 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Exactly Linearizable Deep Dynamics Models
Nov 30, 2023
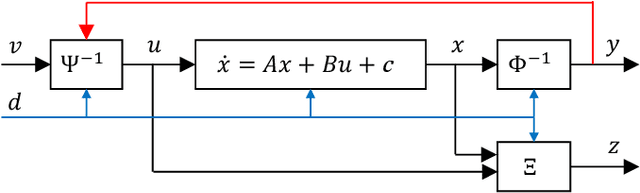
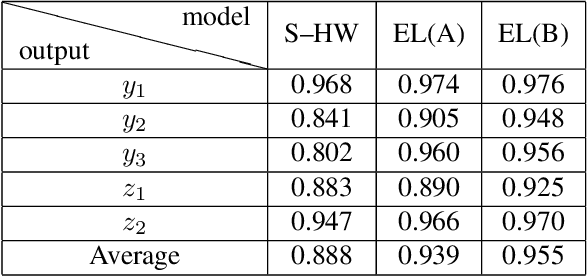
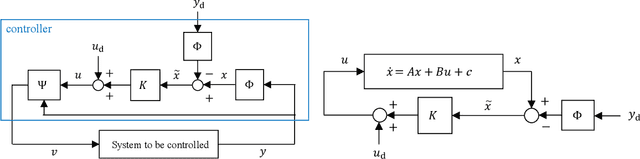
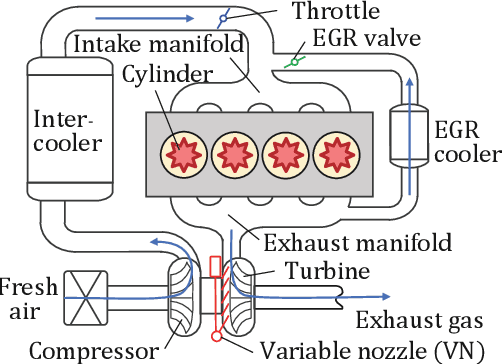
Research on control using models based on machine-learning methods has now shifted to the practical engineering stage. Achieving high performance and theoretically guaranteeing the safety of the system is critical for such applications. In this paper, we propose a learning method for exactly linearizable dynamical models that can easily apply various control theories to ensure stability, reliability, etc., and to provide a high degree of freedom of expression. As an example, we present a design that combines simple linear control and control barrier functions. The proposed model is employed for the real-time control of an automotive engine, and the results demonstrate good predictive performance and stable control under constraints.
Let the LLMs Talk: Simulating Human-to-Human Conversational QA via Zero-Shot LLM-to-LLM Interactions
Dec 05, 2023Conversational question-answering (CQA) systems aim to create interactive search systems that effectively retrieve information by interacting with users. To replicate human-to-human conversations, existing work uses human annotators to play the roles of the questioner (student) and the answerer (teacher). Despite its effectiveness, challenges exist as human annotation is time-consuming, inconsistent, and not scalable. To address this issue and investigate the applicability of large language models (LLMs) in CQA simulation, we propose a simulation framework that employs zero-shot learner LLMs for simulating teacher-student interactions. Our framework involves two LLMs interacting on a specific topic, with the first LLM acting as a student, generating questions to explore a given search topic. The second LLM plays the role of a teacher by answering questions and is equipped with additional information, including a text on the given topic. We implement both the student and teacher by zero-shot prompting the GPT-4 model. To assess the effectiveness of LLMs in simulating CQA interactions and understand the disparities between LLM- and human-generated conversations, we evaluate the simulated data from various perspectives. We begin by evaluating the teacher's performance through both automatic and human assessment. Next, we evaluate the performance of the student, analyzing and comparing the disparities between questions generated by the LLM and those generated by humans. Furthermore, we conduct extensive analyses to thoroughly examine the LLM performance by benchmarking state-of-the-art reading comprehension models on both datasets. Our results reveal that the teacher LLM generates lengthier answers that tend to be more accurate and complete. The student LLM generates more diverse questions, covering more aspects of a given topic.
