 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Bone Degradation Using Vision Transformer and Synthetic Cellular Microstructures Dataset
Dec 05, 2023
Bone degradation, especially for astronauts in microgravity conditions, is crucial for space exploration missions since the lower applied external forces accelerate the diminution in bone stiffness and strength substantially. Although existing computational models help us understand this phenomenon and possibly restrict its effect in the future, they are time-consuming to simulate the changes in the bones, not just the bone microstructures, of each individual in detail. In this study, a robust yet fast computational method to predict and visualize bone degradation has been developed. Our deep-learning method, TransVNet, can take in different 3D voxelized images and predict their evolution throughout months utilizing a hybrid 3D-CNN-VisionTransformer autoencoder architecture. Because of limited available experimental data and challenges of obtaining new samples, a digital twin dataset of diverse and initial bone-like microstructures was generated to train our TransVNet on the evolution of the 3D images through a previously developed degradation model for microgravity.
Fully Convolutional Slice-to-Volume Reconstruction for Single-Stack MRI
Dec 05, 2023In magnetic resonance imaging (MRI), slice-to-volume reconstruction (SVR) refers to computational reconstruction of an unknown 3D magnetic resonance volume from stacks of 2D slices corrupted by motion. While promising, current SVR methods require multiple slice stacks for accurate 3D reconstruction, leading to long scans and limiting their use in time-sensitive applications such as fetal fMRI. Here, we propose a SVR method that overcomes the shortcomings of previous work and produces state-of-the-art reconstructions in the presence of extreme inter-slice motion. Inspired by the recent success of single-view depth estimation methods, we formulate SVR as a single-stack motion estimation task and train a fully convolutional network to predict a motion stack for a given slice stack, producing a 3D reconstruction as a byproduct of the predicted motion. Extensive experiments on the SVR of adult and fetal brains demonstrate that our fully convolutional method is twice as accurate as previous SVR methods. Our code is available at github.com/seannz/svr.
Role of Uncertainty in Anticipatory Trajectory Prediction for a Ping-Pong Playing Robot
Dec 05, 2023Robotic interaction in fast-paced environments presents a substantial challenge, particularly in tasks requiring the prediction of dynamic, non-stationary objects for timely and accurate responses. An example of such a task is ping-pong, where the physical limitations of a robot may prevent it from reaching its goal in the time it takes the ball to cross the table. The scene of a ping-pong match contains rich visual information of a player's movement that can allow future game state prediction, with varying degrees of uncertainty. To this aim, we present a visual modeling, prediction, and control system to inform a ping-pong playing robot utilizing visual model uncertainty to allow earlier motion of the robot throughout the game. We present demonstrations and metrics in simulation to show the benefit of incorporating model uncertainty, the limitations of current standard model uncertainty estimators, and the need for more verifiable model uncertainty estimation. Our code is publicly available.
Rank-without-GPT: Building GPT-Independent Listwise Rerankers on Open-Source Large Language Models
Dec 05, 2023Listwise rerankers based on large language models (LLM) are the zero-shot state-of-the-art. However, current works in this direction all depend on the GPT models, making it a single point of failure in scientific reproducibility. Moreover, it raises the concern that the current research findings only hold for GPT models but not LLM in general. In this work, we lift this pre-condition and build for the first time effective listwise rerankers without any form of dependency on GPT. Our passage retrieval experiments show that our best list se reranker surpasses the listwise rerankers based on GPT-3.5 by 13% and achieves 97% effectiveness of the ones built on GPT-4. Our results also show that the existing training datasets, which were expressly constructed for pointwise ranking, are insufficient for building such listwise rerankers. Instead, high-quality listwise ranking data is required and crucial, calling for further work on building human-annotated listwise data resources.
