risky. While independent learning in MARL offers flexibility and scalability, accurately assigning credit to individual agents in offline settings poses challenges due to partial observability and emergent behavior. Directly transferring the online credit assignment method to offline settings results in suboptimal outcomes due to the absence of real-time feedback and intricate agent interactions. Our approach, MACCA, characterizing the generative process as a Dynamic Bayesian Network, captures relationships between environmental variables, states, actions, and rewards. Estimating this model on offline data, MACCA can learn each agent's contribution by analyzing the causal relationship of their individual rewards, ensuring accurate and interpretable credit assignment. Additionally, the modularity of our approach allows it to seamlessly integrate with various offline MARL methods. Theoretically, we proved that under the setting of the offline dataset, the underlying causal structure and the function for generating the individual rewards of agents are identifiable, which laid the foundation for the correctness of our modeling. Experimentally, we tested MACCA in two environments, including discrete and continuous action settings. The results show that MACCA outperforms SOTA methods and improves performance upon their backbones.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
FaceStudio: Put Your Face Everywhere in Seconds
Dec 06, 2023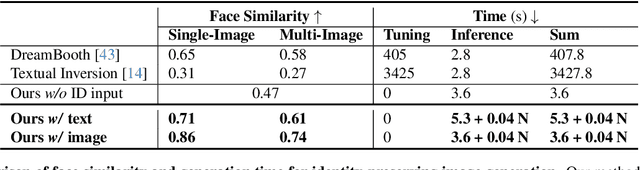
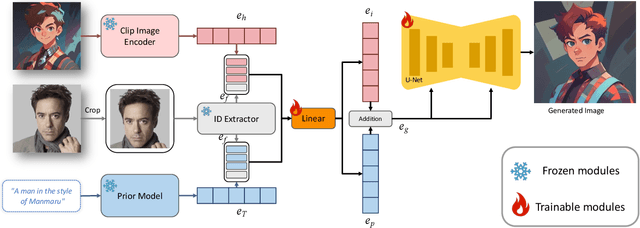
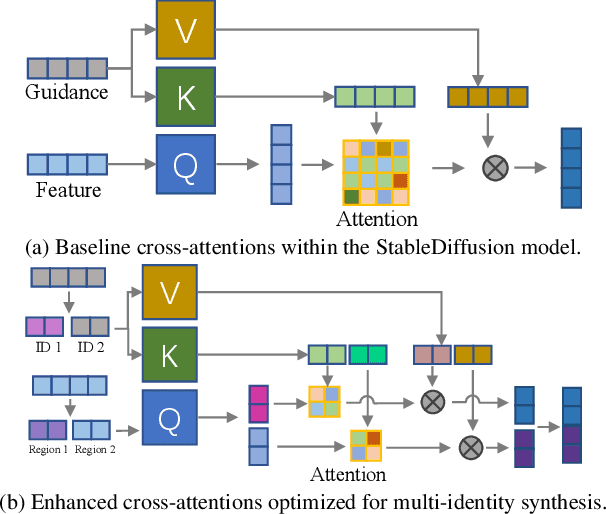

This study investigates identity-preserving image synthesis, an intriguing task in image generation that seeks to maintain a subject's identity while adding a personalized, stylistic touch. Traditional methods, such as Textual Inversion and DreamBooth, have made strides in custom image creation, but they come with significant drawbacks. These include the need for extensive resources and time for fine-tuning, as well as the requirement for multiple reference images. To overcome these challenges, our research introduces a novel approach to identity-preserving synthesis, with a particular focus on human images. Our model leverages a direct feed-forward mechanism, circumventing the need for intensive fine-tuning, thereby facilitating quick and efficient image generation. Central to our innovation is a hybrid guidance framework, which combines stylized images, facial images, and textual prompts to guide the image generation process. This unique combination enables our model to produce a variety of applications, such as artistic portraits and identity-blended images. Our experimental results, including both qualitative and quantitative evaluations, demonstrate the superiority of our method over existing baseline models and previous works, particularly in its remarkable efficiency and ability to preserve the subject's identity with high fidelity.