Convergence Rates for Stochastic Approximation: Biased Noise with Unbounded Variance, and Applications
Dec 05, 2023The Stochastic Approximation (SA) algorithm introduced by Robbins and Monro in 1951 has been a standard method for solving equations of the form $\mathbf{f}({\boldsymbol {\theta}}) = \mathbf{0}$, when only noisy measurements of $\mathbf{f}(\cdot)$ are available. If $\mathbf{f}({\boldsymbol {\theta}}) = \nabla J({\boldsymbol {\theta}})$ for some function $J(\cdot)$, then SA can also be used to find a stationary point of $J(\cdot)$. In much of the literature, it is assumed that the error term ${\boldsymbol {xi}}_{t+1}$ has zero conditional mean, and that its conditional variance is bounded as a function of $t$ (though not necessarily with respect to ${\boldsymbol {\theta}}_t$). Also, for the most part, the emphasis has been on ``synchronous'' SA, whereby, at each time $t$, \textit{every} component of ${\boldsymbol {\theta}}_t$ is updated. Over the years, SA has been applied to a variety of areas, out of which two are the focus in this paper: Convex and nonconvex optimization, and Reinforcement Learning (RL). As it turns out, in these applications, the above-mentioned assumptions do not always hold. In zero-order methods, the error neither has zero mean nor bounded conditional variance. In the present paper, we extend SA theory to encompass errors with nonzero conditional mean and/or unbounded conditional variance, and also asynchronous SA. In addition, we derive estimates for the rate of convergence of the algorithm. Then we apply the new results to problems in nonconvex optimization, and to Markovian SA, a recently emerging area in RL. We prove that SA converges in these situations, and compute the ``optimal step size sequences'' to maximize the estimated rate of convergence.
Towards Explaining Satellite Based Poverty Predictions with Convolutional Neural Networks
Dec 01, 2023Deep convolutional neural networks (CNNs) have been shown to predict poverty and development indicators from satellite images with surprising accuracy. This paper presents a first attempt at analyzing the CNNs responses in detail and explaining the basis for the predictions. The CNN model, while trained on relatively low resolution day- and night-time satellite images, is able to outperform human subjects who look at high-resolution images in ranking the Wealth Index categories. Multiple explainability experiments performed on the model indicate the importance of the sizes of the objects, pixel colors in the image, and provide a visualization of the importance of different structures in input images. A visualization is also provided of type images that maximize the network prediction of Wealth Index, which provides clues on what the CNN prediction is based on.
Explainable Anomaly Detection using Masked Latent Generative Modeling
Nov 21, 2023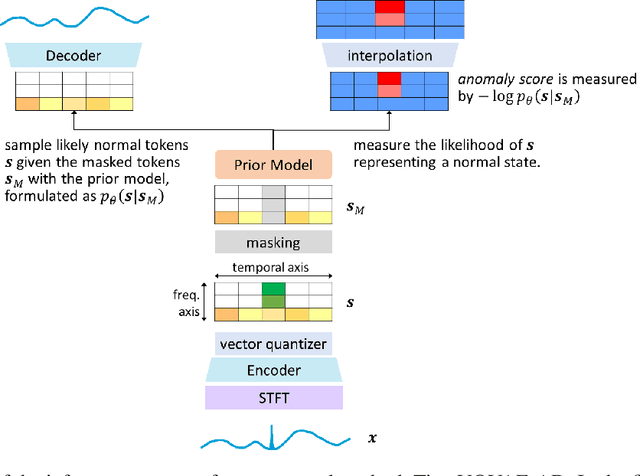
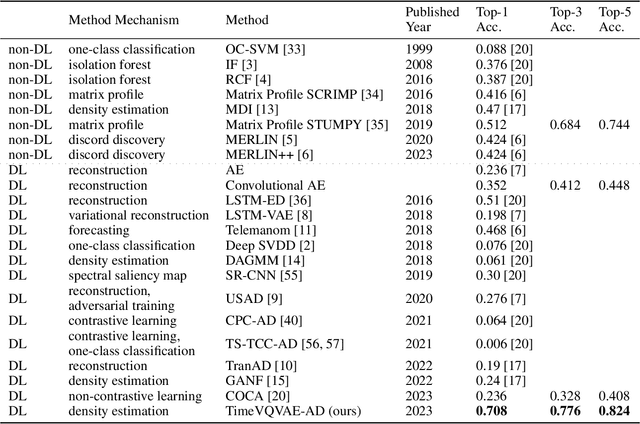
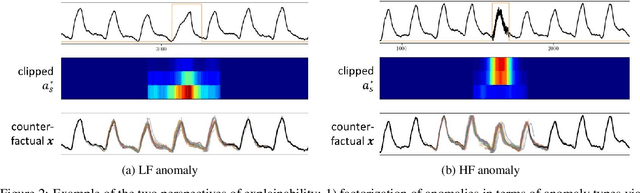
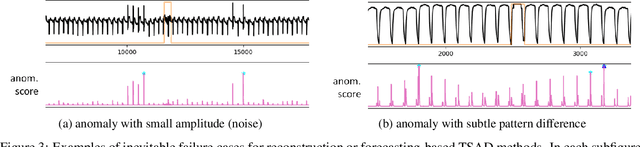
We present a novel time series anomaly detection method that achieves excellent detection accuracy while offering a superior level of explainability. Our proposed method, TimeVQVAE-AD, leverages masked generative modeling adapted from the cutting-edge time series generation method known as TimeVQVAE. The prior model is trained on the discrete latent space of a time-frequency domain. Notably, the dimensional semantics of the time-frequency domain are preserved in the latent space, enabling us to compute anomaly scores across different frequency bands, which provides a better insight into the detected anomalies. Additionally, the generative nature of the prior model allows for sampling likely normal states for detected anomalies, enhancing the explainability of the detected anomalies through counterfactuals. Our experimental evaluation on the UCR Time Series Anomaly archive demonstrates that TimeVQVAE-AD significantly surpasses the existing methods in terms of detection accuracy and explainability.