Towards More Practical Group Activity Detection: A New Benchmark and Model
Dec 05, 2023Group activity detection (GAD) is the task of identifying members of each group and classifying the activity of the group at the same time in a video. While GAD has been studied recently, there is still much room for improvement in both dataset and methodology due to their limited capability to address practical GAD scenarios. To resolve these issues, we first present a new dataset, dubbed Caf\'e. Unlike existing datasets, Caf\'e is constructed primarily for GAD and presents more practical evaluation scenarios and metrics, as well as being large-scale and providing rich annotations. Along with the dataset, we propose a new GAD model that deals with an unknown number of groups and latent group members efficiently and effectively. We evaluated our model on three datasets including Caf\'e, where it outperformed previous work in terms of both accuracy and inference speed. Both our dataset and code base will be open to the public to promote future research on GAD.
TPA3D: Triplane Attention for Fast Text-to-3D Generation
Dec 05, 2023Due to the lack of large-scale text-3D correspondence data, recent text-to-3D generation works mainly rely on utilizing 2D diffusion models for synthesizing 3D data. Since diffusion-based methods typically require significant optimization time for both training and inference, the use of GAN-based models would still be desirable for fast 3D generation. In this work, we propose Triplane Attention for text-guided 3D generation (TPA3D), an end-to-end trainable GAN-based deep learning model for fast text-to-3D generation. With only 3D shape data and their rendered 2D images observed during training, our TPA3D is designed to retrieve detailed visual descriptions for synthesizing the corresponding 3D mesh data. This is achieved by the proposed attention mechanisms on the extracted sentence and word-level text features. In our experiments, we show that TPA3D generates high-quality 3D textured shapes aligned with fine-grained descriptions, while impressive computation efficiency can be observed.
FRAPPÉ: A Post-Processing Framework for Group Fairness Regularization
Dec 05, 2023Post-processing mitigation techniques for group fairness generally adjust the decision threshold of a base model in order to improve fairness. Methods in this family exhibit several advantages that make them appealing in practice: post-processing requires no access to the model training pipeline, is agnostic to the base model architecture, and offers a reduced computation cost compared to in-processing. Despite these benefits, existing methods face other challenges that limit their applicability: they require knowledge of the sensitive attributes at inference time and are oftentimes outperformed by in-processing. In this paper, we propose a general framework to transform any in-processing method with a penalized objective into a post-processing procedure. The resulting method is specifically designed to overcome the aforementioned shortcomings of prior post-processing approaches. Furthermore, we show theoretically and through extensive experiments on real-world data that the resulting post-processing method matches or even surpasses the fairness-error trade-off offered by the in-processing counterpart.
Deep learning acceleration of iterative model-based light fluence correction for photoacoustic tomography
Dec 05, 2023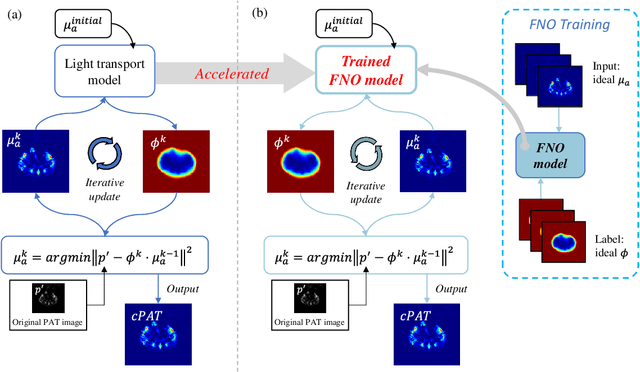

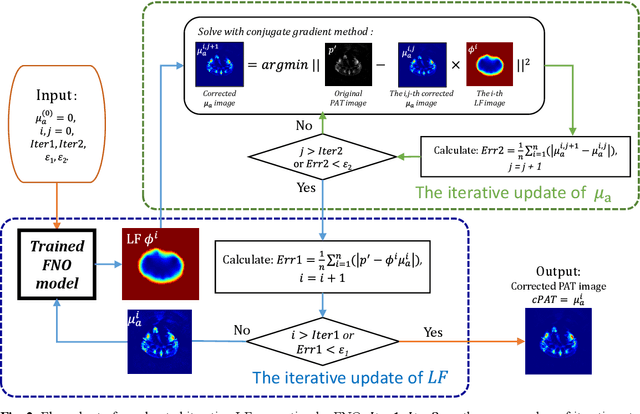
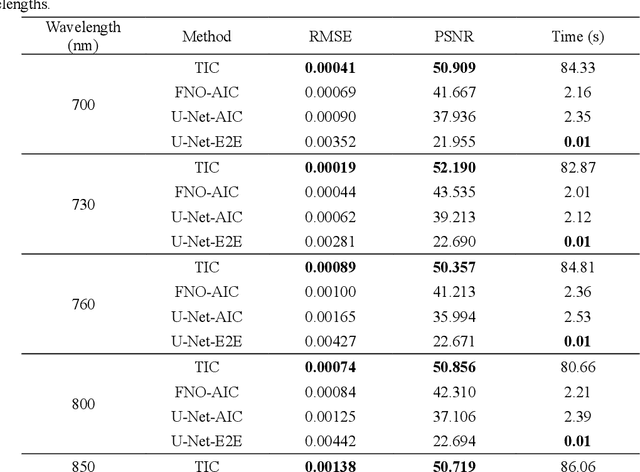
