 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
Nov 30, 2023
Recent work by Power et al. (2022) highlighted a surprising "grokking" phenomenon in learning arithmetic tasks: a neural net first "memorizes" the training set, resulting in perfect training accuracy but near-random test accuracy, and after training for sufficiently longer, it suddenly transitions to perfect test accuracy. This paper studies the grokking phenomenon in theoretical setups and shows that it can be induced by a dichotomy of early and late phase implicit biases. Specifically, when training homogeneous neural nets with large initialization and small weight decay on both classification and regression tasks, we prove that the training process gets trapped at a solution corresponding to a kernel predictor for a long time, and then a very sharp transition to min-norm/max-margin predictors occurs, leading to a dramatic change in test accuracy.
Is Channel Independent strategy optimal for Time Series Forecasting?
Oct 18, 2023There has been an emergence of various models for long-term time series forecasting. Recent studies have demonstrated that a single linear layer, using Channel Dependent (CD) or Channel Independent (CI) modeling, can even outperform a large number of sophisticated models. However, current research primarily considers CD and CI as two complementary yet mutually exclusive approaches, unable to harness these two extremes simultaneously. And it is also a challenging issue that both CD and CI are static strategies that cannot be determined to be optimal for a specific dataset without extensive experiments. In this paper, we reconsider whether the current CI strategy is the best solution for time series forecasting. First, we propose a simple yet effective strategy called CSC, which stands for $\mathbf{C}$hannel $\mathbf{S}$elf-$\mathbf{C}$lustering strategy, for linear models. Our Channel Self-Clustering (CSC) enhances CI strategy's performance improvements while reducing parameter size, for exmpale by over 10 times on electricity dataset, and significantly cutting training time. Second, we further propose Channel Rearrangement (CR), a method for deep models inspired by the self-clustering. CR attains competitive performance against baselines. Finally, we also discuss whether it is best to forecast the future values using the historical values of the same channel as inputs. We hope our findings and methods could inspire new solutions beyond CD/CI.
UE4-NeRF:Neural Radiance Field for Real-Time Rendering of Large-Scale Scene
Oct 20, 2023Neural Radiance Fields (NeRF) is a novel implicit 3D reconstruction method that shows immense potential and has been gaining increasing attention. It enables the reconstruction of 3D scenes solely from a set of photographs. However, its real-time rendering capability, especially for interactive real-time rendering of large-scale scenes, still has significant limitations. To address these challenges, in this paper, we propose a novel neural rendering system called UE4-NeRF, specifically designed for real-time rendering of large-scale scenes. We partitioned each large scene into different sub-NeRFs. In order to represent the partitioned independent scene, we initialize polygonal meshes by constructing multiple regular octahedra within the scene and the vertices of the polygonal faces are continuously optimized during the training process. Drawing inspiration from Level of Detail (LOD) techniques, we trained meshes of varying levels of detail for different observation levels. Our approach combines with the rasterization pipeline in Unreal Engine 4 (UE4), achieving real-time rendering of large-scale scenes at 4K resolution with a frame rate of up to 43 FPS. Rendering within UE4 also facilitates scene editing in subsequent stages. Furthermore, through experiments, we have demonstrated that our method achieves rendering quality comparable to state-of-the-art approaches. Project page: https://jamchaos.github.io/UE4-NeRF/.