Air-Decoding: Attribute Distribution Reconstruction for Decoding-Time Controllable Text Generation
Oct 24, 2023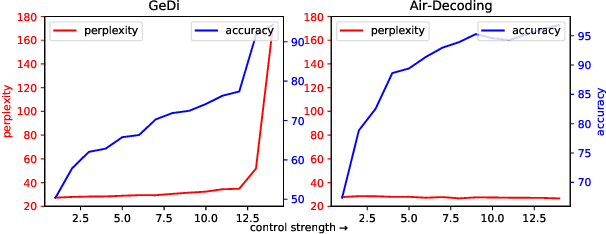
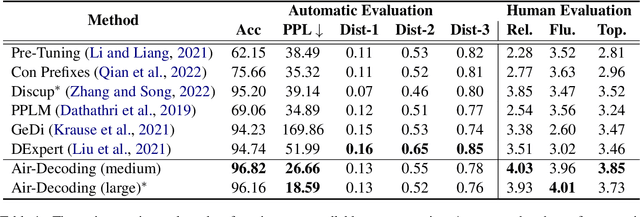
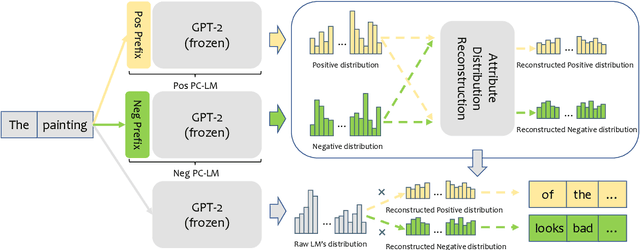
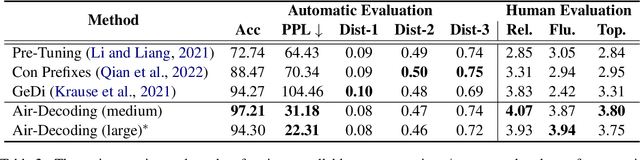
Controllable text generation (CTG) aims to generate text with desired attributes, and decoding-time-based methods have shown promising performance on this task. However, in this paper, we identify the phenomenon of Attribute Collapse for the first time. It causes the fluency of generated text to rapidly decrease when the control strength exceeds a critical value, rendering the text completely unusable. This limitation hinders the effectiveness of decoding methods in achieving high levels of controllability. To address this problem, we propose a novel lightweight decoding framework named Air-Decoding. Its main idea is reconstructing the attribute distributions to balance the weights between attribute words and non-attribute words to generate more fluent text. Specifically, we train prefixes by prefix-tuning to obtain attribute distributions. Then we design a novel attribute distribution reconstruction method to balance the obtained distributions and use the reconstructed distributions to guide language models for generation, effectively avoiding the issue of Attribute Collapse. Experiments on multiple CTG tasks prove that our method achieves a new state-of-the-art control performance.
