 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection
Dec 08, 2023


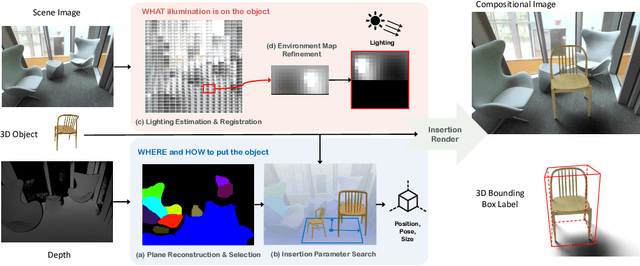

A major challenge in monocular 3D object detection is the limited diversity and quantity of objects in real datasets. While augmenting real scenes with virtual objects holds promise to improve both the diversity and quantity of the objects, it remains elusive due to the lack of an effective 3D object insertion method in complex real captured scenes. In this work, we study augmenting complex real indoor scenes with virtual objects for monocular 3D object detection. The main challenge is to automatically identify plausible physical properties for virtual assets (e.g., locations, appearances, sizes, etc.) in cluttered real scenes. To address this challenge, we propose a physically plausible indoor 3D object insertion approach to automatically copy virtual objects and paste them into real scenes. The resulting objects in scenes have 3D bounding boxes with plausible physical locations and appearances. In particular, our method first identifies physically feasible locations and poses for the inserted objects to prevent collisions with the existing room layout. Subsequently, it estimates spatially-varying illumination for the insertion location, enabling the immersive blending of the virtual objects into the original scene with plausible appearances and cast shadows. We show that our augmentation method significantly improves existing monocular 3D object models and achieves state-of-the-art performance. For the first time, we demonstrate that a physically plausible 3D object insertion, serving as a generative data augmentation technique, can lead to significant improvements for discriminative downstream tasks such as monocular 3D object detection. Project website: https://gyhandy.github.io/3D-Copy-Paste/
RainAI -- Precipitation Nowcasting from Satellite Data
Nov 30, 2023This paper presents a solution to the Weather4Cast 2023 competition, where the goal is to forecast high-resolution precipitation with an 8-hour lead time using lower-resolution satellite radiance images. We propose a simple, yet effective method for spatiotemporal feature learning using a 2D U-Net model, that outperforms the official 3D U-Net baseline in both performance and efficiency. We place emphasis on refining the dataset, through importance sampling and dataset preparation, and show that such techniques have a significant impact on performance. We further study an alternative cross-entropy loss function that improves performance over the standard mean squared error loss, while also enabling models to produce probabilistic outputs. Additional techniques are explored regarding the generation of predictions at different lead times, specifically through Conditioning Lead Time. Lastly, to generate high-resolution forecasts, we evaluate standard and learned upsampling methods. The code and trained parameters are available at https://github.com/rafapablos/w4c23-rainai.
Semiparametric Efficient Inference in Adaptive Experiments
Nov 30, 2023We consider the problem of efficient inference of the Average Treatment Effect in a sequential experiment where the policy governing the assignment of subjects to treatment or control can change over time. We first provide a central limit theorem for the Adaptive Augmented Inverse-Probability Weighted estimator, which is semiparametric efficient, under weaker assumptions than those previously made in the literature. This central limit theorem enables efficient inference at fixed sample sizes. We then consider a sequential inference setting, deriving both asymptotic and nonasymptotic confidence sequences that are considerably tighter than previous methods. These anytime-valid methods enable inference under data-dependent stopping times (sample sizes). Additionally, we use propensity score truncation techniques from the recent off-policy estimation literature to reduce the finite sample variance of our estimator without affecting the asymptotic variance. Empirical results demonstrate that our methods yield narrower confidence sequences than those previously developed in the literature while maintaining time-uniform error control.