Large Language Models Are Zero-Shot Time Series Forecasters
Oct 11, 2023By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
Air-Decoding: Attribute Distribution Reconstruction for Decoding-Time Controllable Text Generation
Oct 23, 2023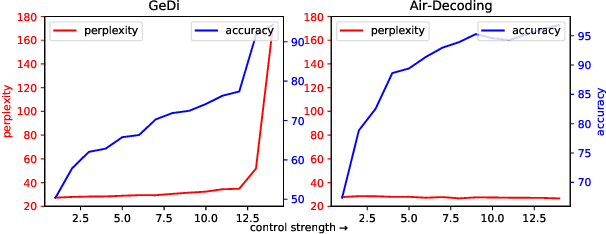
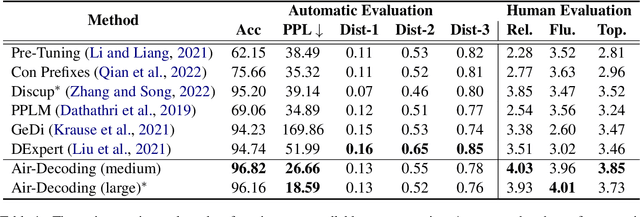
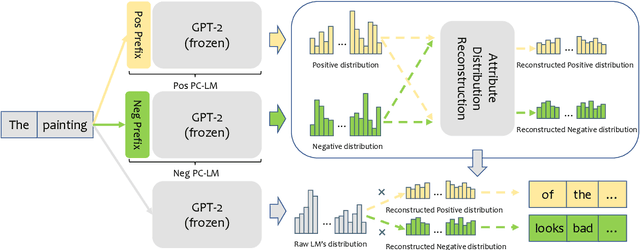
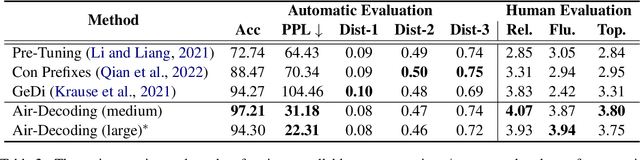
Controllable text generation (CTG) aims to generate text with desired attributes, and decoding-time-based methods have shown promising performance on this task. However, in this paper, we identify the phenomenon of Attribute Collapse for the first time. It causes the fluency of generated text to rapidly decrease when the control strength exceeds a critical value, rendering the text completely unusable. This limitation hinders the effectiveness of decoding methods in achieving high levels of controllability. To address this problem, we propose a novel lightweight decoding framework named Air-Decoding. Its main idea is reconstructing the attribute distributions to balance the weights between attribute words and non-attribute words to generate more fluent text. Specifically, we train prefixes by prefix-tuning to obtain attribute distributions. Then we design a novel attribute distribution reconstruction method to balance the obtained distributions and use the reconstructed distributions to guide language models for generation, effectively avoiding the issue of Attribute Collapse. Experiments on multiple CTG tasks prove that our method achieves a new state-of-the-art control performance.
Two-stage space construction for real-time modeling of distributed parameter systems under sparse sensing
Oct 28, 2023Numerous industrial processes can be defined using distributed parameter systems (DPSs). This study introduces a two-stage spatial construction approach for real-time modeling of DPSs in cases of limited sensors. Initially, a discrete space-completion approach is created to recuperate the spatiotemporal patterns of non-monitored locations under sparse sensing. The high-dimensional space construction method is employed to derive continuous spatial basis functions (SBFs). The identification and adjustment of the nonlinear temporal model are carried out via the long short-term memory (LSTM) neural network. Eventually, the amalgamation of the derived SBFs and temporal model results in a spatially continuous model. The use of a cubic B-spline surface is validated as an effective solution for optimizing space construction in the sense of least squares approximation. Experimental tests conducted on a pouch-type Li-ion battery demonstrate the efficacy of the proposed modeling technique under sparse sensing. This work highlights the promise of sparse sensors in real-time full-space modeling for large-scale battery energy storage systems.
Slice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction
Dec 03, 2023We introduce multi-slice reasoning, a new notion for single-view 3D reconstruction which challenges the current and prevailing belief that multi-view synthesis is the most natural conduit between single-view and 3D. Our key observation is that object slicing is more advantageous than altering views to reveal occluded structures. Specifically, slicing is more occlusion-revealing since it can peel through any occluders without obstruction. In the limit, i.e., with infinitely many slices, it is guaranteed to unveil all hidden object parts. We realize our idea by developing Slice3D, a novel method for single-view 3D reconstruction which first predicts multi-slice images from a single RGB image and then integrates the slices into a 3D model using a coordinate-based transformer network for signed distance prediction. The slice images can be regressed or generated, both through a U-Net based network. For the former, we inject a learnable slice indicator code to designate each decoded image into a spatial slice location, while the slice generator is a denoising diffusion model operating on the entirety of slice images stacked on the input channels. We conduct extensive evaluation against state-of-the-art alternatives to demonstrate superiority of our method, especially in recovering complex and severely occluded shape structures, amid ambiguities. All Slice3D results were produced by networks trained on a single Nvidia A40 GPU, with an inference time less than 20 seconds.
