 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller
Apr 01, 2024
Sampling-based motion planning methods for manipulators in crowded environments often suffer from expensive collision checking and high sampling complexity, which make them difficult to use in real time. To address this issue, we propose a new generalizable control barrier function (CBF)-based steering controller to reduce the number of samples needed in a sampling-based motion planner RRT. Our method combines the strength of CBF for real-time collision-avoidance control and RRT for long-horizon motion planning, by using CBF-induced neural controller (CBF-INC) to generate control signals that steer the system towards sampled configurations by RRT. CBF-INC is learned as Neural Networks and has two variants handling different inputs, respectively: state (signed distance) input and point-cloud input from LiDAR. In the latter case, we also study two different settings: fully and partially observed environmental information. Compared to manually crafted CBF which suffers from over-approximating robot geometry, CBF-INC can balance safety and goal-reaching better without being over-conservative. Given state-based input, our neural CBF-induced neural controller-enhanced RRT (CBF-INC-RRT) can increase the success rate by 14% while reducing the number of nodes explored by 30%, compared with vanilla RRT on hard test cases. Given LiDAR input where vanilla RRT is not directly applicable, we demonstrate that our CBF-INC-RRT can improve the success rate by 10%, compared with planning with other steering controllers. Our project page with supplementary material is at https://mit-realm.github.io/CBF-INC-RRT-website/.
Time-series Initialization and Conditioning for Video-agnostic Stabilization of Video Super-Resolution using Recurrent Networks
Mar 23, 2024A Recurrent Neural Network (RNN) for Video Super Resolution (VSR) is generally trained with randomly clipped and cropped short videos extracted from original training videos due to various challenges in learning RNNs. However, since this RNN is optimized to super-resolve short videos, VSR of long videos is degraded due to the domain gap. Our preliminary experiments reveal that such degradation changes depending on the video properties, such as the video length and dynamics. To avoid this degradation, this paper proposes the training strategy of RNN for VSR that can work efficiently and stably independently of the video length and dynamics. The proposed training strategy stabilizes VSR by training a VSR network with various RNN hidden states changed depending on the video properties. Since computing such a variety of hidden states is time-consuming, this computational cost is reduced by reusing the hidden states for efficient training. In addition, training stability is further improved with frame-number conditioning. Our experimental results demonstrate that the proposed method performed better than base methods in videos with various lengths and dynamics.
STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
Mar 31, 2024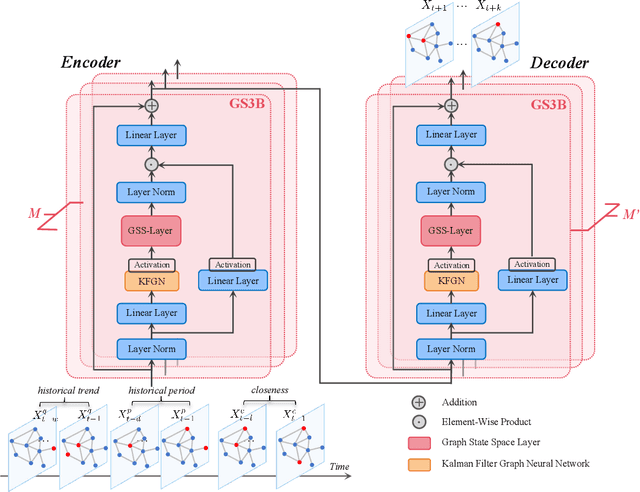
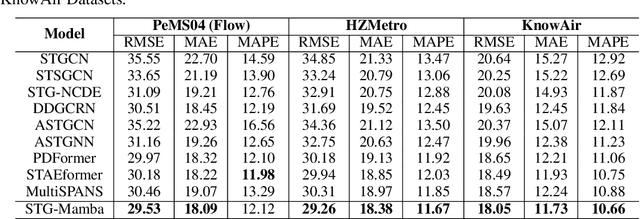
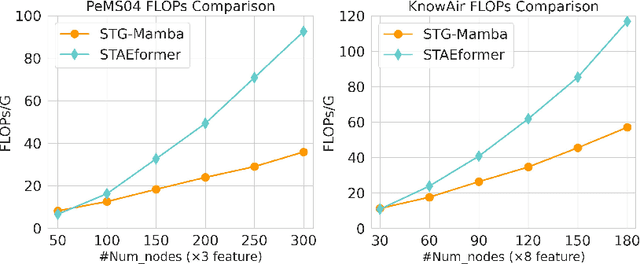
Spatial-Temporal Graph (STG) data is characterized as dynamic, heterogenous, and non-stationary, leading to the continuous challenge of spatial-temporal graph learning. In the past few years, various GNN-based methods have been proposed to solely focus on mimicking the relationships among node individuals of the STG network, ignoring the significance of modeling the intrinsic features that exist in STG system over time. In contrast, modern Selective State Space Models (SSSMs) present a new approach which treat STG Network as a system, and meticulously explore the STG system's dynamic state evolution across temporal dimension. In this work, we introduce Spatial-Temporal Graph Mamba (STG-Mamba) as the first exploration of leveraging the powerful selective state space models for STG learning by treating STG Network as a system, and employing the Graph Selective State Space Block (GS3B) to precisely characterize the dynamic evolution of STG networks. STG-Mamba is formulated as an Encoder-Decoder architecture, which takes GS3B as the basic module, for efficient sequential data modeling. Furthermore, to strengthen GNN's ability of modeling STG data under the setting of SSSMs, we propose Kalman Filtering Graph Neural Networks (KFGN) for adaptive graph structure upgrading. KFGN smoothly fits in the context of selective state space evolution, and at the same time keeps linear complexity. Extensive empirical studies are conducted on three benchmark STG forecasting datasets, demonstrating the performance superiority and computational efficiency of STG-Mamba. It not only surpasses existing state-of-the-art methods in terms of STG forecasting performance, but also effectively alleviate the computational bottleneck of large-scale graph networks in reducing the computational cost of FLOPs and test inference time.