Photoacoustic tomography (PAT) is a promising imaging technique that can visualize the distribution of chromophores within biological tissue. However, the accuracy of PAT imaging is compromised by light fluence (LF), which hinders the quantification of light absorbers. Currently, model-based iterative methods are used for LF correction, but they require significant computational resources due to repeated LF estimation based on differential light transport models. To improve LF correction efficiency, we propose to use Fourier neural operator (FNO), a neural network specially designed for solving differential equations, to learn the forward projection of light transport in PAT. Trained using paired finite-element-based LF simulation data, our FNO model replaces the traditional computational heavy LF estimator during iterative correction, such that the correction procedure is significantly accelerated. Simulation and experimental results demonstrate that our method achieves comparable LF correction quality to traditional iterative methods while reducing the correction time by over 30 times.
A New Time Series Similarity Measure and Its Smart Grid Applications
Oct 19, 2023Many smart grid applications involve data mining, clustering, classification, identification, and anomaly detection, among others. These applications primarily depend on the measurement of similarity, which is the distance between different time series or subsequences of a time series. The commonly used time series distance measures, namely Euclidean Distance (ED) and Dynamic Time Warping (DTW), do not quantify the flexible nature of electricity usage data in terms of temporal dynamics. As a result, there is a need for a new distance measure that can quantify both the amplitude and temporal changes of electricity time series for smart grid applications, e.g., demand response and load profiling. This paper introduces a novel distance measure to compare electricity usage patterns. The method consists of two phases that quantify the effort required to reshape one time series into another, considering both amplitude and temporal changes. The proposed method is evaluated against ED and DTW using real-world data in three smart grid applications. Overall, the proposed measure outperforms ED and DTW in accurately identifying the best load scheduling strategy, anomalous days with irregular electricity usage, and determining electricity users' behind-the-meter (BTM) equipment.
Neural Likelihood Approximation for Integer Valued Time Series Data
Oct 19, 2023Stochastic processes defined on integer valued state spaces are popular within the physical and biological sciences. These models are necessary for capturing the dynamics of small systems where the individual nature of the populations cannot be ignored and stochastic effects are important. The inference of the parameters of such models, from time series data, is difficult due to intractability of the likelihood; current methods, based on simulations of the underlying model, can be so computationally expensive as to be prohibitive. In this paper we construct a neural likelihood approximation for integer valued time series data using causal convolutions, which allows us to evaluate the likelihood of the whole time series in parallel. We demonstrate our method by performing inference on a number of ecological and epidemiological models, showing that we can accurately approximate the true posterior while achieving significant computational speed ups in situations where current methods struggle.