Universal Segmentation at Arbitrary Granularity with Language Instruction
Dec 06, 2023This paper aims to achieve universal segmentation of arbitrary semantic level. Despite significant progress in recent years, specialist segmentation approaches are limited to specific tasks and data distribution. Retraining a new model for adaptation to new scenarios or settings takes expensive computation and time cost, which raises the demand for versatile and universal segmentation model that can cater to various granularity. Although some attempts have been made for unifying different segmentation tasks or generalization to various scenarios, limitations in the definition of paradigms and input-output spaces make it difficult for them to achieve accurate understanding of content at arbitrary granularity. To this end, we present UniLSeg, a universal segmentation model that can perform segmentation at any semantic level with the guidance of language instructions. For training UniLSeg, we reorganize a group of tasks from original diverse distributions into a unified data format, where images with texts describing segmentation targets as input and corresponding masks are output. Combined with a automatic annotation engine for utilizing numerous unlabeled data, UniLSeg achieves excellent performance on various tasks and settings, surpassing both specialist and unified segmentation models.
Temporally Robust Multi-Agent STL Motion Planning in Continuous Time
Oct 16, 2023Signal Temporal Logic (STL) is a formal language over continuous-time signals (such as trajectories of a multi-agent system) that allows for the specification of complex spatial and temporal system requirements (such as staying sufficiently close to each other within certain time intervals). To promote robustness in multi-agent motion planning with such complex requirements, we consider motion planning with the goal of maximizing the temporal robustness of their joint STL specification, i.e. maximizing the permissible time shifts of each agent's trajectory while still satisfying the STL specification. Previous methods presented temporally robust motion planning and control in a discrete-time Mixed Integer Linear Programming (MILP) optimization scheme. In contrast, we parameterize the trajectory by continuous B\'ezier curves, where the curvature and the time-traversal of the trajectory are parameterized individually. We show an algorithm generating continuous-time temporally robust trajectories and prove soundness of our approach. Moreover, we empirically show that our parametrization realizes this with a considerable speed-up compared to state-of-the-art methods based on constant interval time discretization.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023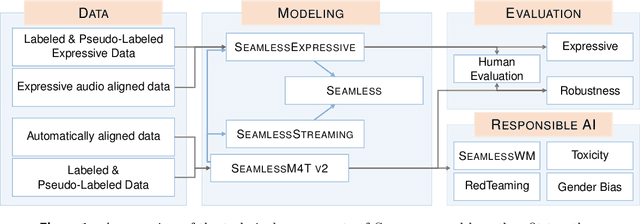
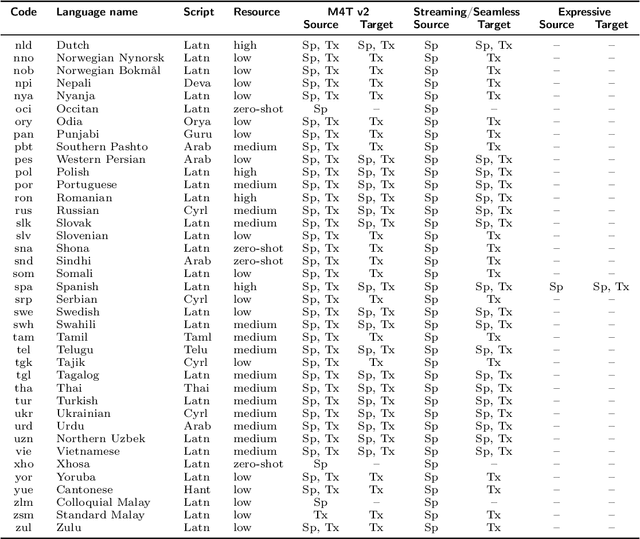
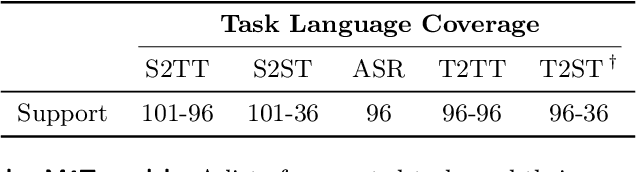
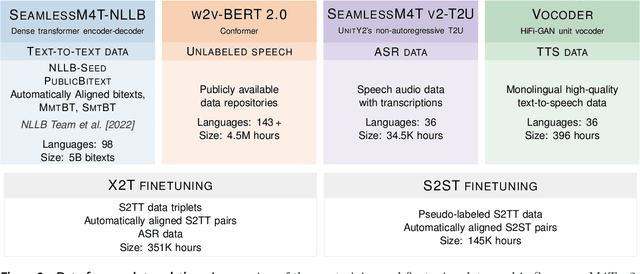
Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Topology-Based Reconstruction Prevention for Decentralised Learning
Dec 08, 2023Decentralised learning has recently gained traction as an alternative to federated learning in which both data and coordination are distributed over its users. To preserve the confidentiality of users' data, decentralised learning relies on differential privacy, multi-party computation, or a combination thereof. However, running multiple privacy-preserving summations in sequence may allow adversaries to perform reconstruction attacks. Unfortunately, current reconstruction countermeasures either cannot trivially be adapted to the distributed setting, or add excessive amounts of noise. In this work, we first show that passive honest-but-curious adversaries can reconstruct other users' private data after several privacy-preserving summations. For example, in subgraphs with 18 users, we show that only three passive honest-but-curious adversaries succeed at reconstructing private data 11.0% of the time, requiring an average of 8.8 summations per adversary. The success rate is independent of the size of the full network. We consider weak adversaries, who do not control the graph topology and can exploit neither the workings of the summation protocol nor the specifics of users' data. We develop a mathematical understanding of how reconstruction relates to topology and propose the first topology-based decentralised defence against reconstruction attacks. Specifically, we show that reconstruction requires a number of adversaries linear in the length of the network's shortest cycle. Consequently, reconstructing private data from privacy-preserving summations is impossible in acyclic networks. Our work is a stepping stone for a formal theory of decentralised reconstruction defences based on topology. Such a theory would generalise our countermeasure beyond summation, define confidentiality in terms of entropy, and describe the effects of (topology-aware) differential privacy.