Efficiently Distilling LLMs for Edge Applications
Apr 01, 2024Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
Automated User Story Generation with Test Case Specification Using Large Language Model
Apr 02, 2024Modern Software Engineering era is moving fast with the assistance of artificial intelligence (AI), especially Large Language Models (LLM). Researchers have already started automating many parts of the software development workflow. Requirements Engineering (RE) is a crucial phase that begins the software development cycle through multiple discussions on a proposed scope of work documented in different forms. RE phase ends with a list of user-stories for each unit task identified through discussions and usually these are created and tracked on a project management tool such as Jira, AzurDev etc. In this research we developed a tool "GeneUS" using GPT-4.0 to automatically create user stories from requirements document which is the outcome of the RE phase. The output is provided in JSON format leaving the possibilities open for downstream integration to the popular project management tools. Analyzing requirements documents takes significant effort and multiple meetings with stakeholders. We believe, automating this process will certainly reduce additional load off the software engineers, and increase the productivity since they will be able to utilize their time on other prioritized tasks.
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Apr 02, 2024We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
Two Heads are Better than One: Nested PoE for Robust Defense Against Multi-Backdoors
Apr 02, 2024Data poisoning backdoor attacks can cause undesirable behaviors in large language models (LLMs), and defending against them is of increasing importance. Existing defense mechanisms often assume that only one type of trigger is adopted by the attacker, while defending against multiple simultaneous and independent trigger types necessitates general defense frameworks and is relatively unexplored. In this paper, we propose Nested Product of Experts(NPoE) defense framework, which involves a mixture of experts (MoE) as a trigger-only ensemble within the PoE defense framework to simultaneously defend against multiple trigger types. During NPoE training, the main model is trained in an ensemble with a mixture of smaller expert models that learn the features of backdoor triggers. At inference time, only the main model is used. Experimental results on sentiment analysis, hate speech detection, and question classification tasks demonstrate that NPoE effectively defends against a variety of triggers both separately and in trigger mixtures. Due to the versatility of the MoE structure in NPoE, this framework can be further expanded to defend against other attack settings
Improved model-free bounds for multi-asset options using option-implied information and deep learning
Apr 02, 2024We consider the computation of model-free bounds for multi-asset options in a setting that combines dependence uncertainty with additional information on the dependence structure. More specifically, we consider the setting where the marginal distributions are known and partial information, in the form of known prices for multi-asset options, is also available in the market. We provide a fundamental theorem of asset pricing in this setting, as well as a superhedging duality that allows to transform the maximization problem over probability measures in a more tractable minimization problem over trading strategies. The latter is solved using a penalization approach combined with a deep learning approximation using artificial neural networks. The numerical method is fast and the computational time scales linearly with respect to the number of traded assets. We finally examine the significance of various pieces of additional information. Empirical evidence suggests that "relevant" information, i.e. prices of derivatives with the same payoff structure as the target payoff, are more useful that other information, and should be prioritized in view of the trade-off between accuracy and computational efficiency.
Energy-Optimized Planning in Non-Uniform Wind Fields with Fixed-Wing Aerial Vehicles
Apr 02, 2024Fixed-wing small uncrewed aerial vehicles (sUAVs) possess the capability to remain airborne for extended durations and traverse vast distances. However, their operation is susceptible to wind conditions, particularly in regions of complex terrain where high wind speeds may push the aircraft beyond its operational limitations, potentially raising safety concerns. Moreover, wind impacts the energy required to follow a path, especially in locations where the wind direction and speed are not favorable. Incorporating wind information into mission planning is essential to ensure both safety and energy efficiency. In this paper, we propose a sampling-based planner using the kinematic Dubins aircraft paths with respect to the ground, to plan energy-efficient paths in non-uniform wind fields. We study the planner characteristics with synthetic and real-world wind data and compare its performance against baseline cost and path formulations. We demonstrate that the energy-optimized planner effectively utilizes updrafts to minimize energy consumption, albeit at the expense of increased travel time. The ground-relative path formulation facilitates the generation of safe trajectories onboard sUAVs within reasonable computational timeframes.
Causality-based Transfer of Driving Scenarios to Unseen Intersections
Apr 02, 2024Scenario-based testing of automated driving functions has become a promising method to reduce time and cost compared to real-world testing. In scenario-based testing automated functions are evaluated in a set of pre-defined scenarios. These scenarios provide information about vehicle behaviors, environmental conditions, or road characteristics using parameters. To create realistic scenarios, parameters and parameter dependencies have to be fitted utilizing real-world data. However, due to the large variety of intersections and movement constellations found in reality, data may not be available for certain scenarios. This paper proposes a methodology to systematically analyze relations between parameters of scenarios. Bayesian networks are utilized to analyze causal dependencies in order to decrease the amount of required data and to transfer causal patterns creating unseen scenarios. Thereby, infrastructural influences on movement patterns are investigated to generate realistic scenarios on unobserved intersections. For evaluation, scenarios and underlying parameters are extracted from the inD dataset. Movement patterns are estimated, transferred and checked against recorded data from those initially unseen intersections.