TLControl: Trajectory and Language Control for Human Motion Synthesis
Nov 30, 2023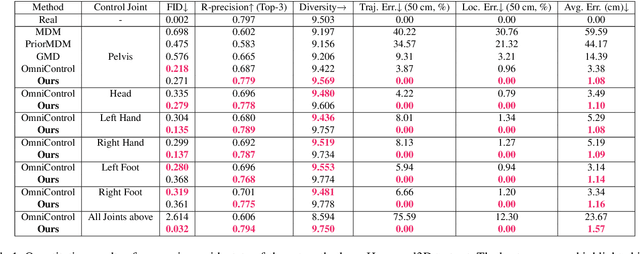
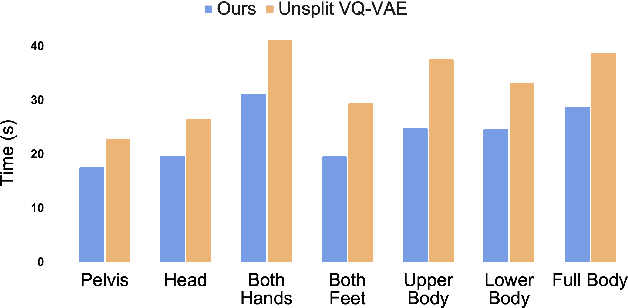
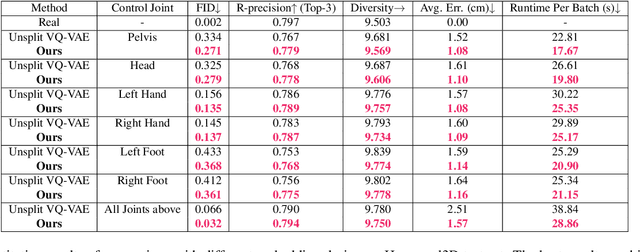
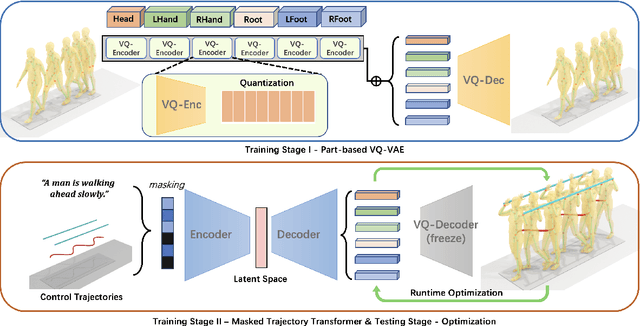
Controllable human motion synthesis is essential for applications in AR/VR, gaming, movies, and embodied AI. Existing methods often focus solely on either language or full trajectory control, lacking precision in synthesizing motions aligned with user-specified trajectories, especially for multi-joint control. To address these issues, we present TLControl, a new method for realistic human motion synthesis, incorporating both low-level trajectory and high-level language semantics controls. Specifically, we first train a VQ-VAE to learn a compact latent motion space organized by body parts. We then propose a Masked Trajectories Transformer to make coarse initial predictions of full trajectories of joints based on the learned latent motion space, with user-specified partial trajectories and text descriptions as conditioning. Finally, we introduce an efficient test-time optimization to refine these coarse predictions for accurate trajectory control. Experiments demonstrate that TLControl outperforms the state-of-the-art in trajectory accuracy and time efficiency, making it practical for interactive and high-quality animation generation.
Automating lichen monitoring in ecological studies using instance segmentation of time-lapse images
Oct 26, 2023Lichens are symbiotic organisms composed of fungi, algae, and/or cyanobacteria that thrive in a variety of environments. They play important roles in carbon and nitrogen cycling, and contribute directly and indirectly to biodiversity. Ecologists typically monitor lichens by using them as indicators to assess air quality and habitat conditions. In particular, epiphytic lichens, which live on trees, are key markers of air quality and environmental health. A new method of monitoring epiphytic lichens involves using time-lapse cameras to gather images of lichen populations. These cameras are used by ecologists in Newfoundland and Labrador to subsequently analyze and manually segment the images to determine lichen thalli condition and change. These methods are time-consuming and susceptible to observer bias. In this work, we aim to automate the monitoring of lichens over extended periods and to estimate their biomass and condition to facilitate the task of ecologists. To accomplish this, our proposed framework uses semantic segmentation with an effective training approach to automate monitoring and biomass estimation of epiphytic lichens on time-lapse images. We show that our method has the potential to significantly improve the accuracy and efficiency of lichen population monitoring, making it a valuable tool for forest ecologists and environmental scientists to evaluate the impact of climate change on Canada's forests. To the best of our knowledge, this is the first time that such an approach has been used to assist ecologists in monitoring and analyzing epiphytic lichens.