QuantAttack: Exploiting Dynamic Quantization to Attack Vision Transformers
Dec 03, 2023In recent years, there has been a significant trend in deep neural networks (DNNs), particularly transformer-based models, of developing ever-larger and more capable models. While they demonstrate state-of-the-art performance, their growing scale requires increased computational resources (e.g., GPUs with greater memory capacity). To address this problem, quantization techniques (i.e., low-bit-precision representation and matrix multiplication) have been proposed. Most quantization techniques employ a static strategy in which the model parameters are quantized, either during training or inference, without considering the test-time sample. In contrast, dynamic quantization techniques, which have become increasingly popular, adapt during inference based on the input provided, while maintaining full-precision performance. However, their dynamic behavior and average-case performance assumption makes them vulnerable to a novel threat vector -- adversarial attacks that target the model's efficiency and availability. In this paper, we present QuantAttack, a novel attack that targets the availability of quantized models, slowing down the inference, and increasing memory usage and energy consumption. We show that carefully crafted adversarial examples, which are designed to exhaust the resources of the operating system, can trigger worst-case performance. In our experiments, we demonstrate the effectiveness of our attack on vision transformers on a wide range of tasks, both uni-modal and multi-modal. We also examine the effect of different attack variants (e.g., a universal perturbation) and the transferability between different models.
Smart safety watch for elderly people and pregnant women
Dec 03, 2023Falls represent one of the most detrimental occurrences for the elderly. Given the continually increasing ageing demographic, there is a pressing demand for advancing fall detection systems. The swift progress in sensor networks and the Internet of Things (IoT) has made human-computer interaction through sensor fusion an acknowledged and potent approach for tackling the issue of fall detection. Even IoT-enabled systems can deliver economical health monitoring solutions tailored to pregnant women within their daily environments. Recent research indicates that these remote health monitoring setups have the potential to enhance the well-being of both the mother and the infant throughout the pregnancy and postpartum phases. One more emerging advancement is the integration of 'panic buttons,' which are gaining popularity due to the escalating emphasis on safety. These buttons instantly transmit the user's real-time location to pre-designated emergency contacts when activated. Our solution focuses on the above three challenges we see every day. Fall detection for the elderly helps the elderly in case they fall and have nobody around for help. Sleep pattern sensing is helpful for pregnant women based on the SPO2 sensors integrated within our device. It is also bundled with heart rate monitoring. Our third solution focuses on a panic situation; upon pressing the determined buttons, a panic alert would be sent to the emergency contacts listed. The device also comes with a mobile app developed using Flutter that takes care of all the heavy processing rather than the device itself.
Exploring Artificial Intelligence Methods for Energy Prediction in Healthcare Facilities: An In-Depth Extended Systematic Review
Nov 27, 2023Hospitals, due to their complexity and unique requirements, play a pivotal role in global energy consumption patterns. This study conducted a comprehensive literature review, utilizing the PRISMA framework, of articles that employed machine learning and artificial intelligence techniques for predicting energy consumption in hospital buildings. Of the 1884 publications identified, 17 were found to address this specific domain and have been thoroughly reviewed to establish the state-of-the-art and identify gaps where future research is needed. This review revealed a diverse range of data inputs influencing energy prediction, with occupancy and meteorological data emerging as significant predictors. However, many studies failed to delve deep into the implications of their data choices, and gaps were evident regarding the understanding of time dynamics, operational status, and preprocessing methods. Machine learning, especially deep learning models like ANNs, have shown potential in this domain, yet they come with challenges, including interpretability and computational demands. The findings underscore the immense potential of AI in optimizing hospital energy consumption but also highlight the need for more comprehensive and granular research. Key areas for future research include the optimization of ANN approaches, new optimization and data integration techniques, the integration of real-time data into Intelligent Energy Management Systems, and increasing focus on long-term energy forecasting.