Adaptive Control of Euler-Lagrange Systems under Time-varying State Constraints without a Priori Bounded Uncertainty
Oct 31, 2023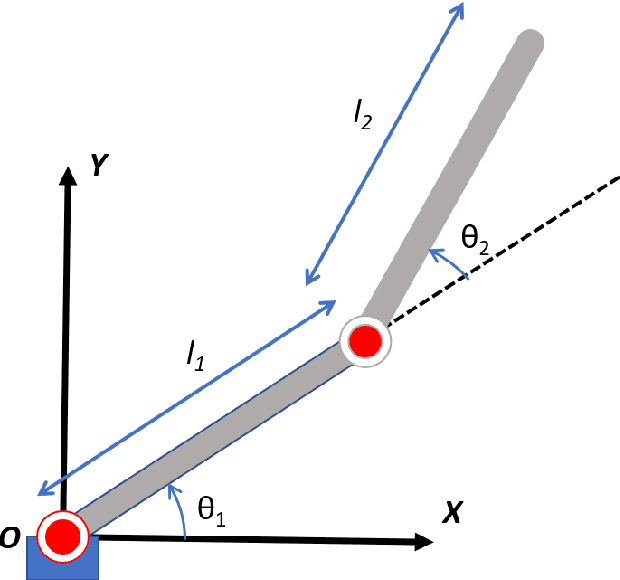
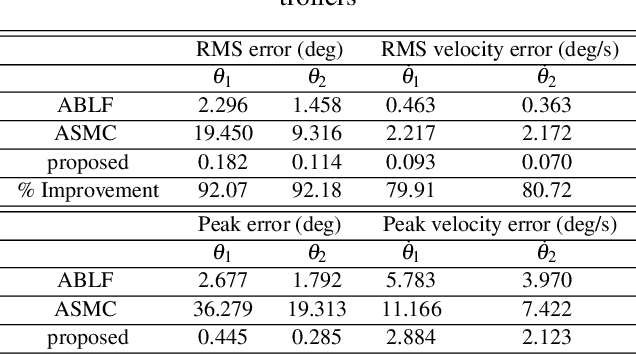
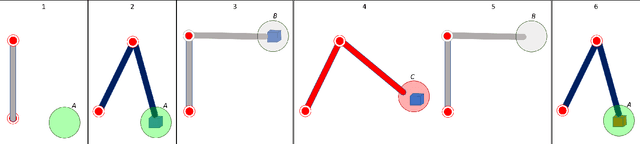
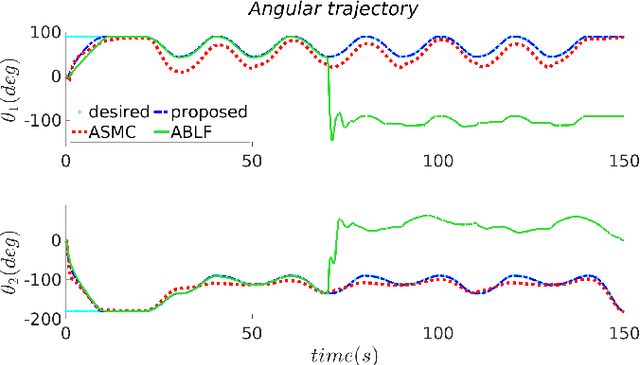
In this article, a novel adaptive controller is designed for Euler-Lagrangian systems under predefined time-varying state constraints. The proposed controller could achieve this objective without a priori knowledge of system parameters and, crucially, of state-dependent uncertainties. The closed-loop stability is verified using the Lyapunov method, while the overall efficacy of the proposed scheme is verified using a simulated robotic arm compared to the state of the art.
From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation
Nov 03, 2023In medical image segmentation, domain generalization poses a significant challenge due to domain shifts caused by variations in data acquisition devices and other factors. These shifts are particularly pronounced in the most common scenario, which involves only single-source domain data due to privacy concerns. To address this, we draw inspiration from the self-supervised learning paradigm that effectively discourages overfitting to the source domain. We propose the Denoising Y-Net (DeY-Net), a novel approach incorporating an auxiliary denoising decoder into the basic U-Net architecture. The auxiliary decoder aims to perform denoising training, augmenting the domain-invariant representation that facilitates domain generalization. Furthermore, this paradigm provides the potential to utilize unlabeled data. Building upon denoising training, we propose Denoising Test Time Adaptation (DeTTA) that further: (i) adapts the model to the target domain in a sample-wise manner, and (ii) adapts to the noise-corrupted input. Extensive experiments conducted on widely-adopted liver segmentation benchmarks demonstrate significant domain generalization improvements over our baseline and state-of-the-art results compared to other methods. Code is available at https://github.com/WenRuxue/DeTTA.