A WINNER+ Based 3-D Non-Stationary Wideband MIMO Channel Model
Dec 01, 2023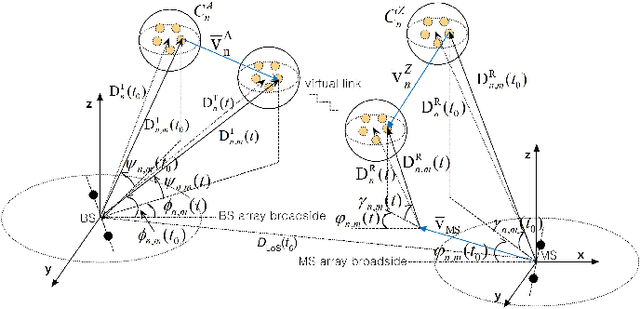
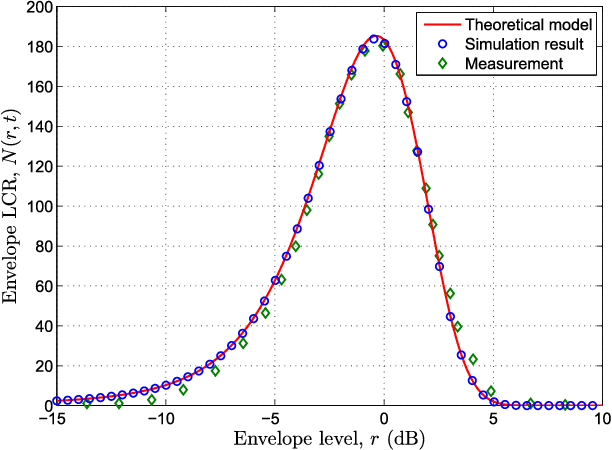
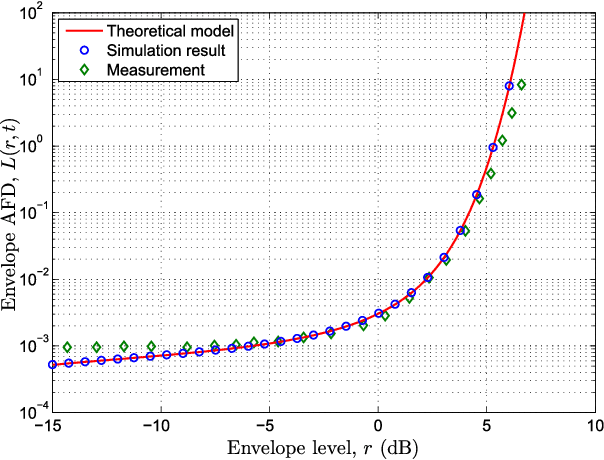
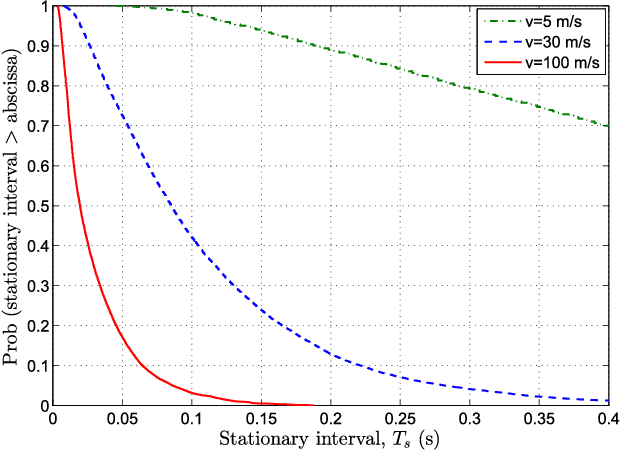
In this paper, a three-dimensional (3-D) non-stationary wideband multiple-input multiple-output (MIMO) channel model based on the WINNER+ channel model is proposed. The angular distributions of clusters in both the horizontal and vertical planes are jointly considered. The receiver and clusters can be moving, which makes the model more general. Parameters including number of clusters, powers, delays, azimuth angles of departure (AAoDs), azimuth angles of arrival (AAoAs), elevation angles of departure (EAoDs), and elevation angles of arrival (EAoAs) are time-variant. The cluster time evolution is modeled using a birth-death process. Statistical properties, including spatial cross-correlation function (CCF), temporal autocorrelation function (ACF), Doppler power spectrum density (PSD), level-crossing rate (LCR), average fading duration (AFD), and stationary interval are investigated and analyzed. The LCR, AFD, and stationary interval of the proposed channel model are validated against the measurement data. Numerical and simulation results show that the proposed channel model has the ability to reproduce the main properties of real non-stationary channels. Furthermore, the proposed channel model can be adapted to various communication scenarios by adjusting different parameter values.