ResNLS: An Improved Model for Stock Price Forecasting
Dec 02, 2023
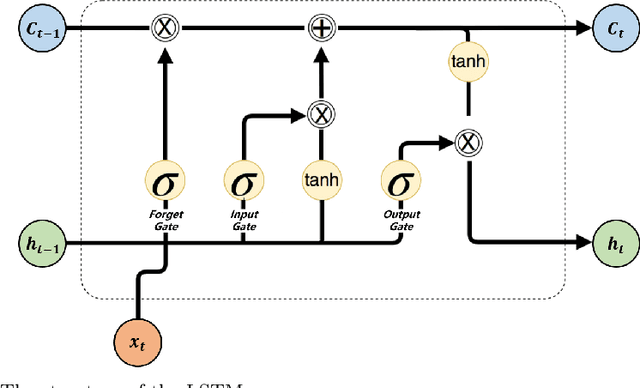
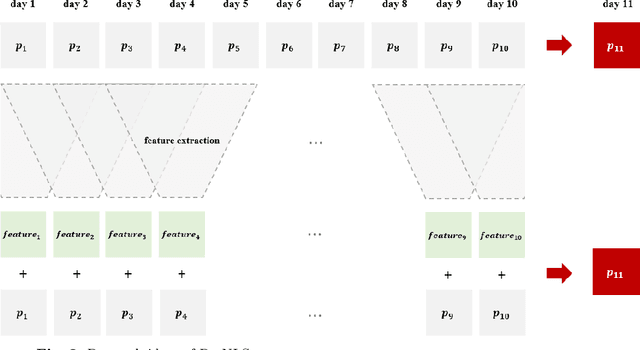
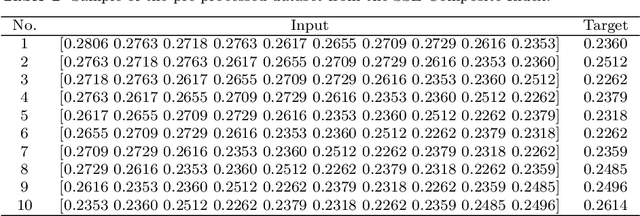
Stock prices forecasting has always been a challenging task. Although many research projects adopt machine learning and deep learning algorithms to address the problem, few of them pay attention to the varying degrees of dependencies between stock prices. In this paper we introduce a hybrid model that improves stock price prediction by emphasizing the dependencies between adjacent stock prices. The proposed model, ResNLS, is mainly composed of two neural architectures, ResNet and LSTM. ResNet serves as a feature extractor to identify dependencies between stock prices across time windows, while LSTM analyses the initial time-series data with the combination of dependencies which considered as residuals. In predicting the SSE Composite Index, our experiment reveals that when the closing price data for the previous 5 consecutive trading days is used as the input, the performance of the model (ResNLS-5) is optimal compared to those with other inputs. Furthermore, ResNLS-5 outperforms vanilla CNN, RNN, LSTM, and BiLSTM models in terms of prediction accuracy. It also demonstrates at least a 20% improvement over the current state-of-the-art baselines. To verify whether ResNLS-5 can help clients effectively avoid risks and earn profits in the stock market, we construct a quantitative trading framework for back testing. The experimental results show that the trading strategy based on predictions from ResNLS-5 can successfully mitigate losses during declining stock prices and generate profits in the periods of rising stock prices.