Poster: Real-Time Object Substitution for Mobile Diminished Reality with Edge Computing
Oct 23, 2023Diminished Reality (DR) is considered as the conceptual counterpart to Augmented Reality (AR), and has recently gained increasing attention from both industry and academia. Unlike AR which adds virtual objects to the real world, DR allows users to remove physical content from the real world. When combined with object replacement technology, it presents an further exciting avenue for exploration within the metaverse. Although a few researches have been conducted on the intersection of object substitution and DR, there is no real-time object substitution for mobile diminished reality architecture with high quality. In this paper, we propose an end-to-end architecture to facilitate immersive and real-time scene construction for mobile devices with edge computing.
Time and Frequency Offset Estimation and Intercarrier Interference Cancellation for AFDM Systems
Oct 19, 2023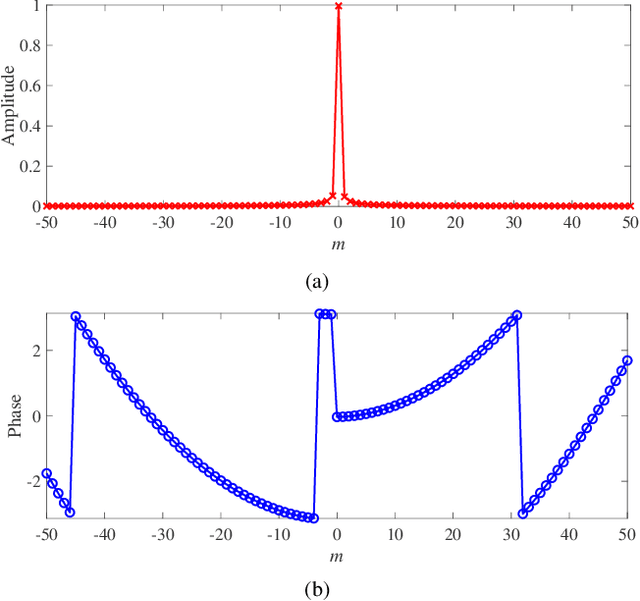

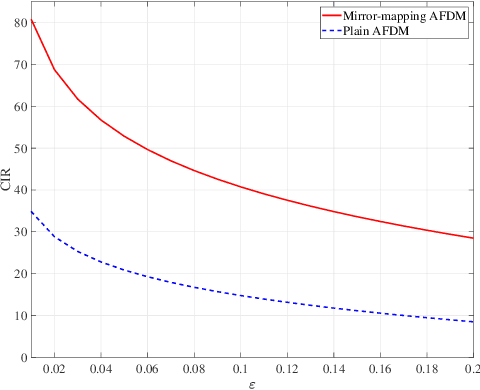
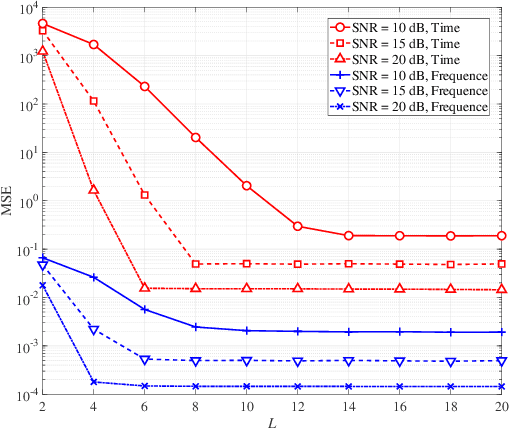
Affine frequency division multiplexing (AFDM) is an emerging multicarrier waveform that offers a potential solution for achieving reliable communication for time-varying channels. This paper proposes two maximum likelihood (ML) estimators of symbol time offset and carrier frequency offset for AFDM systems. The joint ML estimator evaluates the arrival time and frequency offset by comparing the correlations of samples. Moreover, we propose the stepwise ML estimator to reduce the complexity. The proposed estimators exploit the redundant information contained within the chirp-periodic prefix inherent in AFDM symbols, thus dispensing with any additional pilots. To further mitigate the intercarrier interference resulting from the residual frequency offset, we design a mirror-mappingbased scheme for AFDM systems. Numerical results verify the effectiveness of the proposed time and frequency offset estimation criteria and the mirror-mapping-based modulation for AFDM systems.