QIENet: Quantitative irradiance estimation network using recurrent neural network based on satellite remote sensing data
Dec 01, 2023Global horizontal irradiance (GHI) plays a vital role in estimating solar energy resources, which are used to generate sustainable green energy. In order to estimate GHI with high spatial resolution, a quantitative irradiance estimation network, named QIENet, is proposed. Specifically, the temporal and spatial characteristics of remote sensing data of the satellite Himawari-8 are extracted and fused by recurrent neural network (RNN) and convolution operation, respectively. Not only remote sensing data, but also GHI-related time information (hour, day, and month) and geographical information (altitude, longitude, and latitude), are used as the inputs of QIENet. The satellite spectral channels B07 and B11 - B15 and time are recommended as model inputs for QIENet according to the spatial distributions of annual solar energy. Meanwhile, QIENet is able to capture the impact of various clouds on hourly GHI estimates. More importantly, QIENet does not overestimate ground observations and can also reduce RMSE by 27.51%/18.00%, increase R2 by 20.17%/9.42%, and increase r by 8.69%/3.54% compared with ERA5/NSRDB. Furthermore, QIENet is capable of providing a high-fidelity hourly GHI database with spatial resolution 0.02{\deg} * 0.02{\deg}(approximately 2km * 2km) for many applied energy fields.
Making the End-User a Priority in Benchmarking: OrionBench for Unsupervised Time Series Anomaly Detection
Oct 26, 2023Time series anomaly detection is a prevalent problem in many application domains such as patient monitoring in healthcare, forecasting in finance, or predictive maintenance in energy. This has led to the emergence of a plethora of anomaly detection methods, including more recently, deep learning based methods. Although several benchmarks have been proposed to compare newly developed models, they usually rely on one-time execution over a limited set of datasets and the comparison is restricted to a few models. We propose OrionBench -- a user centric continuously maintained benchmark for unsupervised time series anomaly detection. The framework provides universal abstractions to represent models, extensibility to add new pipelines and datasets, hyperparameter standardization, pipeline verification, and frequent releases with published benchmarks. We demonstrate the usage of OrionBench, and the progression of pipelines across 15 releases published over the course of three years. Moreover, we walk through two real scenarios we experienced with OrionBench that highlight the importance of continuous benchmarks in unsupervised time series anomaly detection.
MeanCut: A Greedy-Optimized Graph Clustering via Path-based Similarity and Degree Descent Criterion
Dec 07, 2023As the most typical graph clustering method, spectral clustering is popular and attractive due to the remarkable performance, easy implementation, and strong adaptability. Classical spectral clustering measures the edge weights of graph using pairwise Euclidean-based metric, and solves the optimal graph partition by relaxing the constraints of indicator matrix and performing Laplacian decomposition. However, Euclidean-based similarity might cause skew graph cuts when handling non-spherical data distributions, and the relaxation strategy introduces information loss. Meanwhile, spectral clustering requires specifying the number of clusters, which is hard to determine without enough prior knowledge. In this work, we leverage the path-based similarity to enhance intra-cluster associations, and propose MeanCut as the objective function and greedily optimize it in degree descending order for a nondestructive graph partition. This algorithm enables the identification of arbitrary shaped clusters and is robust to noise. To reduce the computational complexity of similarity calculation, we transform optimal path search into generating the maximum spanning tree (MST), and develop a fast MST (FastMST) algorithm to further improve its time-efficiency. Moreover, we define a density gradient factor (DGF) for separating the weakly connected clusters. The validity of our algorithm is demonstrated by testifying on real-world benchmarks and application of face recognition. The source code of MeanCut is available at https://github.com/ZPGuiGroupWhu/MeanCut-Clustering.
gcDLSeg: Integrating Graph-cut into Deep Learning for Binary Semantic Segmentation
Dec 07, 2023Binary semantic segmentation in computer vision is a fundamental problem. As a model-based segmentation method, the graph-cut approach was one of the most successful binary segmentation methods thanks to its global optimality guarantee of the solutions and its practical polynomial-time complexity. Recently, many deep learning (DL) based methods have been developed for this task and yielded remarkable performance, resulting in a paradigm shift in this field. To combine the strengths of both approaches, we propose in this study to integrate the graph-cut approach into a deep learning network for end-to-end learning. Unfortunately, backward propagation through the graph-cut module in the DL network is challenging due to the combinatorial nature of the graph-cut algorithm. To tackle this challenge, we propose a novel residual graph-cut loss and a quasi-residual connection, enabling the backward propagation of the gradients of the residual graph-cut loss for effective feature learning guided by the graph-cut segmentation model. In the inference phase, globally optimal segmentation is achieved with respect to the graph-cut energy defined on the optimized image features learned from DL networks. Experiments on the public AZH chronic wound data set and the pancreas cancer data set from the medical segmentation decathlon (MSD) demonstrated promising segmentation accuracy, and improved robustness against adversarial attacks.